크롤링
1.크롤링 vs 스크래핑

: 포털 사이트에서 웹페이지 정보를 수집: 특정페이지의 정보수집크롤링은 웹사이트에 대한 정보를 가져오는 것이고, 스크래핑은 특정 웹사이트의 html같은 문서 정보를 직접 가져오는 것이다.우리가 흔히 말하는 크롤링!이라는 것은 사실 스크래핑이었던 것이다...
2.web 서비스 구조 (client<->server) , API
(오늘의 필기.. ) 하나하나 복습해보장 웹서비스 : 기계 간의 통신을 지원하도록 설계된 소프트웨어 시스템 client와 server가 정보를 교환하며 통신한다. client -(request )-> server --(processing..)-⌉ client -
3.카카오API 웹 스크래이핑
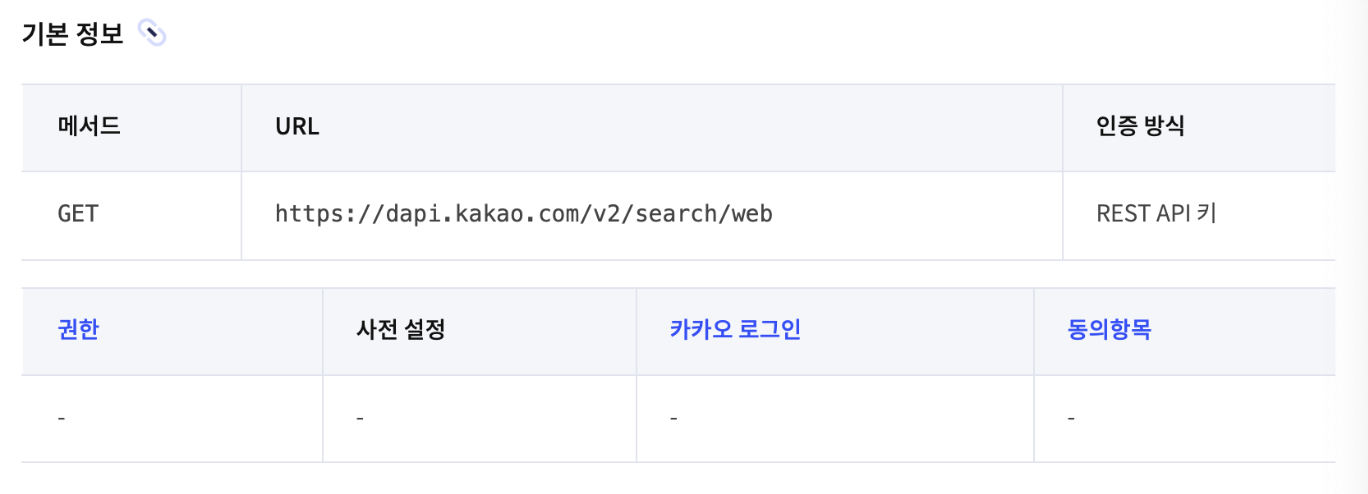
