[Scikit-learn] xgboost , light gbm
트리모델
1.랜덤포레스트
2.GBM
xgboost 와 lightgbm은 트리모델로 알고리즘이 다를 뿐 사용법은 비슷하다.
3.XGBoost
-
xgboost는 microsoft에 저작권이 있음.
-
gpu 지원
- gpu : 행렬병렬연산을 매우 빠르게 할 수 있음.
-
과대적합이 나지 않게 스스로 규제기능 탑재됨. (예측의 변동성을 줄임 L1, L2..)
-
pruning 가지치기
-
early stopping
-
자체 내장된 교차검증
-
결측치 자체 처리
<colab으로 xgboost 예시 돌리기>
기본세팅
1. install 하기
!pip install xgboost==1.5.0
!pip install pandas ==1.5
2. data 가져오기
data_df = pd.Dataframe (cancer.data, columns=cancer.featue_names)
data_df['target'] = cancer.target
data_df
3. 학습/검증/테스트 데이터 세트 만들기
- *점진적 학습*을 위해 훈련한 데이터세트를 계속 볼 수 있어야 함.
from sklearn.model_selection import train_test_split
# train/test
x_train, x_test, y_train, y_test = train_test_split
( data_df.drop("target",axis=1),
data_df['target'],
random_state=42)
#train/ valid
x_train,x_valid, y_train,y_valid = train_test_split
( x_train, y_train, random_state=42)
XGB - python wrapper (by.DMatrix_ feature와 target을 동시에 관리하는 매체)
1.DMatrix
dtr = xgb.DMatrix(data=X_train, label = y_train)
dval = xgb.DMatrix(data=X_valid, label = y_valid)
dtest = xgb.DMatrix(data=X_test, label = y_test)
2.XGB 파라미터 설정
params = {
"max_depth" :3,
"eta" : 0.05, #미분값을 얼마나 반영할지 (경사하강법)
'objective' : 'binary:logistic', #목적함수
'eval_metric' : 'logloss'
}
# 400회 훈련
num_rounds = 400
훈련
# dtr로 모델훈련
# dtr, dval이용 해서 성능평가
eval_list = [
(dtr, 'train'), #훈련 데이터를 이용해 평가
(dval,'eval') # 검증 데이터 이용해 평가
]
xgb_model = xgb.train (
params = params,
dtrain = dtr,
num_boost_round = num_rounds,
early stopping_rounds = 50, #성능개선이 50회내에 이뤄지지않으면 종료
evals = eval_list #평가 세트 지정
)
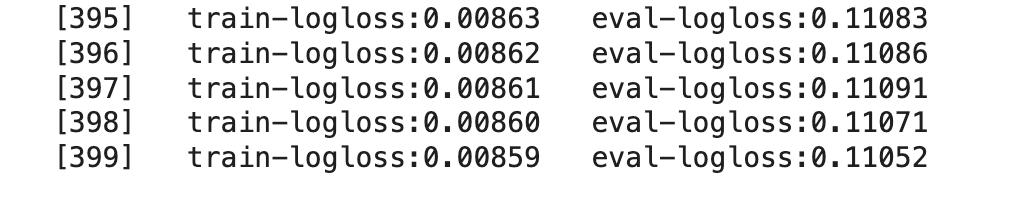
차이가 심하다 -> 과대적합의 가능성이 있다.
XGB python wrapper 모델 예측
import numpy as np
1. xgb모델 predict하기 ( 양성 클래스의 '확률'이 나옴 )
pred_props = xgb_model.predict(dtest)
pred_props[:10]
#threshold정해서 0.5이상이 되는 값은 1, 아닌값은 0으로 확률값을 class 정보로 바꿈
threshold = 0.5
preds = [1 if x > threshold else 0 for x in pred_props ]
XGB scikit learn wrapper
!pip install scikit-learn==1.5
1. xgbclassifier 학습
from xgboost import XGBClassifier
xgb_clf = XGBClassifier(
n_estimators = 400,
learning_rate = 0.05,
max_depth= 3,
eval_metrics = 'logloss'
)
xgb_clf.fit(x_train, y_train, verbose=true)
2.예측
preds = xgb_clf.predict(x_test)
pred_proba = xgb_clf.predict_proba(x_test) #xgboost는 확률적 해석까지해줌
3. early stopping 적용한 classifier
xgb_clf = XGBClassifier(
n_estimators = 400,
learning_rate = 0.05,
max_depth= 3
)
evals = [
(x_train,y_train), #훈련 데이터를 이용해 평가
(x_valid,y_valid) # 검증 데이터 이용해 평가
]
xgb_clf.fit(
x_train,y_train,
early_stopping_rounds = 5,
eval_set = evals,
verbose = True
)
feature importance 확인 가능.
xgb_clf.feature_importances_** early stopping
- 더이상 성능개선이 이루어지지 않으면 (손실함수 감소가 더딤)
4.lightGBM
- one hot encoding 없이도 카테고리형 피쳐를 최적으로 변환. 분할노드 수행
- 균형트리분할 level wise (얕지만 넓게. 과대적합방지) / 5depth도 깊다.
