하루 개요
코어 자바스크립트 챕터 5 복습
코어 자바스크립트 챕터 6 공부
알고리즘 문제 1개 풀기
SQL 개념 복습하기
SQL 리트코드 문제 풀기
Node.js 구현하기
(시간이 남는다면) 자료구조 || 운영체제 공부
글이 날라가서 3번째 다시 쓰는중 ㅋㅋ ㅋㅋ 휴..
코어 자바스크립트: 프로토타입
코어 자바스크립트 책 기반으로 학습 용으로 쓴 글입니다.
추가 참고 자료:
https://ko.wikipedia.org/wiki/%ED%94%84%EB%A1%9C%ED%86%A0%ED%83%80%EC%9E%85_%EA%B8%B0%EB%B0%98_%ED%94%84%EB%A1%9C%EA%B7%B8%EB%9E%98%EB%B0%8D
https://ko.javascript.info/prototype-inheritance
프로토타입 기반 프로그래밍은 객체지향 프로그래밍의 한 형태의 갈래로 클래스가 없고, 클래스 기반 언어에서 상속을 사용하는 것과는 다르게, 객체를 원형(프로토타입)으로 하여 복제의 과정을 통하여 객체의 동작 방식을 다시 사용할 수 있다. 프로토타입기반 프로그래밍은 클래스리스(class-less), 프로토타입 지향(prototype-oriented) 혹은 인스턴스 기반(instance-based) 프로그래밍이라고도 한다.
__proto__가 생략 가능한 프로퍼티임. (생략 가능한 프로퍼티라는 개념은 언어 창시자 브랜든 아이크 머리에서 나온 것이므로 그냥 그런가보다 할 수밖에 없음)
new 연산자로 Constructor를 호출하면 instance가 만들어지는데, 이 instance의 생략 가능한 프로퍼티인
__proto__는 Constructordml prototype을 참조한다.
__proto__ 프로퍼티는 생략 가능하도록 구현돼 있기 때문에 생성자 함수의 prototype에 어떤 메서드나 프로퍼티가 있다면 인스턴스에서도 마치 자신의 것처럼 해당 메서드나 프로퍼티에 접근할 수 있게 된다.
이 글 읽으면 철학적/본질적으로도 이해 가능
Constructor 프로퍼티
생성자 함수의 프로퍼티인 prototype 객체 내부에는 constructor라는 프로퍼티가 있다.
이 프로퍼티는 원래의 생성자 함수 (자기 자신)을 참조함.
인스턴스로부터 그 원형이 뭔지 알 수 있는 수단임!!
const arr = [1, 2];
console.log(Array.prototype.constructor === Array); // true
console.log(arr.__proto__.constructor === Array); // true
console.log(arr.constructor === Array); // true
const arr2 = new arr.constructor(3, 4);
console.log(arr2); // [ 3, 4 ]
console.log(arr); // [ 1, 2 ]인스턴스의 __proto__가 생성자 함수의 prototype 프로퍼티를 참조하며 __proto가 생략 가능하기 때문에 인스턴스에서 직접 constructor에 접근할 수 있는 수단이 생긴 것이다.
constructor는 읽기 전용 속성이 부여된 예외적인 경우 (기본형 리터럴 변수 ~ number, string, boolean)를 제외하고 값 못바꿈
메서드 오버라이드
앞서 적었듯 prototype 객체를 참조하는 __proto__를 생략하면 인스턴스는 prototype에 정의된 프로퍼티나 메서드를 마치 자신의 것처럼 사용할 수 있다.
- 만약 인스턴스가 동일한 이름의 프로퍼티 또는 메서드를 가지고 있는 상황
const Person = function (name) {
this.name = name;
};
Person.prototype.getName = function () {
return this.name;
};
const iu = new Person("지금");
iu.getName = function () {
return `바로` + this.name;
};
console.log(iu.getName()); // 바로지금
iu.__proto__.getName이 아닌 iu 객체에 있는 getName 메서드가 호출됨.
=> 메서드 오버라이드라고 부름
js엔진이 getName이라는 메서드를 찾는 방식은 가장 가까운 대상인 자신의 프로퍼티를 검색하고, 없으면 그 다음으로 가까운 대상인 __proto__ 를 검색하는 순서로 진행한다.
어떤 생성자 함수이든 prototype은 반드시 객체이기 때문에 Object.prototype이 언제나 프로토 타입 체인의 최상단에 존재하게 된다.
따라서 객체에서만 사용할 메서드는 다른 데이터 타입처럼 프로토타입 객체 안에 정의할 수가 없다.
프로토타입 (원형)을 계속 찾아가다 보면 최종적으로 Object.prototype에 도달하게 됨. 이런식으로 __proto__ 안에 다시 __proto__를 찾아가는 과정을 프로토타입 체이닝이라고 하며, 이 프로토타입 체이닝을 통해 각 프로토타입 메서드를 자신의 것처럼 호출할 수 있다.