사용 라이브러리 : requests http 이용해 요청을 수행https://dapi.kakao.com -> HOSTv2/search/web -> API뒤에 ?query='검색단어'authorization : key 붙이기 (초대장)requests.get(ur
4.html 스크래핑
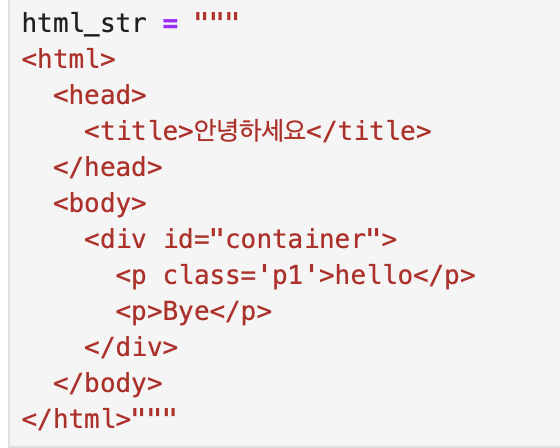
사용 라이브러리 : BeautifulSouphtml을 dom 형식으로 만들어 파싱, 쉽게 데이터 가져올 수 있게 만드는 라이브러리 이 html_str을soup = BeautifulSoup(html_str,'html.parser')로 파싱하면 (사실은 DOM형태임)이런식
5.html 스크래핑은 언제나 할 수 있을까? (beautifulsoup으로 카카오맵리뷰 크롤링)
