정글 탈출 후 제대로된 공부와 이력서 쓰기 2일차.
2. Linked List에 대해 설명해주세요.
LinkedList는 ArrayList와 자주 비교되곤 한다.
일단 두개를 비교하기 전에, ArrayList와 Array를 조금 비교해보자.
Array, 배열
- 사이즈, 초기화시 고정 || 변경 불가
- 초기화시, 메모리에 즉시 할당되어 속도 빠름
- 다차원 생성 가능
ArrayList, 리스트
- 사이즈, 초기화시 따로 지정 x ( 가변 )
- 데이터 추가시 메모리를 재할당 하여 Array보다 느림
- 다차원 생성 불가능
일단, arraylist가 array보다 속도가 느린데, 이 이유를 알고 넘어가는게 좋을 것 같다.
- arraylist는 관리하기 위해선 추상화 되어진 메서드들을 사용해야 한다.
- 이미 다 구현이 되어져 있는 것들이고, 이 행동은 사실 함수를 호출하는 작업이기 때문에, 메모리 자체를 직접 들어가서 수정하는 array보다 느릴 수밖에 없다.
- 공간 체크를 위한 에러 방지
- ArrayList는 get만 호출하더라도, 에러체크를 위해 또 다른 함수를 호출하는 식이지만, array는 사용자가 직접 관리해줘야 한다.
- 이런 많은 이유가 존재한다.
근데, ArrayList도 연속적인 배열이기 때문에, 상대적으로 느린거지 이제 주인공인 LinkedList보다 훨씬 빠르다. 왜그럴까? 그리고 왜 쓸까?
이제 LinkedList가 어떤식으로 되어져있는지 봐보자.
노드라는 개념에 대해서 알아야 한다.
헤더를 기준으로, 다음 주소를 가리키는 필드를 이용해 각 노드들을 연결해서 리스트처럼 쓰게 된다.
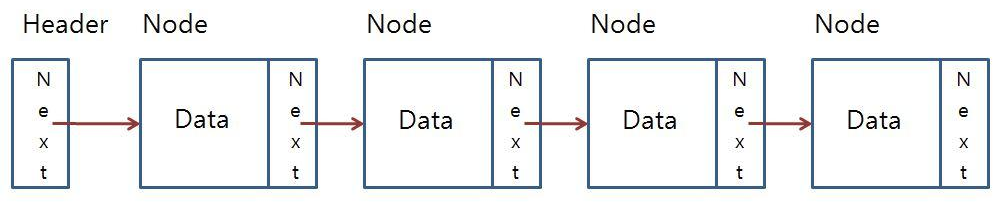
그림이 너무 이뻐서 가져와봤다.
이렇게 쓰게 된다면, 필드를 찾아갈때, next를 계속 확인해서 찾아가야 한다.
ArrayList와 Array의 가장 큰 장점은 내가 찾고자 하는 데이터의 위치만 알면, 복잡도가 O(1)이 되는 것이다. 근데, LinkedList의 경우에는 숫자 필드를 저장하면 되겠지만, 이건 오산이다. 왜냐하면, 결국 주소를 저장하는 것이기 때문에, 정확한 메모리상 위치를 알 수 없다. 그렇기에 필요 없다. (필요한 경우가 있을 순 있음, 찾고자 하는 데이터가 몇번쨰에 있는지가 중요한 데이터라면?)
결국 탐색에 있어서는 최악의 경우 n번의 연산이 진행되는데, 왜 쓸까?
중요한것은 화살표다. 다음 주소를 저장한다는 화살표
화살표만 있으면, 노드의 다음주소를 알 수 있고, 그리고 LinkedList는 순서가 중요하지 않기 때문에, (순서를 안다면 나라면 ArrayList를 쓸듯) 결국 다른곳에서 강점을 찾아야 하는게, 그게 삽입과 삭제이다.