이때 접근 방식은 자신으로부터 가장 가까운 대상부터 점차 먼 대상으로 나아가며 원하는 값을 찾으면 검색을 중단함!!!!
Node.js 구현
삭제 구현 오류 잡기
이게 코드 구현이 원래 그렇게 되는 것 같음.
그냥 예제코드를 통으로 복붙을 했는데
아무래도 게시물 구분을 title로 해서 그런듯.
예를 들면 동일한 제목의 글일 경우 버그가 생긴다.
지금은 구현에 대해 전체적으로 톺아보는게 중요하다 생각해서, 일단 넘어가고 진도를 먼저 빼기로 결정함.
는 아니라 찝찝해서 계속 봣는데 함수를 이상한 걸 쓰고있었다....
는 아니라 뭐지.. 파일 다 삭제하고 쓰니까 된다...
다시 버그 구현해볼라고 내용없이 제목만 쓰고
undefined 이렇게도 써봣는데..
Express 미들웨어 사용하기
공식 문서 https://expressjs.com/en/guide/using-middleware.html
https://psyhm.tistory.com/8
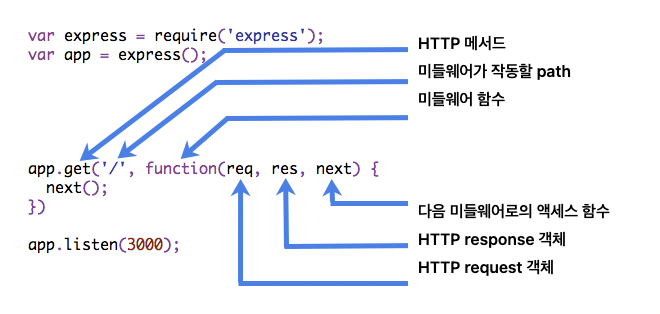
Middleware functions can perform the following tasks:
- Execute any code.
- Make changes to the request and the response objects.
- End the request-response cycle.
- Call the next middleware function in the stack.
Express Third-party middleware: body-parser
http://expressjs.com/en/resources/middleware/body-parser.html
app.post("/create_process", function (request, response) {
var body = "";
request.on("data", function (data) {
body = body + data;
});
request.on("end", function () {
var post = new URLSearchParams(body);
var title = post.title;
var description = post.description;
fs.writeFile(`data/${title}`, description, "utf8", function (err) {
response.writeHead(302, { Location: `/?id=${title}` });
response.end();
});
});
});사용자가 입력한 정보는 POST 방식으로 전달되므로 Get방식과는 다르게 데이터 크기가 클 수 있다. 따라서 data라는 이벤트가 발생할 때마다 body 변수에 데이터를 추가하다가 end이벤트가 발생하면 body데이터에 담긴 데이터를 저장함.
body-parser라는 미들웨어(= 요청 정보의 본문을 해석해서 우리에게 필요한 형태로 가공해주는 프로그램)를 사용하면 좀 더 간결하고 좋은 코드를 작성할 수 있다.
body: 웹 브라우저에서 요청한 정보의 본문을 의미함
책에선 npm 쓰는데 yarn 쓸거임!
yarn add body-parser
https://yarnpkg.com/package/body-parser
Examples
Express/Connect top-level generic
This example demonstrates adding a generic JSON and URL-encoded parser as a top-level middleware, which will parse the bodies of all incoming requests. This is the simplest setup.
var express = require('express')
var bodyParser = require('body-parser')
var app = express()
// parse application/x-www-form-urlencoded
app.use(bodyParser.urlencoded({ extended: false }))express use메서드에 body-parser라는 미들웨어 전달함. -> 미들웨어가 실행되고 그 결과 전달받음.
즉, 사용자 요청이 있을 때마다 (main.js가 실행될 때마다) 미들웨어가 실행된다.
사용자가 POST 방식으로 전송한 데이터를 내부적으로 분석해서 create_proccess와 같은 동작을 한 다음, 그 결과를 전달해준다는 것만 알면 됨!
app.post("/create_process", function (request, response) {
const post = request.body;
var title = post.title;
var description = post.description;
fs.writeFile(`data/${title}`, description, "utf8", function (err) {
response.writeHead(302, { Location: `/?id=${title}` });
response.end();
});
});end 이벤트가 발생했을 때 처리하는 로직에서 데이터 소스만 request.body로 변경함.
request의 body 속성에는 body-parser가 만들어 준 데이터가 있음
넣는 파일 데이터를 크게 넣으니까 서버가 죽었음
https://spiralmoon.tistory.com/entry/Nodejs-PayloadTooLargeError-request-entity-too-large
PayloadTooLargeError: request entity too large
request의 내용을 파싱하여 라우터가 이용할 수 있도록 위와 같이 두 가지 파서(body-parser 패키지에 있음)를 등록하게 된다. PayloadTooLargeError가 발생하는 원인은 파서가 읽을 수 있는 데이터 허용치보다 request가 보낸 데이터의 크기가 커서 정상적으로 파싱을 할 수 없을 때 발생하는 에러이다.