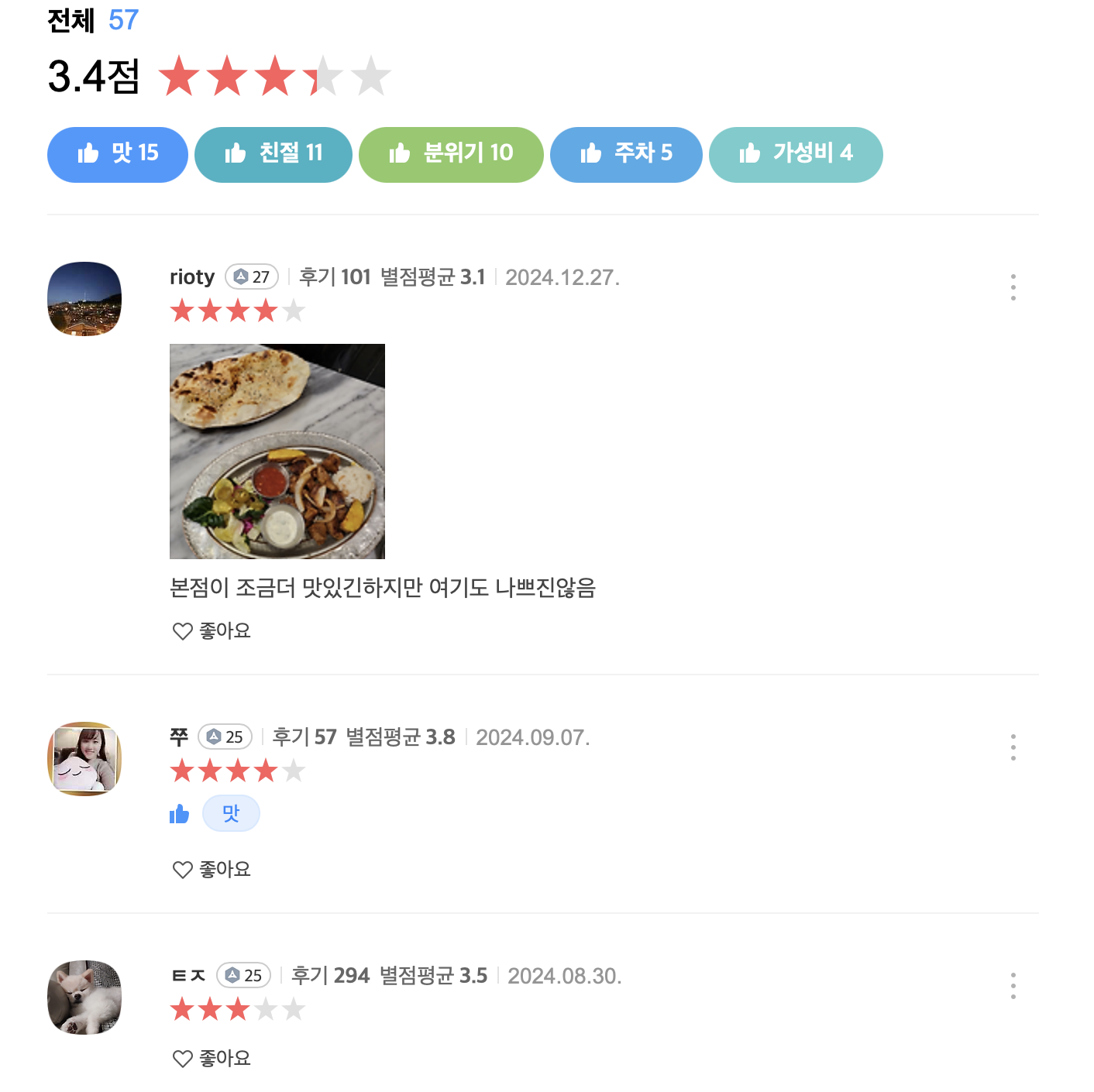
카카오맵 API 에는 음식점 메뉴 정보, 가까운역, 카테고리, 최신리뷰, 영업시간, 평점을 제공하지 않는다. 그러나 카카오맵 리뷰를 한번 크롤링해보고싶어...단순히 page의 URL주소를 활용, request로 받아와서 soup으로 파싱한 후 tag을 선택하여 데이터
6.화장품 성분 데이터 요약 크롤링하기! (1)
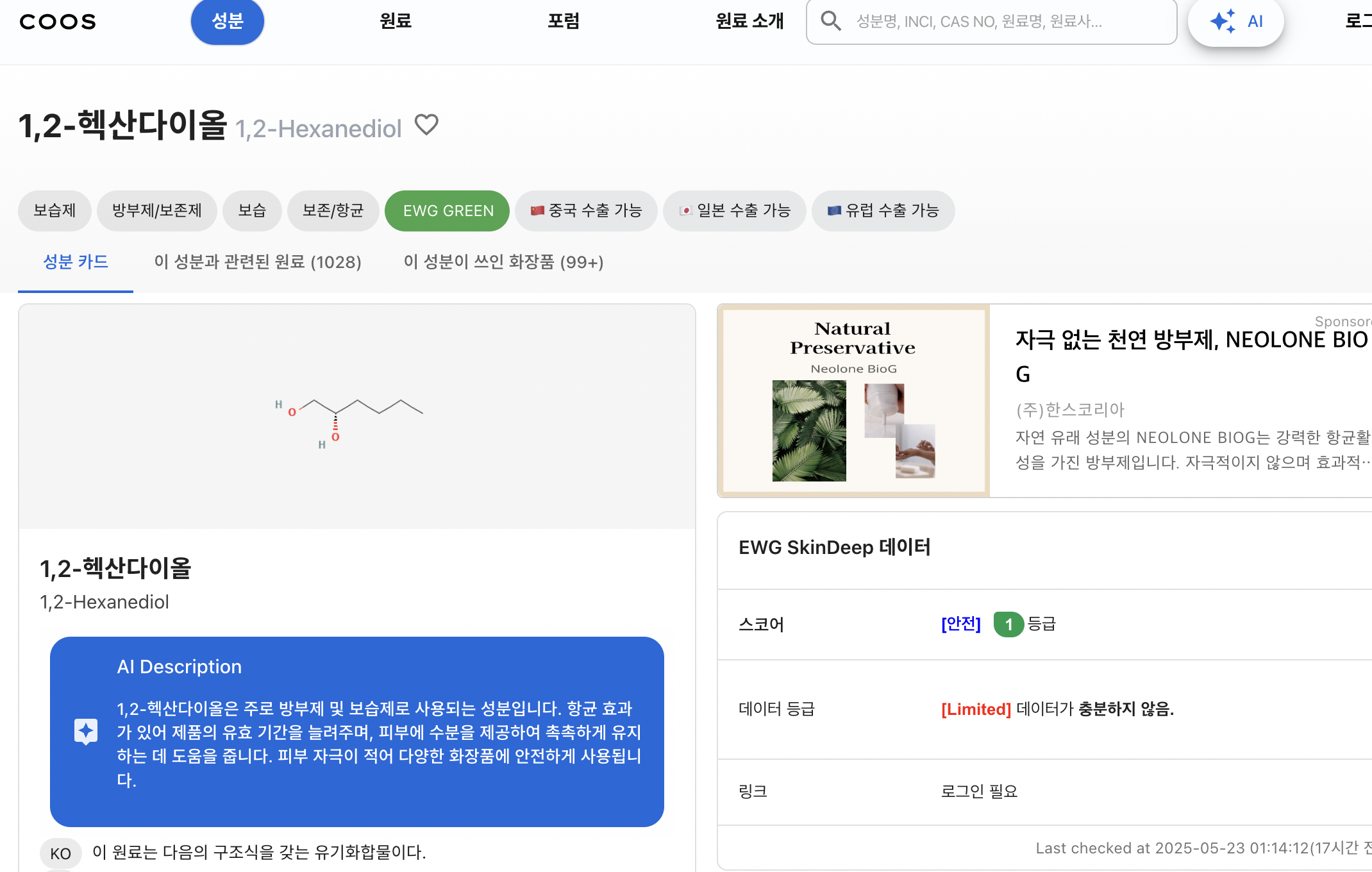
https://coos.kr/ingredients/1%2C2-%ED%97%A5%EC%82%B0%EB%8B%A4%EC%9D%B4%EC%98%AC여기의 AI Description 내용을 긁어오자.필요한 라이브러리 입력response, 파서 설정.설명: 1,2-헥산