해당 글 게시 목적은 업무에서 SQL 쿼리를 쓰면서 느낀점 및 피드백(앞으로 이렇게 발전된 쿼리를 쓰겠다)을 적는 용도
- DISTINCT를 써서 중복값을 제거 했음에도 중복 데이터가 나오는 경우

as is
상황: 입고일자 컬럼을 제외한 다른 컬럼은 동일한 값이 중복되는 상황
사유: left 조인시 on절의 조건에 해당하는 입고일자가 여러개 등장하기 때문
(데이터 테이블에 대해서 어떤식으로 데이터가 쌓이는 지에 대한 무지)
to be
상황 파악: 입고일자를 포함하는 테이블은 inventory_transfer_order_id만 고유하면 입고일자 역시 고유할줄 알았는데, inventory_transfer_order_id에 해당하는 sku_id가 여러개 존재
전: 단일 on절
left join marketwms.integrated_history his on his.inventory_transfer_order_id = trans.inventory_transfer_order_id
후: 여러개 on절 (inventory_transfer_order_id와 sku_id에 맞는 각 데이터 연결)
left join marketwms.integrated_history his on his.inventory_transfer_order_id = trans.inventory_transfer_order_id and his.sku_id = trans.sku_id
- 쿼리가 길다고 멋있는(?) 것이 아니다
여러줄을 썼다고, 돌아가기만 한다고 좋은 쿼리는 아니다. 사실 아직 퀄리티를 따질 단계는 아니지만 방향은 잡고 가야 하므로 느낀점을 작성한다.
1) 효율적인 쿼리문을 작성해야 한다
: 쿼리문이 돌아는 가지만, 데이터 추출시 DB에서 조회하는 데이터의 양이 너무 많을 경우에는 필연적으로 시간이 많이 걸린다. 어떤 테이블을 가지고 어떤 로직으로 쿼리를 짜야 효율적인지 생각해보아야 한다.다른 데이터 분석가가 기재한 쿼리를 분석해 보면서 내가 고쳐야 할 점이 있다면 적극적으로 바꿔야한다.
- 대용량 데이터 처리하는 tip
- 상황: 100만 행 이상의 데이터를 다뤄야 할 때, 구글 스프레드 시트, 엑셀 등으로 raw 데이터를 필터 하는데 시스템 적 오류가 발생 하는 경우
- tip:
1) SQL을 통해 데이터를 확인 해야 한다.
2) 샘플링
ㄴ 데이터를 샘플링 하여 데이터의 일부, 혹은 대표 데이터의 부분을 확인한다.SELECT * FROM table limit 1000--- 첫 1000개의 데이터를 확인 후 데이터의 내용 및 형식 확인3) 집계 함수 사용: count,sum, avg, min, max 집계 함수를 활용하여 평균 값, 특이 값들을 확인 한다.
select coun(*), sum(col), avg(col), min(col),max() from table ----- 테이블의 총 행의 갯수, 특정 열의 통계 값(평균, 이상치 확인 가능)4) 그룹화: group by 하여 특정 컬럼의 특성을 파악
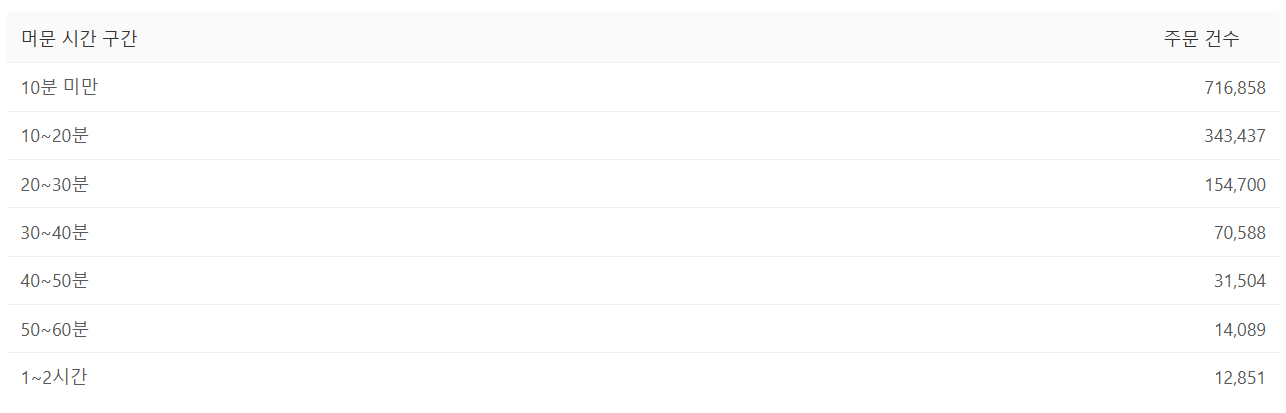
----- 시간대 별 행 갯수가 필요한 상황 select case when time >=120 then '2시간 이상' when time >=60 and time <120 then '1시간~2시간' when time >50 and time <60 then '50분~60분' end as "머문 시간대", count(*) --------> 해당 시간대에 포함 된 데이터 갯수 카운팅 from table group by case when time >=120 then '2시간 이상' when time >=60 and time <120 then '1시간~2시간' when time >50 and time <60 then '50분~60분' end ----------> 머문 시간대를 기준으로 그룹핑 order by case when "머문 시간대" = '50분~60분' then 1 when "머문 시간대"='1시간~2시간' then 2 when "머문시간대" ='2시간 이상' then 3 end------------------------------------------> 컬럼의 값이 조건 값과 일치하면 순번 대로 오름차순*주의 사항:
then 이후의 데이터 형식과 else 이후의 데이터 형식이 같아야 한다.select case when real."최종 검품 요청 수량" >=200 then '200 이상' when real."최종 검품 요청 수량" >=100 and real."최종 검품 요청 수량" <200 then '150이상 200미만' when real."최종 검품 요청 수량" >=50 and real."최종 검품 요청 수량" <100 then '50이상 100미만' when real."최종 검품 요청 수량" <50 then '50미만' else 0 end as "검품 수량 분포도", count(*)위의 예시를 보면 then 이후에 varchar( ex. '200 이상, '150 이상 200 미만' 등)이 나오는 것을 알 수 있다.
하지만 else 뒤에는 0이라는 integer 숫자 형식이 나와 오류가 뜨게 된다.
그러므로, 오류를 방지 하려면 0 대신 varchar 형태인 '0'으로 변경해줘야 한다.
All CASE results must be the same type or coercible to a common type. Cannot find common type between varchar(11) and integer, all types (without duplicates): [varchar(6), varchar(11), varchar(10), varchar(4), integer]
↓ 결과 값 예시