사용 라이브러리 : BeautifulSoup
- html을 dom 형식으로 만들어 파싱, 쉽게 데이터 가져올 수 있게 만드는 라이브러리
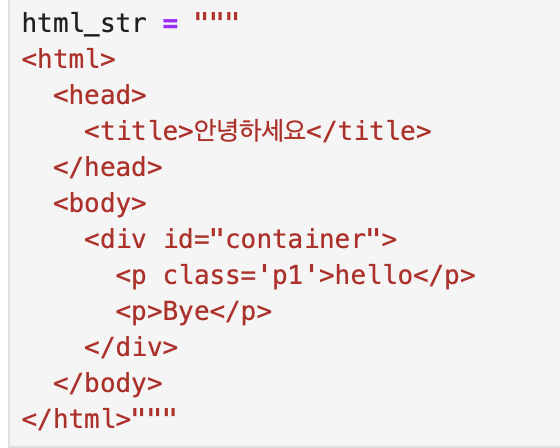
이 html_str을
soup = BeautifulSoup(html_str,'html.parser')로 파싱하면
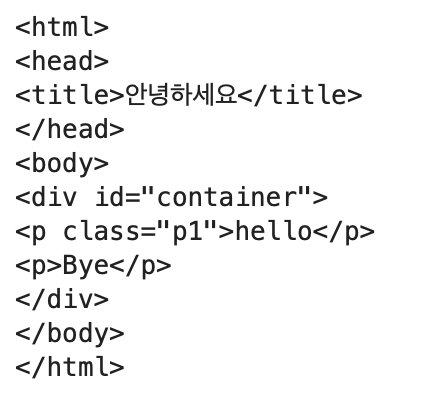
(사실은 DOM형태임)
이런식으로 나타내진다.
find / find_all(리스트형태) 이걸로 골라야함
- 중에서 속성/ 클래스가 인것 찾기
soup.find("div", {"id" : "container"})
딸린게 주르륵 나온다.
find으로 고른 태그에서 적용하기
nextSibling/ prevSibling
- 형제 찾기
text
- 태그가 감싸고 있는 문자열 추출
get
p_p1.get("class")
- 속성값 얻기
select / select_one
- 선택자를 사용하는 방식
soup.select_one("#container")- id가 container인 것 찾기

주르륵 나온다
soup.select_one ("#container > .p1")- id가 container이면서 그 자식의 class가 p1인 태그 가져오기.

단하나..!
<전체코드>
import requests
from bs4 import BeautifulSoup
url = '...'
response = requests.get(url)
page = response.content
soup = BeautifulSoup(page, 'html.parser')
exchange_list = soup.select('#exchangeList > li')
c_name_list = []
exchange_rate_list = []
change_list = []
updown_list = []
for exchange in exchange_list:
c_name = exchange.select_one("h3.h_lst").text
exchange_rate = float(exchange.select_one("span.value").text.replace(",",""))
change = float(exchange.select_one("span.change").text)
updown = exchange.select("span.blind")[-1].text
c_name_list.append(c_name)
exchange_rate_list.append(exchange_rate)
change_list.append(change)
updown_list.append(updown)
import pandas as pd
exchange_datas = {
"국가" : c_name_list,
"환율" : exchange_rate_list,
"변동" : change_list,
"등락" : updown_list
}
df_exchange = pd.DataFrame(exchange_datas)
df_exchange.to_csv("./data/0121환율정보")언제나 html 스크래핑이 가능한 것은 아니다.
- 동기만 html스크래핑가능
- 비동기는 안됨 (ex. kakao 지도) -> api 써야함

인공지능응용학과 졸업예정..