만약 ArrayList의 경우라면, 순서가 보장되야 하기 때문에, 또한 공간에 대한 단편화도 발생하면 안되기 때문에 중간 노드에 삽입 또는 삭제했을 시에 재정렬이 필요하다. 히지만, LinkedList는 화살표만 중간에 이음매로 한개만 추가해준다면 해결되기 때문에 삽입에서 탐색과 삽입 또는 삭제에서 탐색과 삭제만 해주면 된다.
그렇기에, LinkedList의 가장 큰 강점은, 중간노드의 삭제, 삽입이고, 쓰이는 이유는 정렬된 데이터의 변동이 자주 일어나는 경우가 될 것 같다.
탐색도 O(n), 삽입 및 삭제도 탐색 후 삭제하는 과정이니 T(n) = n+c이기 때문에 O(n)이 된다.
하지만, ArrayList는 탐색에서 O(1)이 나오지만, 삽입 삭제에서 O(n^2)가 되기 때문에 이점을 고려해서 자료구조를 선정해야 한다.
최종적으로LinkedList는 노드라는 개념으로, 각 데이터들은 주소에 의해 관리되고, 정렬된 데이터가 자주 삽입 및 삭제가 되는 경우에 쓰면 좋은 자료구조이다.
Redis 멀티스레드 프로그래밍
문제
이 단계에서는 여러 클라이언트를 동시에 처리하는 기능을 추가합니다.
같은 클라이언트의 여러 명령을 처리하는 것뿐 아니라, Redis 서버는 여러 클라이언트를 한 번에 처리하도록 설계되어 있습니다.
이를 구현하려면 스레드를 사용하거나, 더 도전적으로는 공식 Redis 구현처럼 이벤트 루프를 사용할 수 있습니다.
테스트
서버
$ ./your_program.sh클라이언트
$ redis-cli PING
$ redis-cli PING해결과정
멀티스레드는 하나의 프로세스에 실행단위가 여러개인것을 얘기한다. 그러면, 해결을 하기 위해선 일반적인 요청보다 하나에 집중하여서 처리해야 한다. 그건, 하나의 요청이 끝나는 라인인 \n을 기준으로 쭉 받아야 하는 것이다.
그렇기 때문에, 우리는 while문 안에서 읽는 데이터가 \n인 경우에 끊으면 된다. 우리는 이전단계에서 \n단위로 나누었기 때문에, 크게 고려할 사항이 없었다. 우연히 멀티스레드 프로그래밍이 된 것이다.
이제 어떻게 쓰는지를 조금 더 고민해보면, 생성된 fd기준으로 해당 fd로 작업을 나누면 된다.
void handleResponse(int client_fd){
std::string acc;
char buffer[100];
const std::string PONG = "+PONG\r\n";
while(true){
ssize_t n = read(client_fd, buffer, sizeof(buffer));
if (n < 0) { perror("read"); break; }
if (n == 0) break; // 연결 종료
acc.append(buffer, n);
size_t pos;
while((pos = acc.find('\n')) != std::string::npos) {
std::string line = acc.substr(0, pos);
acc.erase(0, pos+1);
if(!line.empty() && line.back() == '\r') {
line.pop_back();
}
if(line == "PING") {
send(client_fd, PONG.c_str(), PONG.size(), 0);
}
}
}
close(client_fd);
}
...
std::thread client_thread(handleResponse, client_fd);
client_thread.detach();
...스레드를 생성하는 코드는 다음과 같다.
std::thread client_thread(handleResponse, client_fd);
스레드를 생성할때, 인자로 넘기는 함수와 함수의 매개변수를 다음과 같이 쓴다.
client_thread.detach();
생성한 스레드를 실행시키는 코드이다.
실행시키는 코드는 2가지가 있는데 detach()와 join()두개를 비교해보자.
- detach()
- 실행 시킨 후, 잊어버린다.
- 백그라운드에서 계속 실행중인것이다.
- join()
- 스레드가 종료될 때까지 메인스레드가 기다린다.
