해커랭크(sql)
1.CONCAT, ORDER BY

테이블 소개테이블 명 : OCCUPATIONS문제1번을 구하는 쿼리각 이름과 해당하는 직업의 첫 글자를 알파벳 순서대로 출력 \- 사용할 함수 : CONCAT, LEFT2번을 구하는 쿼리직업의 등장 횟수를 오름차순으로 정렬하여 출력 \- 사용할 함수: CONCAT,
2.cast 함수

cast 함수 사용법 \- 데이터 타입을 변환하는데 사용 ㄴ CAST(변환할 값 AS 변환 하고자 하는 데이터 타입) ㄴ ex) select cast(123 as varchar) : 숫자 123 → str으로 변경 ㄴ ex) select cast('2024-0
3.(기본) 엑셀 함수 --> SQL에 적용하기
들어가기 전에... 엑셀의 기본 집계 함수 (AVERAGE,SUM,COUNT,MAX,MIN 등)는 SQL에서 SELECT절 단독 사용이 가능하지만 , 조건에 맞는 집계값 (SUMIF, COUNTIF 등)을 가져오기 위한 SQL의 기능은 함수를 복합해서 사용 해야 한다
4.(NULL값 설정)COALESCE
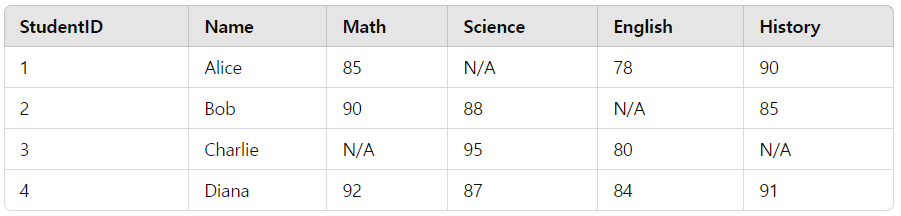
참조할 컬럼 데이터 값의 빈값(NULL)일때 대체로 쓸 문자 지정SELECT COALESCE(컬럼,"N/A") \- 컬럼 데이터 값이 NULL 값일 때 N/A로 출력예시 SELECT StudentID, Name, COALESCE(Math, 'N/A
5.CASE WHEN절
