패션 MNIST
- tensorflow의 keras에서 불러오기
- 10개의 샘플을 이미지로 확인해보기
import matplotlib.pyplot as plt
fig, axs = plt.subplots(1,10,figsize=(10,10))
for i in range(10):
axs[i].imshow(train_input[i], cmap='gray_r')
axs[i].axis('off')
plt.show()
Logistic Regression으로 분류
- 255.0으로 나누어 0~1 사이의 값을 가지도록 전처리를 진행한 다음, 여기서 이용할 확률적 경사 하강법(샘플을 하나씩 꺼내서 훈련하는) SGDClassifier는 1차원 입력만을 받기 때문에 reshape메서드 이용
- 원본데이터가 28x28 사이즈이기 때문에 이를 곱하기
- reshape메서드의 첫 번째 차원이 -1인 경우: 원래 배열의 길이와 남은 차원으로부터 추정하겠다는 뜻
여기서는 샘플의 개수를 의미할 듯
train_scaled = train_input / 255.0
train_scaled = train_scaled.reshape(-1, 28*28)
교차검증과 SGDClassifier를 활용하였을 때 스코어는 0.8196 정도로 나왔다.

인공신경망
- tensorflow: 구글이 오픈소스로 공개한 deep learning library
- dense layer 만들어보기
-> 10: 뉴런 개수
-> softmax activation function 지정
-> 입력크기는 784(=2828) : 아까 2828 사이즈로 reshape했기 때문에 - 이진분류에는 binary_crossentropy를, 다중분류에는 categorical_crossentropy 지정
- fit()메서드를 통해 훈련
- evaluate()메서드를 통해 모델의 성능 평가
dense = keras.layers.Dense(10, activation ='softmax', input_shape=(784,))
model = keras.Sequential(dense)
model.compile(loss='sparse_categorical_crossentropy', metrics='accuracy')
model.fit(train_scaled, train_target, epochs=5)
model.evaluate(val_scaled, val_target)심층 신경망
-
분류 문제의 hidden layer의 활성화 함수로 sigmoid, ReLU 등 다양한 함수를 사용하지만, 회귀는 활성화 함수를 사용할 필요가 없다.
-