사실 두개다 뭘 써도 상관이 없다.
그리고, 하나 더 내가 오해했던 부분이 있다.
A, B가 요청을 하면 이렇게 받을 것 같았다.
A: PI
B: PI
A: NG\n
B: NG\n
와 같이 꼬이는 경우가 있어서, PIPING\nNG\n 이것도 고려해야 할 줄 알았는데, 알고보니 이건 TCP 특성으로, 연결은 fd기준으로 데이터 스트림을 보내기 때문에, 우리는 이점은 고려할 필요가 없다. 어차피 보장된다.
그리고, TCP는 위에서 얘끼했지만, 스트림 형식으로 보내기때문에, 전부다 받기 전까지 누적해서 파싱해야 한다.
여기에 더해서, 지금 딱 보면 뭔가 Busy Waiting인것 같아 보인다.
busy waiting은 스레드가 다음 요청까지 계속 기다리면서 cpu를 점유하는 것인데, 사실 busy waiting은 아니고, read시스템콜이 blocking system call이다.
다시 말해 다음과 같은 특성이 있다.
- 데이터가 도착할때까지, 커널이 스레드를 재워놓는다.
- 데이터가 들어오면, 깨워서 처리한다.
- 그렇기 때문에, 커널에서 대기중인 상태고, cpu는 다른일을 처리하는 것이고, 데이터가 들어오지 않는이상 잠들어있는 상태인 것이다.
만약, read를 쓰지 않는 경우도 있을것인데, 이떈 어떻게 해결할 것인가?
일단, pintos에서 했던 방식은 공유자원을 건드리는 경우를 생각했었다.
lock이라는 변수를 하나 두고, 해당 lock변수만큼 스레드가 lock을 전부 차지하고 있으면, lock을 차지하려는 다른 스레드들은 잠재우는 방식으로 구현했었다.
코드는 다시 봐야 알 것 같고, 추후 실습을 다시하고, 블로그도 제대로 정리해서 다시 게시할 예정이다.
그리고, 사실 accept()도 마찬가지로, blocking system call이니까, 바쁜대기로 돌입하는게 아니다.
- GPT 한테 궁굼한거 질문한 내용
2. 그럼 “락 + Lazy Loading”은 언제 쓰는 전략이냐?
이건 shared한 리소스에 대해 병렬 안전성을 유지할 때쓰는 패턴이야.
예를 들어:
또는 일반적인 락 기반:std::once_flag flag; std::string config; void loadConfigOnce() { std::call_once(flag, [](){ config = readFile("config.json"); // 💡 이 부분은 한 번만 실행됨 }); }
이런 패턴은 “공유 자원에 대해 한 번만 초기화”std::mutex m; std::string config; bool loaded = false; void loadConfig() { std::lock_guard<std::mutex> lock(m); if (!loaded) { config = readFile("config.json"); loaded = true; } }Q. read() 대신 lock + lazy-loading으로 처리해야 하나요?
상황 설명 단일 소켓에서 데이터를 읽는다 read()가 blocking이면 필요 없음 여러 클라이언트에서 동시에 접근할 수 있는 shared 데이터 ✅ 락 + lazy-loading 고려 대상 read()가 non-blocking인데 CPU를 아끼고 싶다 ✅ select(), poll(), epoll() 등을 써야 함 초기화가 느리고, 여러 스레드가 초기화 시도할 수 있다 ✅ std::once_flag / double-checked locking 필요
개념 언제 씀? 주 목적 read() 네트워크 소켓에서 데이터 읽기 blocking이면 대기, non-blocking이면 EAGAIN 락 (std::mutex) 여러 스레드가 같은 데이터에 접근 경쟁 조건 방지 lazy-loading + 락 리소스를 한 번만 초기화하고 싶을 때 ex) config 파일, DB connection pool 등 select() / poll() / epoll() non-blocking I/O + 이벤트 기반 처리 CPU 효율적 사용
