Facial Key Points Detection using Deep Convolutional Neural Network - NaimishNet 논문 요약
I. INTRODUCTION
- 얼굴 이미지가 주어졌을 때, FKPs(Facial Key Points)의 이미지 픽셀 공간에서 (x,y)의 실제 좌푯값을 찾는 것이 FKPs detection의 가장 큰 문제이다.
- 사람마다 얼굴 특징이 다르고, 같은 사람이어도 표정이 다양하며, 빛 조건, 바라보는 각도 등에 따라서 얼굴 이미지가 달라질 수 있기 때문에 FKPs detection은 더욱 해결하기 어렵다.
- 지난 몇 년간은 DCNN(Deep convolutional neural network)을 주로 적용하여 FKPs detection을 진행하였다.
- 이 논문에서는 LeNet을 기반으로 한, DCNN 구조를 지닌 NaimishNet을 처음으로 제안한다.
II. NAIMISHNET ARCHITECTURE
논문에는 모델을 최종 구성하기까지의 여러 시도들이 나오지만 최종으로 선택된 것이 아니므로 여기서는 생략
- 이 논문의 목표는 performance와 generalizability을 극대화시킴과 동시에 training time을 감소시키는 것이다. 따라서 디자인, 구조를 선택할 때 이 부분을 고려하였다고 한다.
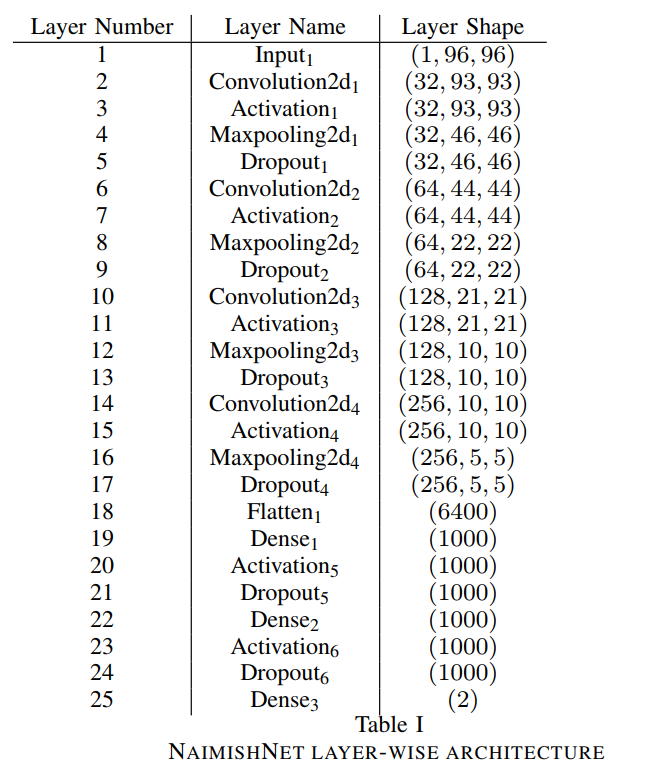
4개의 convolution2d layers, 4개의 maxpooling2d layers, 3개의 dense layers와 layer사이 사이에 끼워져있는 dropout, activation layers로 구성된다.
위와 같은 layer 개수를 사용한 이유는, activation function으로 사용한 ELU가 5개 이상의 layer에서 좋은 성능을 내기 때문이다.