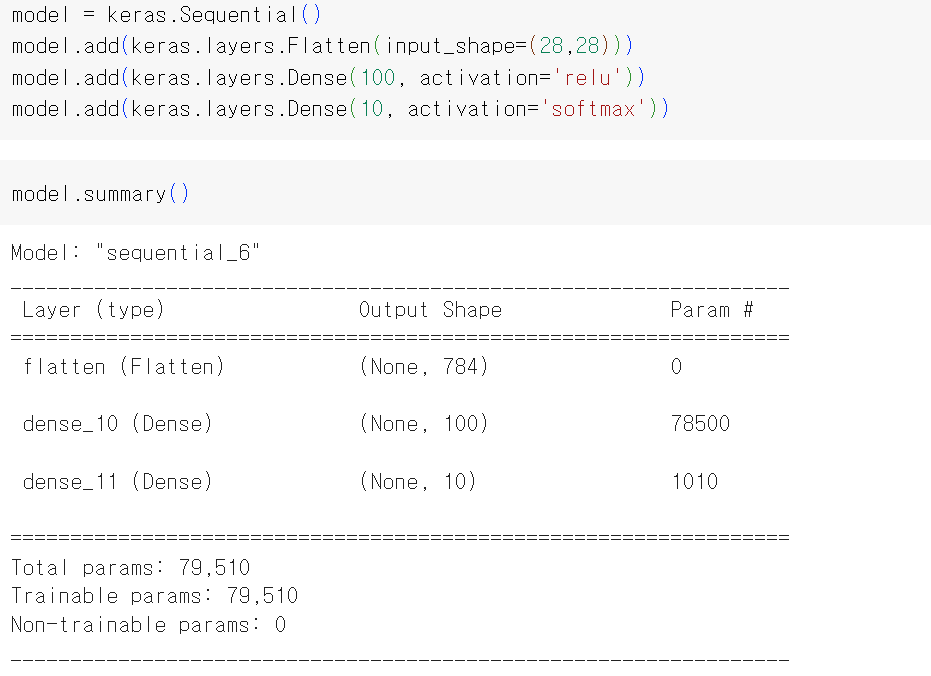
hidden layer(dense_10)-> output layer(dense_11)순으로 만들어보기
-
hidden layer의 뉴런 개수를 100개로 지정-> hidden layer의 output shape이 (None, 100)
-
Flatten층 = reshape()메서드와 같은 역할, 배치 차원을 제외하고 나머지 입력 차원을 1차원으로 펼쳐줌
-
compile, fit, evaluate부분은 위의 코드와 동일
-
optimizer: 다양한 종류의 경사 하강법 알고리즘
- RMSprop
- momentum optimization
- Adagrad
- Adam : momentum optimization과 RMSprop의 장점을 접목
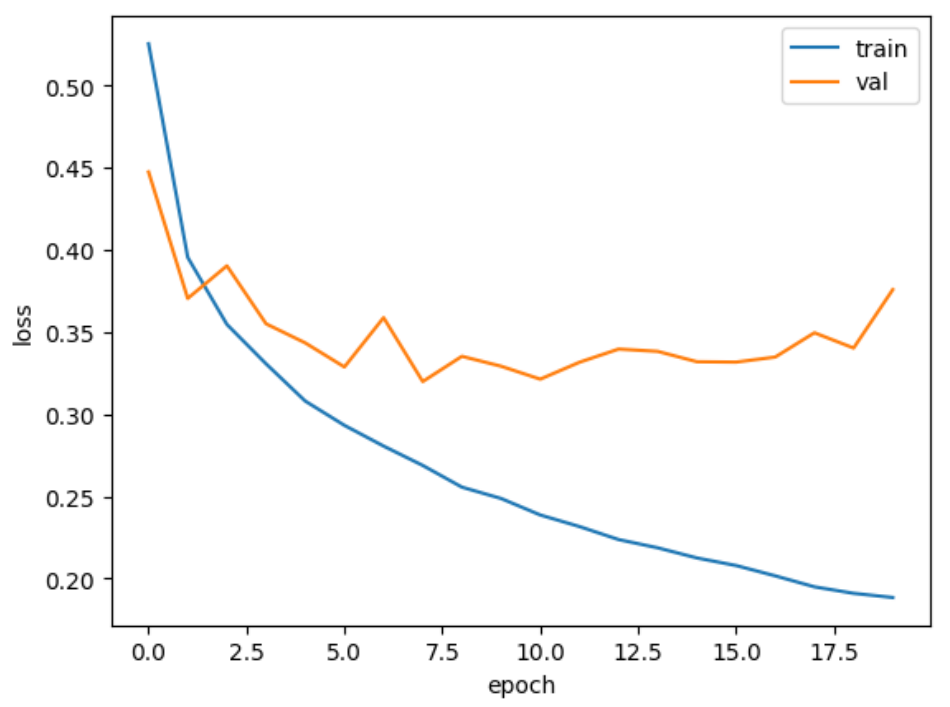
손실 곡선
- history에 model.fit()한 결과를 저장
- verbose=0 : 훈련과정 출력 x
- verbose=1 : 에포크마다 진행막대+손실 등의 지표 출력
- verbose=2 : 진행막대 제외 출력
- history 객체에는 history 딕셔너리 존재(아래는 4개의 키, 검증 손실 및 정확도까지 포함)
- loss
- accuracy
- val_loss
- val_accuracy
history = model.fit(train_scaled, train_target, epochs=20, verbose=0,
validation_data=(val_scaled, val_target))다음은 Adam optimizer를 적용하고 훈련시켰을 때의 train, validation loss 그래프
model = model_fn()
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics='accuracy')
history = model.fit(train_scaled, train_target, epochs=20, verbose=0,
validation_data=(val_scaled, val_target))
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.xlabel('epoch')
plt.ylabel('loss')
plt.legend(['train', 'val'])
plt.show()참고: model_fn()은 모델의 구조를 형성하고 모델을 반환하는 함수
Dropout
- 대표적인 규제방법
- 훈련과정에서 layer에 있는 일뷰 뉴런의 출력을 0으로 만들어서 overfitting을 막음 but 전체 출력 배열의 크기를 바꾸지는 않음