- 리프중심트리분할 leaf wise (오류가 줄 수 있는 방향을 파고들되 보다가 만다.)
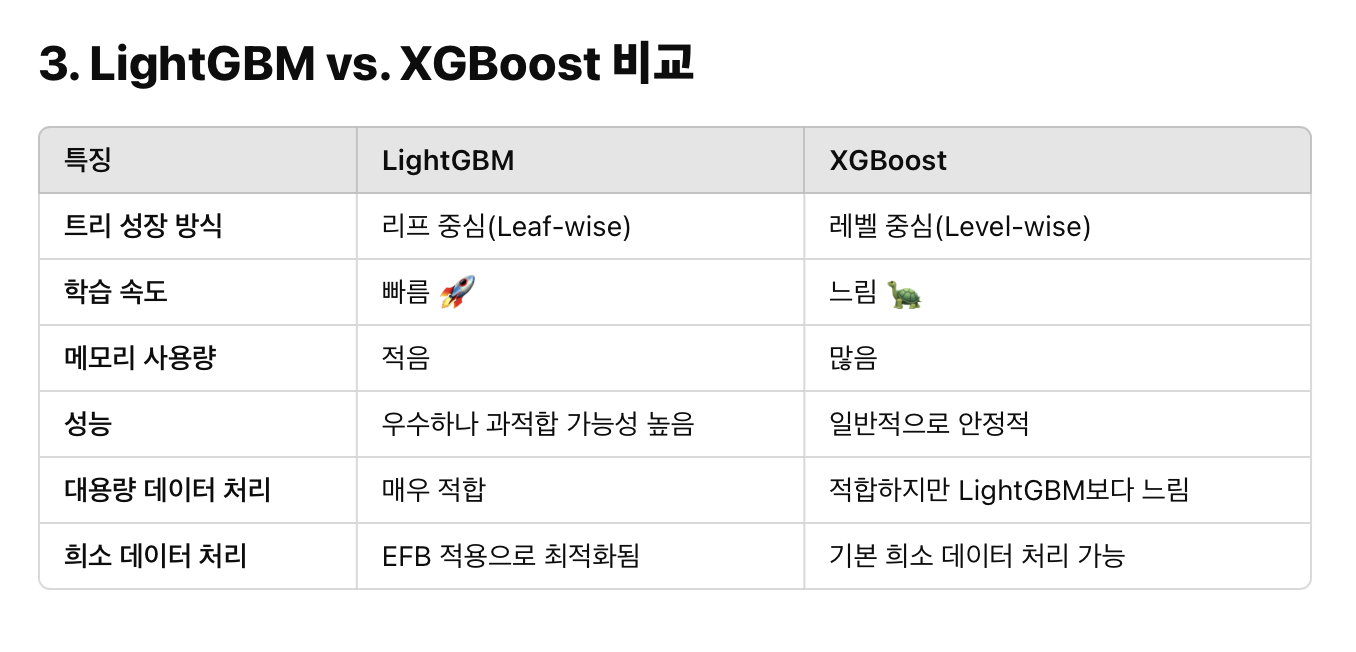
- xgboost는 균등. lightGBM은 성능개선만을 위한 트리가 만들어져 한쪽으로 내려가는 특징이 있다..
- lightGBM이 알아서판단하게 max_depth은 안건드는게 좋다. 너무 과대적합이 심하다 싶으면 건드는게 좋음. (얕게하면 잘 안됨)
1. install 하기
!pip install lightgbm==3.3.2
!pip install pandas==1.5
!pip install scikit-learn==1.5
2. train/ test, train/valid 나누기
X_train , X_test , y_train , y_test = train_test_split(
data_df.drop("target", axis=1),
data_df['target'],
random_state=42
)
X_train, X_valid, y_train, y_valid = train_test_split(
X_train,
y_train,
random_state=42
)학습
from lightgbm import LGBMClassifier
lgbm_clf = LGBMClassifier(
n_estimators=400,
learning_rate=0.05
)
evals = [
(X_train, y_train),
(X_valid, y_valid)
]
lgbm_clf.fit(
X_train, y_train,
early_stopping_rounds=5,
eval_metric='logloss',
eval_set =
)- eval_set을 사용하는 이유
: early_stopping_round, 조기종료를 위해

인공지능응용학과 졸업예정..