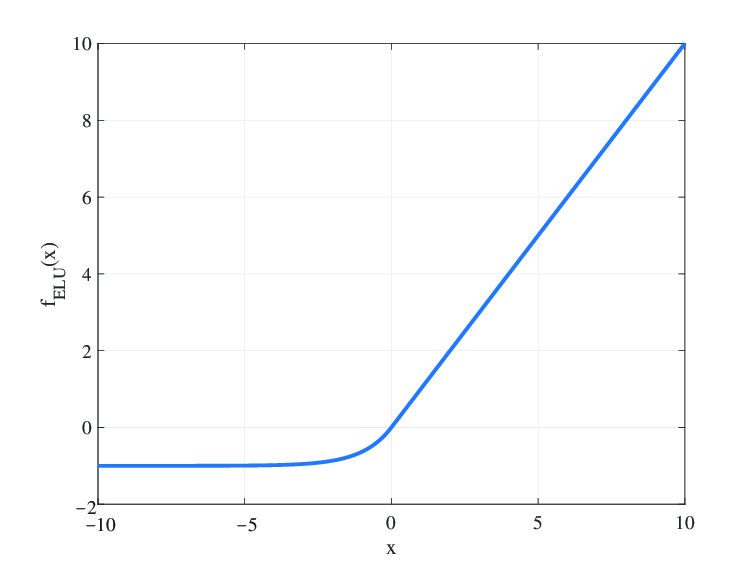
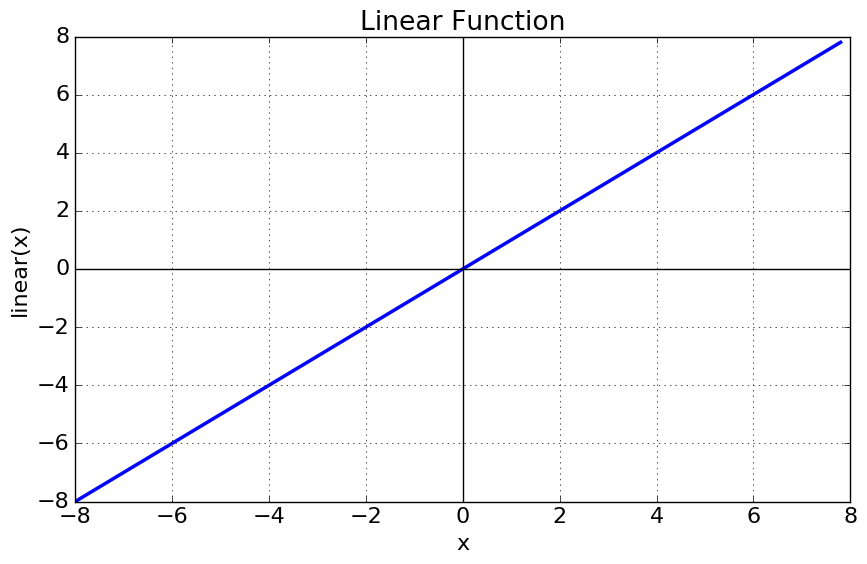
- Activation1~5까지는 ELUs(Exponential Linear Units)를 사용하였고, Activation6은 Linear Activation Function을 사용하였다.
-
Dropout probability는 Dropout1에서 6으로 감에 따라, 즉 네트워크가 깊어짐에 따라 0.1씩 증가하였다. (0.1->0.6)
-
learning rate를 0.001로 설정한 Adam optimizer을 사용하였다.
위의 세 가지 조건을 선택한 이유는 training time을 감소시키고 성능과 일반화 능력을 향상시키기 위해서이다.
-
Maxpooling2d 1~4는 (2,2)의 pool shape을 사용했고, overlapping strides와 zero padding을 사용하지 않았다.
-
Convolution2d 1~4도 마찬가지로 zero padding을 사용하지 않았고, random numbers을 사용하여 가중치를 초기화하였다. 아래 사진은 filter의 개수와 사이즈를 알려준다.

-
parameter 개수(700만개 이상)와 GPU 메모리 제한을 고려하였을 때, batch size = 128 이 이상적임을 밝혀냈다.
-
Dense1~3은 fully connected layers이고, Glorot uniform initialization을 이용하여 가중치를 초기화하였다.
-
NaimishNet 구조 사진에서 Flatten은 3D 입력을 1D 출력으로 변환해주는 것을 의미한다.
III. EXPERIMENTS
-
Data Augmentation
-
Data Pre-processing
이미지 픽셀을 [0,1]로 normalized시키고, train target도 zero-centered를 유지하기 위해 [-1,1]로 재구성하였다. -