- dropout layer는 모델 파라미터 x, 입력과 출력의 크기가 같음
model = model_fn(keras.layers.Dropout(0.3)) # 30% 정도를 드롭아웃모델 저장과 복원
- 첫 번째 방법: 훈련된 모델의 파라미터 저장
model.save_weights('model-weights.h5')# 새로운 모델 만들고 파라미터 읽어서 사용
model = model_fn(keras.layers.Dropout(0.3))
model.load_weights('model-weights.h5')- 두 번째 방법: 모델 구조와 모델 파라미터를 함께 저장
model.save('model-whole.h5')# 바로 사용
model = keras.models.load_model('model-whole.h5')callback
- ModelCheckpoint 콜백: 에포크마다 모델 저장
- save_best_only=True : 가장 낮은 검증점수 만드는 모델 저장
model = model_fn(keras.layers.Dropout(0.3))
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics='accuracy')
checkpoint_cb = keras.callbacks.ModelCheckpoint('best-model.h5', save_best_only=True)
model.fit(train_scaled, train_target, epochs=20, verbose=0,
validation_data=(val_scaled, val_target),
callbacks=[checkpoint_cb])Early stopping
- 과대 적합 시작 전에 훈련을 미리 정지하는 것
- restore_best_weights=True : 가장 낮은 검증 손실을 낸 모델 파라미터로 되돌림
- patience=2 : 2번 연속 검증점수의 향상이 없으면 훈련을 중지
- early_stopping_cb.stopped_epoch 에서 몇 번째 epoch에서 훈련이 중지되었는지 확인 가능
early_stopping_cb = keras.callbacks.EarlyStopping(patience=2, restore_best_weights=True)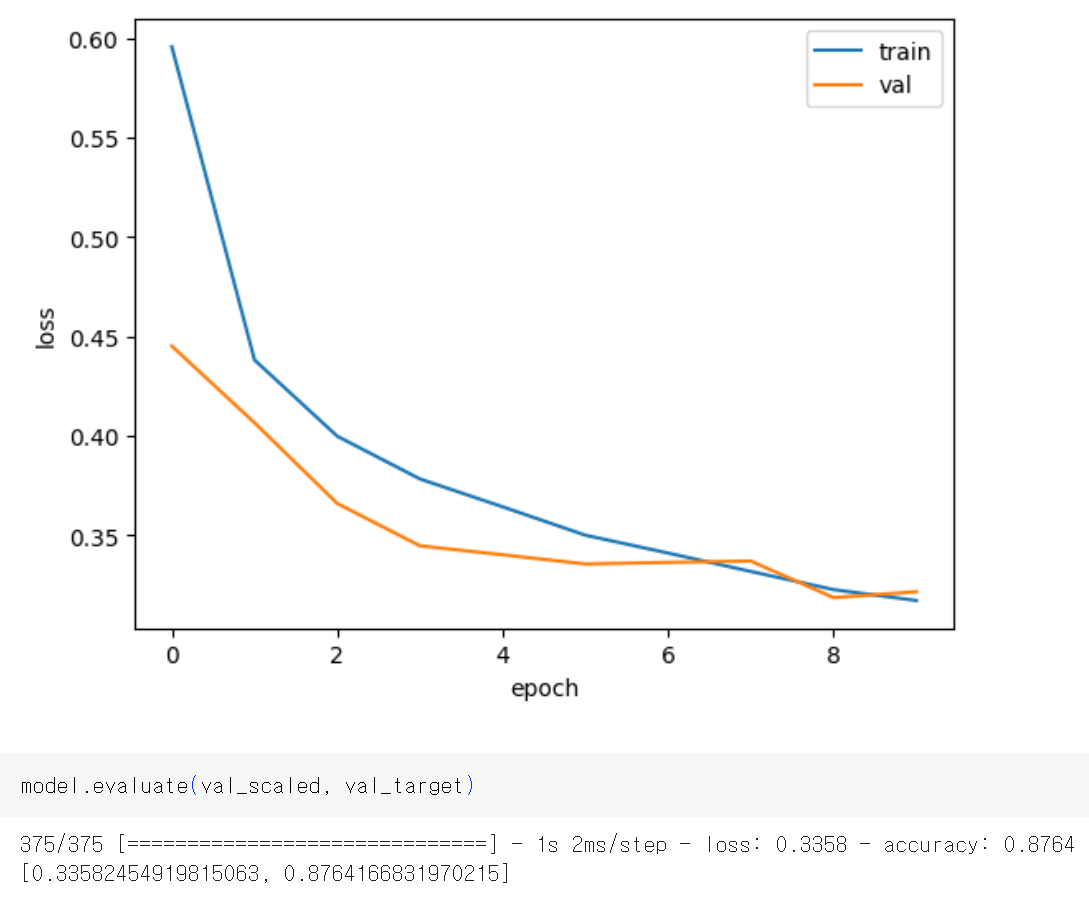
Early stopping을 통해 성능이 훨씬 향상됨!
출처: [혼자공부하는 머신러닝+딥러닝] 의 chapter 7-(1),(2),(3)을 보고 핵심 내용만 정리한 글

^.^