순차 데이터(sequential data)
- 시계열 데이터(time series data)와 같이 순서에 의미가 있는 데이터
- feedforward neural network: 입력데이터의 흐름이 앞으로만 전달되는 신경망
- ex. 완전 연결 신경망, 합성곱 신경망
순환 신경망(Recurrent neural network)
- RNN: 이전 데이터가 신경망 층에 순환되는 구조
- 뉴런의 출력이 다시 자기자신으로 전달됨
- timestep: 이전 샘플에 대한 기억을 가지고 있게 하면서 샘플을 처리하는 한 단계
- cell의 출력 = hidden state
- 활성화함수로 tanh을 많이 사용
- 가중치 = 입력에 곱해지는 가중치 + 이전 타임스텝의 hidden state에 곱해지는 가중치
- 모든 timestep에 사용되는 가중치는 Wh하나
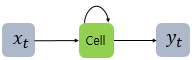
셀의 가중치와 입출력
-
순환층에 있는 첫 번째 뉴런(r1)의 hidden state가 다음 timestep에 재사용될 때 첫 번째 뉴런과 두 번째 뉴런, 세 번째 뉴런에 모두 전달됨
-
만약 입력층의 뉴런이 4개, 순환층에 뉴런이 3개라면
- 입력층과 순환층이 fully connected 되어있다면, 가중치는 4x3=12개
- hidden state를 위한 가중치 Wh는 3x3=9개
- 절편: 3개
- 총 12+9+3 = 24개의 모델 파라미터
-
"I am a boy"라는 문장
- timestep의 크기 = (1,4,3) : 차례대로 1개의 샘플, 4개의 단어, 각 단어를 3개의 숫자로 표현
-
마지막 cell의 출력이 1차원이기 때문에 Flatten 클래스로 펼칠 필요가 없음
IMDB 데이터 - 순환 신경망 훈련
원-핫 인코딩 사용
- NLP: 컴퓨터를 사용해 인간의 언어를 처리하는 분야-corpus(말뭉치)
- token: 분리된 단어
- 어휘사전: 훈련세트에서 고유한 단어를 뽑아 만든 목록
- 리뷰의 길이 맞추기
from tensorflow.keras.preprocessing.sequence import pad_sequences # pad_sequences () 함수를 사용하여 길이를 100으로
train_seq = pad_sequences(train_input, maxlen=100)- 순환 신경망 만들기
from tensorflow import keras
model = keras.Sequential()
model.add(keras.layers.SimpleRNN(8, input_shape=(100,500))) # 활성화 함수 기본값 tanh 사용 # 500은 정숫값의 범위가 0~499여서 원핫인코딩으로 표현하려면 배열의 길이가 500이어야 함
model.add(keras.layers.Dense(1,activation='sigmoid'))- 원-핫 인코딩 사용
train_oh = keras.utils.to_categorical(train_seq)- 순환 신경망 훈련하기
rmsprop = keras.optimizers.RMSprop(learning_rate=1e-4)
model.compile(optimizer=rmsprop, loss='binary_crossentropy',metrics=['accuracy'])
checkpoint_cb = keras.callbacks.ModelCheckpoint('best-simplernn-model.h5', save_best_only=True)
early_stopping_cb = keras.callbacks.EarlyStopping(patience=3, restore_best_weights=True)
history = model.fit(train_oh, train_target, epochs=100, batch_size=64, validation_data=(val_oh, val_target),
callbacks=[checkpoint_cb, early_stopping_cb])단어 임베딩 사용
- 각 단어를 고정된 크기의 실수 벡터로 바꾸어줌
- 입력으로 정수 데이터를 받는 것이 장점
model2 = keras.Sequential()
model2.add(keras.layers.Embedding(500,16,input_length=100)) # 500: 어휘사전의 크기, 16: 임베딩 벡터의 크기(원핫인코딩보다 훨씬 작음)
model2.add(keras.layers.SimpleRNN(8))
model2.add(keras.layers.Dense(1,activation='sigmoid'))- 이후 똑같은 방식으로 훈련
LSTM(Long Short-Term Memory)
- 단기 기억을 오래 기억하기 위해 고안됨
- 순환되는 상태가 2개 존재: hidden state & cell state
- hidden state과 달리 cell state는 다음층으로 전달되지 않고 LSTM 셀에서만 순환되는 값
from tensorflow import keras
model = keras.Sequential()
model.add(keras.layers.Embedding(500,16,input_length=100))
model.add(keras.layers.LSTM(8))
model.add(keras.layers.Dense(1,activation='sigmoid'))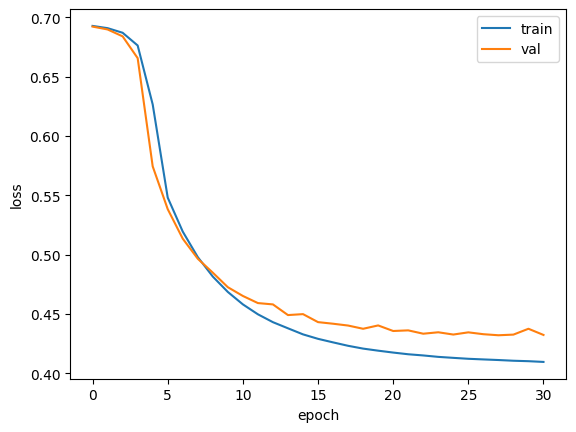
- 순환층에 dropout 적용
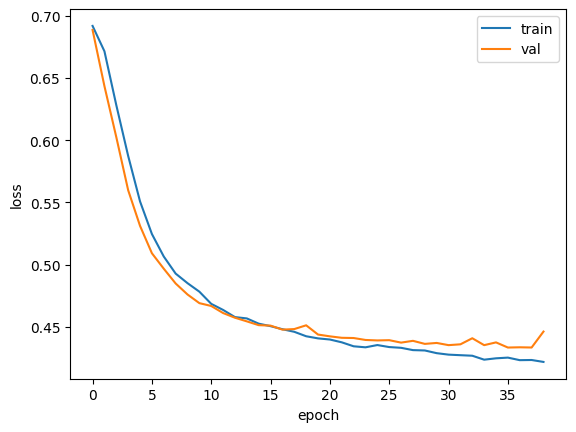
GRU(Gated Recurrent Unit)
- LSTM을 간소화한 버전
- cell state는 계산하지 않고 hidden state 하나만 포함
- 작은 cell이 3개 들어있음: 2개는 sigmoid activation function, 1개는 tanh activation function 사용
[출처] https://wikidocs.net/22886
혼자공부하는 머신러닝+딥러닝

^.^