groupby
- 기준 : 범주형 데이터
범주형 질적자료. 문자열로 표현되는 데이터. 딱딱 구분되는 값이다. (계산x. 그룹핑o)
- 원도표
연속형 양적자료. 숫자데이터는 계산이 가능하다. (계산o. 그룹핑🔼)
- 박스플롯,히스토그램...
단, 연속형 데이터를 구간으로 나눈다면 그룹핑이 가능하다. cf. 도수분포표!

단일 그룹
(nan값은 집계에서 빠진다.)
|함수|설명|
|:--|:--|
|count()|행의 갯수|
|nunique()|행의 유니크한 갯수|
|sum()|합|
|mean()|평균|
|min()|최솟값|
|max()|최댓값|
|std()|표준편차|
|var()|분산|
df.groupyby("Pclass").count()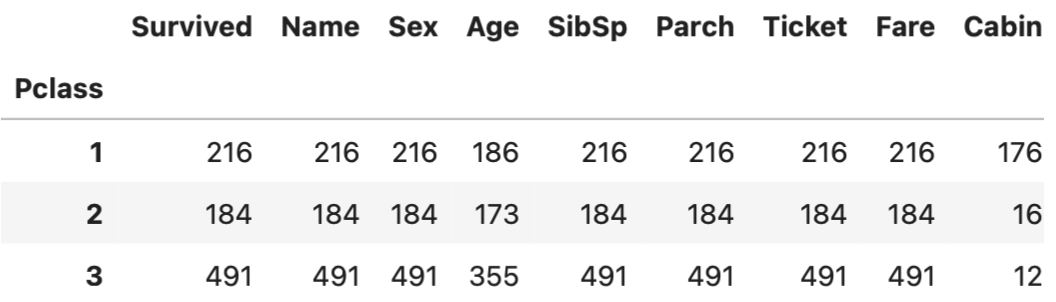
->Pclass로 묶어서 count() 해야겠다!
1.묶고 2.행동하기
이는 N->1 n개의 데이터를 1개로 줄이는 과정을 거치는 것. (reduction)
수치형변수들만 사용하고 싶을땐 sum(numeric_only=True) 등 안에 numeric_only 옵션을 넣어주면 된다.
특정컬럼의 통계값 내기 (순서 중요)
1.묶고 2.특정하고 3.계산하고
df.groupby("Pclass")["Age"].count()
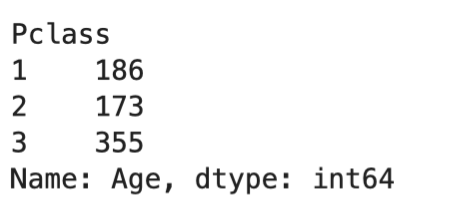
다중그룹
- index가 2개 이상!
groupby
여러 index를 []로 묶어주면 된다.
df.groupby(["Sex","Pclass"]).mean(numeric_only=True)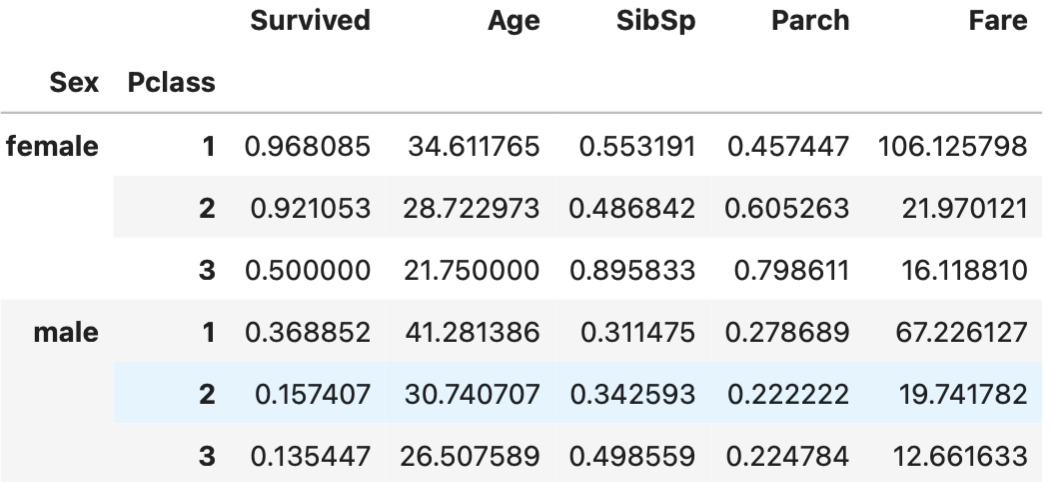
crosstab
"범주형 데이터" 비교분석
- 행. 열 데이터 따로 지정
- 기준이 행/열 2개로 나눠진다고 생각하기
pd.crosstab(df['Sex'],df['Survived'])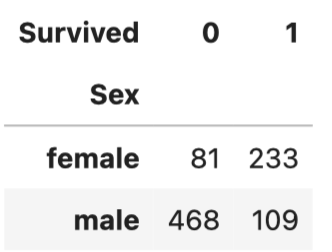
- 범주별 비율 구하기
옵션으로 normalize 쓰기
normalize = 'all', 'index', 'columns' 3가지 가능.

인공지능응용학과 졸업