Word2Vec
Word2Vec은 단어의 의미를 수치화하여 단어 벡터 간의 유의미한 유사도를 계산하는 대표적인 방법이다. (published in 2013)
0. Word Embedding이란?
NLP(자연어처리)분야에서, word embedding은 텍스트를 분석할 때 주로 사용된다. 여기서의 가정은, 벡터 공간에서 더 가까울수록, 의미상으로도 더 가깝다라고 기대할 수 있다는 것이다. 이는 language modeling과 feature learning을 통해 수행될 수 있으며, 이때, 단어나 문장은 실수로 이루어진 벡터로 mapped된다. 이 과정에서 인공 신경망, 차원 축소 등의 개념이 포함된다.
1. Sparse Representation (희소 표현)
행렬에서 '희소'하다는 것은, 값의 대부분이 0으로 표현되는 것을 의미한다. 즉, word embedding에서 희소표현은, 표현하고자 하는 단어의 인덱스값=1, 나머지=0으로 표현되는 원-핫 벡터와 같은 것을 의미한다. 즉, 고차원에 각 차원을 분리하는 방법이다. 이는 단어 벡터간 유사성을 표현할 수 없다는 단점이 있다. 따라서, Distributed Representation (분산 표현)을 통해 단어의 의미를 다차원 공간에 벡터화하여 이 문제를 해결할 수 있다.
2. Distributed Representation (분산 표현)
'비슷한 문맥에서 등장하는 단어들은 비슷한 의미를 가진다'라는 가정 하에 만들진 방법이다. 이 가정을 통해 텍스트를 학습하고, 벡터의 여러 차원(상대적으로 저차원)에 단어의 의미를 분산하여 표현한다.
예를 들어, 텍스트 데이터에 단어가 10000개 있고, '고양이'라는 단어의 인덱스가 9였다면, 고양이를 표현하는 원-핫 벡터는 "고양이 = [0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 ....중략 ... 0]" 이므로, 값 1 뒤에 9900개의 0을 가지는 벡터가 된다.
하지만, Word2Vec을 활용하여 embedding을 진행하면, 차원의 수를 사용자가 설정하게 된다. 즉, "고양이 [0.2 0.5 0.2 ...중략... 0.3]" 과 같이 표현된다. 즉, 저차원에 단어의 의미를 여러 차원에 '분산'하는 것을 의미한다. 이를 통해 단어 벡터 간 유사도를 계산할 수 있고, 이를 활용한 것이 Word2Vec이다.
3. Word2Vec의 학습 방식
(1) CBOW(Continuous Bag of Words)
'주변'의 단어(=context word)를 입력으로 '중간'에 있는 단어(=center word)들을 예측하는 방법이다. 예를 들어, "The pretty girl walked through the forest" 라는 문장이 있을 때, ['The', 'pretty', 'girl', 'through', 'the', 'forest']라는 주변 단어로부터, 중간 단어인 'walked'를 예측하는 것이 CBOW이다. 이때, 앞뒤로 몇 개의 단어를 볼 것인지의 범위를 window라고 한다. 예를 들어, 윈도우 크기가 3이면, 예측하고자 하는 중심 단어의 앞 3단어와 뒷 3단어를 입력으로 사용한다. 참고하는 총 단어의 개수는 3*2=6개이다.
window size를 정하고 나서, sliding window 방법을 통해 window를 옆으로 움직여서 주변 단어, 중심 단어를 변경해가며 데이터셋을 만든다. Word2Vec에서 입력은 모두 [0,0,0,1,0,0] 형태와 같은 원-핫 벡터가 되어야한다.
Input Layer(주변 단어들의 one-hot vector) -> Projection Layer(activation function X) -> Output Layer(예측하고자 하는 중간 단어의 one-hot vector) : hidden layer가 1개
(projection layer는 투사층이다.)
CBOW의 메커니즘
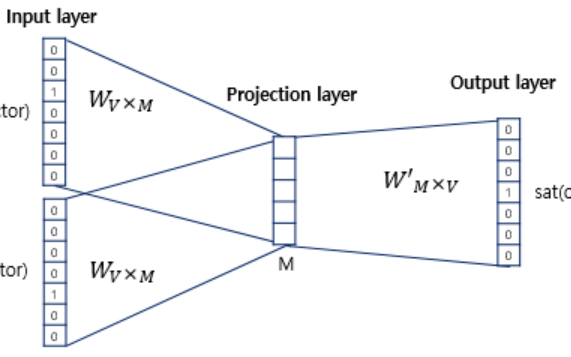
(단어 집합의 크기가 V, 투사층의 크기가 M, 가중치는 W이다.)
embedding하고 난 벡터의 차원이 투사층의 크기와 같다. 어떤 물체가 틀을 통과하고 나면 그 틀의 사이즈에 맞는 모양이 되는 것처럼 임베딩을 거쳤을 때 투사층의 크기 M과 같아진다고 이해하면 될듯하다(?)
Input Layer와 Projection Layer사이의 가중치는 V x M 행렬이고, Projection Layer와 Output Layer사이의 가중치는 M x V 행렬이다. (주의! 둘이 transpose matrix은 아니다)
처음 이 가중치들은 랜덤값을 가지게 되고, 이들은 결국 학습해야할 대상이므로 CBOW는 이 둘을 계속해서 학습해가는 구조를 가지고 있다. 최종 목표는 이를 학습하여 주변 단어를 이용해서 중심 단어를 더 정확하게 맞추는 것이다.
수학으로 들어가보자...
Input Layer에서 입력값은 one-hot vector이므로, i번째 인덱스에 1을 가지고, 나머지는 0을 가지는 벡터이다. 따라서, 이를 가중치 W 행렬과 곱하였을 때, 0으로 인해 나머지 값들이 날라가면서 결국 W 행렬의 i번째 항을 그대로 읽어오는 것과 동일해진다. (lookup table)
각각의 입력값과 각각의 가중치를 곱하여(lookup하여) 생성된 값은 projection layer에서 만나는데, 이 layer에서 입력 벡터들의 평균을 구하게 된다. 이 평균 벡터와 다음 가중치 W'행렬을 곱하여 입력 벡터의 차원과 동일한 결과값 벡터가 생성된다. 이는 softmax함수를 지나서 0과 1 사이의 실수로 결과값 벡터가 구성된다. 이때, loss function과 cross-entropy함수가 사용된다.
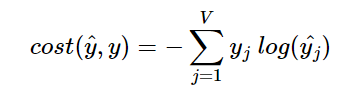
최종적으로 W, W'를 학습하는 것이 목표이므로, back propagation을 통해 이들을 학습한다.
(2) Skip-Gram
'중간'의 단어를 입력으로 '주변'에 있는 단어들을 예측하는 방법이다.
Input Layer(중간 단어의 one-hot vector) -> Projection Layer(activation function X) -> Output Layer(예측하고자 하는 주변 단어들의 one-hot vector) : hidden layer가 1개
전반적으로 Skip-Gram이 CBOW보다 성능이 좋다. (by 여러 논문)