기본값으로는 .json()과 .urlencoded()가 100kb 까지만 파싱할 수 있도록 설정되어 있다.
app.use(express.json({
limit : "50mb"
}));
app.use(express.urlencoded({
limit:"50mb",
extended: false
}));위와 같은 방법으로 limit 옵션을 추가로 주어 파싱 허용치를 증가 시킬 수 있다.
출처: https://spiralmoon.tistory.com/entry/Nodejs-PayloadTooLargeError-request-entity-too-large [Spiral Moon's programming blog:티스토리]

- 포트 죽이기
sudo lsof -i:3000
sudo kill 09 {PID}Express Third-party middleware: Compression
웹서버가 웹브라우저에 응답할 때 해당 데이터를 압축해서 보낼 수 있다!
웹브라우저가 압축된 데이터를 받아서 웹서버가 지정해준 압축 방식으로 압축을 풀어서 사용자에게 보여줌
yarn add compression
http://expressjs.com/en/resources/middleware/compression.html
DFS 알고리즘 공부
https://leetcode.com/problems/binary-tree-pruning/
이 문제 풀려는데 DFS 알고리즘 봐야해서...먼저 DFS 먼저 공부하고 내일 솔루션 보고 이해하는 것이 목표임
// https://bakjuna.tistory.com/134
https://gmlwjd9405.github.io/2018/08/14/algorithm-dfs.html
https://velog.io/@sangbooom/JS-BFS-DFS
https://jun-choi-4928.medium.com/javascript%EB%A1%9C-%ED%8A%B8%EB%A6%AC-bfs-dfs-%EA%B5%AC%ED%98%84%ED%95%98%EA%B8%B0-e96bcdadd1f3//
이거 보고 공부 중
너비우선탐색BFS(Breadth Frist Search)을 해 보자. 우리는 부모-자식 관계를 통해서 트리의 계층이 생긴것을 확인했다. 이 트리를 탐색(순회) 하는 방법 중 하나가 바로 너비우선탐색이다.
너비우선탐색은 층이 우선이 되었지만, 깊이우선탐색 DFS(Depth Frist Search) 에서는 이번엔 깊이 즉, 자식들이 우선순위가 된다. 부모로 부터 자식까지 아래로 쭉 훑고, 그 옆의 부모 노드로 방문이 넘어가게 된다.
DFS는 아주 간단한 로직으로 이루어진다.
1. 방문하지 않은 노드에서 주변 노드를 모두 방문처리하고,
2. 주변 노드에서 다시 방문하지 않은 노드를 탐색
깊이 우선 탐색(DFS)의 시간 복잡도
DFS는 그래프(정점의 수: N, 간선의 수: E)의 모든 간선을 조회한다.
인접 리스트로 표현된 그래프: O(N+E)
인접 행렬로 표현된 그래프: O(N^2)
즉, 그래프 내에 적은 숫자의 간선만을 가지는 희소 그래프(Sparse Graph) 의 경우 인접 행렬보다 인접 리스트를 사용하는 것이 유리하다.
https://gmlwjd9405.github.io/2018/08/14/algorithm-dfs.html
class Tree {
constructor() {
this.root = null;
}
DFS(fn) {
if(this.root === null) return;
const unvisitedList = [this.root];
while(unvisitedList.length !== 0) {
const current = unvisitedList.shift();
unvisitedList.unshift(...current.children); // list 앞에다 넣어준다. (우선순위: 내 자식들이 먼저야! )
fn(current);
}
}
}하루 마무리
- 완료한 것 ❌🔺✅
코어 자바스크립트 챕터 5 복습
코어 자바스크립트 챕터 6 공부
알고리즘 문제 1개 풀기
SQL 개념 복습하기
SQL 리트코드 문제 풀기
Node.js 구현하기
(시간이 남는다면) 자료구조 || 운영체제 공부
-
하루 반성
cs공부같은건 따로 분리를 하고 여기에 링크만 넣어두는 식으로 하는게 좋은 것 같음 -
피드백
글 자료 분리를 해야할듯
- 내일 할 것
익스프레스 미들웨어 만들기
DFS 자료구조 & 알고리즘 문제 풀기
코어자바스크립트 챕터 6 복습
코어자바스크립트 챕터 7 공부
네트워크 스터디
네트워크 공부 (ip계층)