Pre-training Analysis
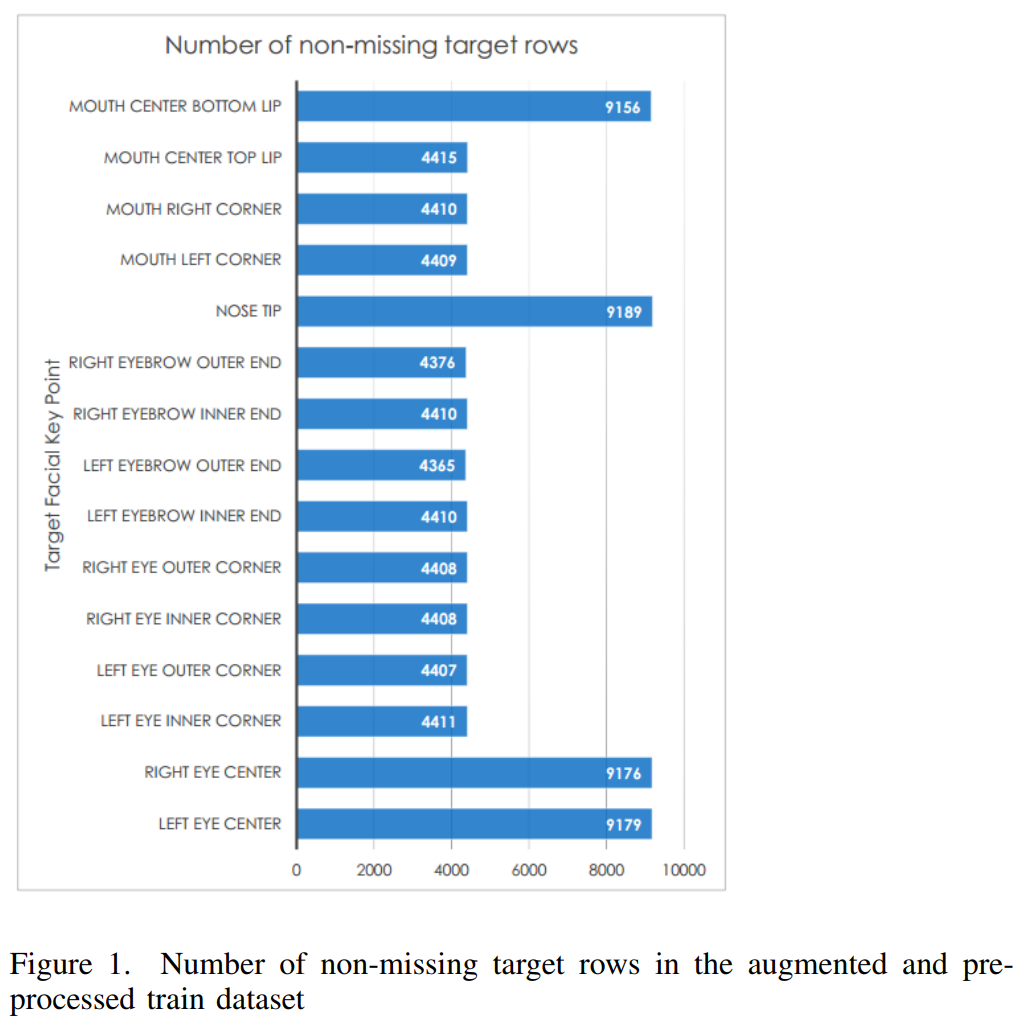
아래 사진을 보면, 다른 FKPs에 대하여 non-missing target rows의 개수가 달라지기 때문에 15개의 NaimishNet models를 만들었다.
-
Training
batch size = 128
maximum number of epochs = 300
ESC(Early Stopping Callback)과 MCC(Model Checkpoint Callback) 활용 -
Evaluation
각 model에 대해서, 가장 잘한 모델의 가중치를 reload하고, test 데이터를 예측하고, 예측한 것을 저장한다.
IV. RESULTS

blue points(실제 point)와 red points(예측된 point)가 매우 가깝게 찍힌 것을 볼 수 있다.
V. CONCLUSION
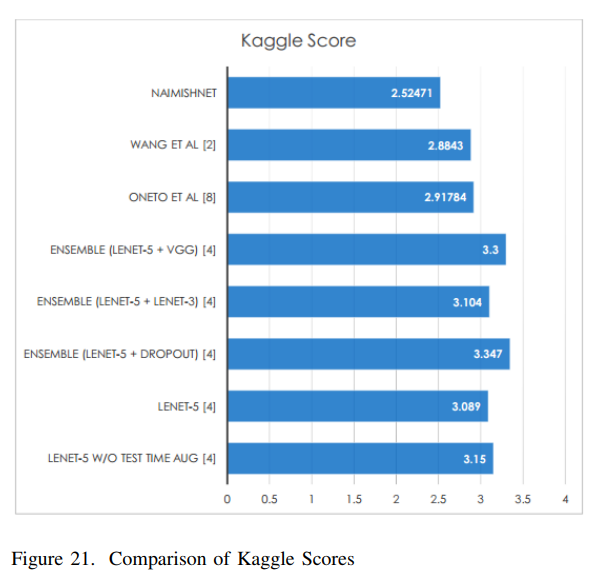
LeNet을 기반으로 한 architectures가 FKPs Detection에 성공적이라는 것이 증명되었다. NaimishNet뿐만 아니라, LeNet기반의 다른 architecture인 ONETO et al, Longpre et al, 등도 좋은 성능을 보이는 것을 확인할 수 있다.
VI. FUTURE SCOPE
다른 초기화 방법, activation functions, 필터의 개수와 사이즈, 레이어 개수, LeNet 대신 VGGNet의 사용 등으로 후속 연구를 진행해볼 수 있을 것이다.
출처: https://github.com/ParthaPratimBanik/Facial-Keypoint-Detection-Udacity-PPB 에서 언급한 https://arxiv.org/pdf/1710.00977.pdf 논문