특정 컬럼 값을 어떤 조건으로 나눠 새로운 컬럼을 만들고 싶을 떄 사용 > - 구성 요소 : SELECT 절 CASE WHEN 조건 값* THEN* 조건이 참일 때 값 (ELSE 조건이 거짓일떄 값) END AS "컬럼명" (else 거짓일 떄 값): 생략가능 하며, 생략시 거짓일 때 값은 null로 고정된다. > - 필수 요소 CA...
6.ROW_NUMBER() , CASE WHEN 활용
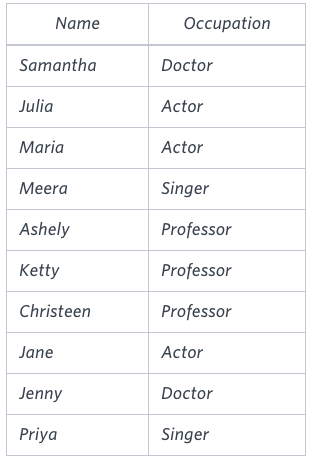
테이블 소개:해당 테이블을 아래와 같이 배열하기(직업별 의사 , 교수, 가수, 배우 순으로 배열하되, 해당되는 셀 값이 없으면 NULL 처리, 이름은 알파벳 순서대로 정렬)첫번째 생각"한 줄(행)에 알파벳 순서대로 데이터를 배열하자" ==> ROW NUMBER로 순위
7.CASE WHEN 서브쿼리
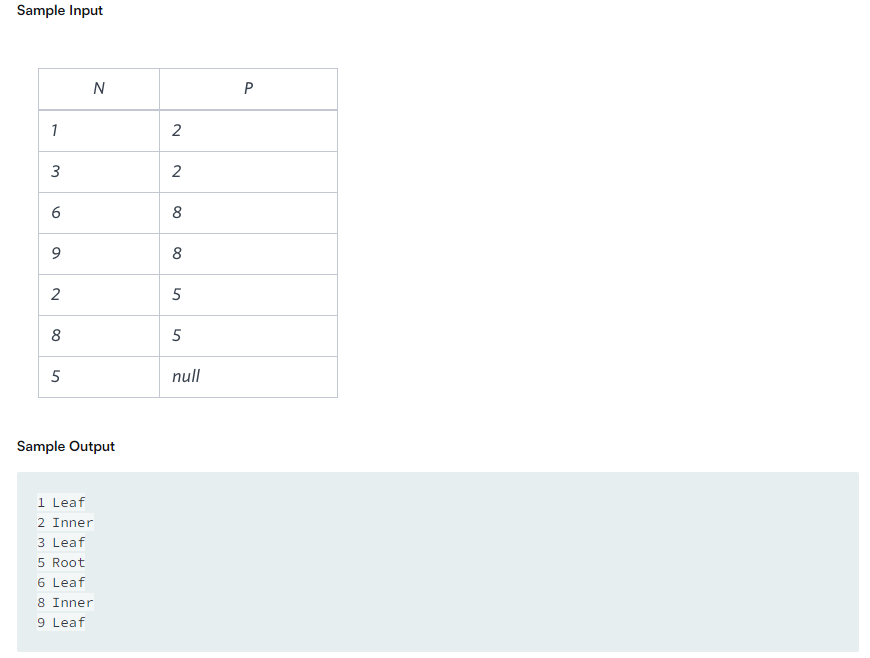
테이블 설명 : 1,3,6,9 = Leaf2,8 = Inner5 = RootN은 value 컬럼이고 p는 n의 부모를 나타내는 값이다첫번째 생각"조건에 따라 분류를 해야 하니 case when을 활용하자"두번째 생각"조건에 따라 구별할때 가장 명확한 것 부터 제거 하자
8.같은 테이블 두번 조인
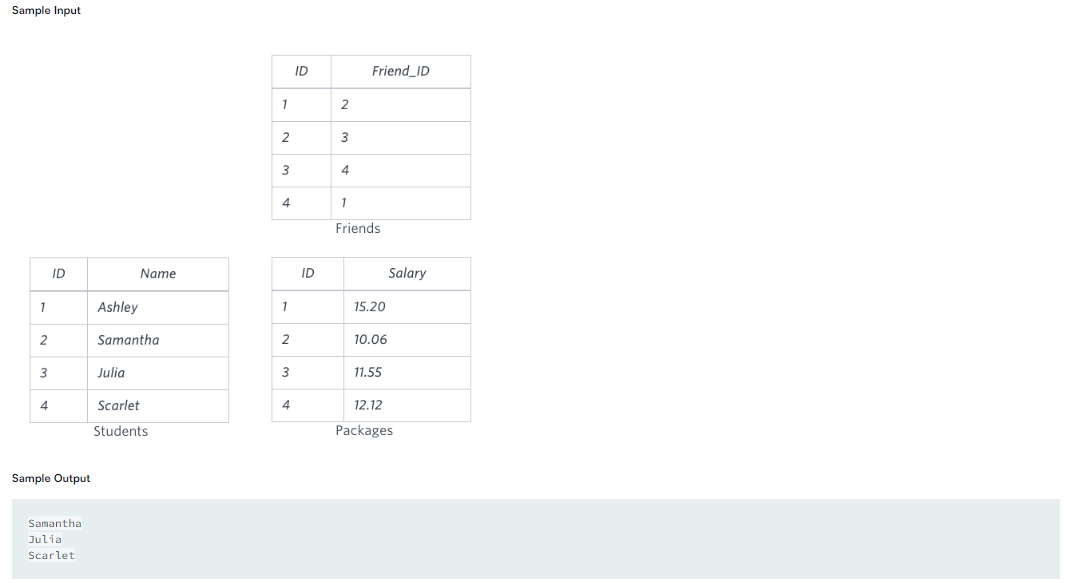
테이블 설명:: Students - id별 학생 이름Friends - id별 학생의 절친Packages - id별 학생의 급여 수준 output : 이름로직: 학생의 이름을 넣으면 그 학생의 절친의 급여 수준이 이 학생보다 높으면 이 학생의 이름 추출첫번째 생각" 테이
9.길이를 반환하는 Length()함수
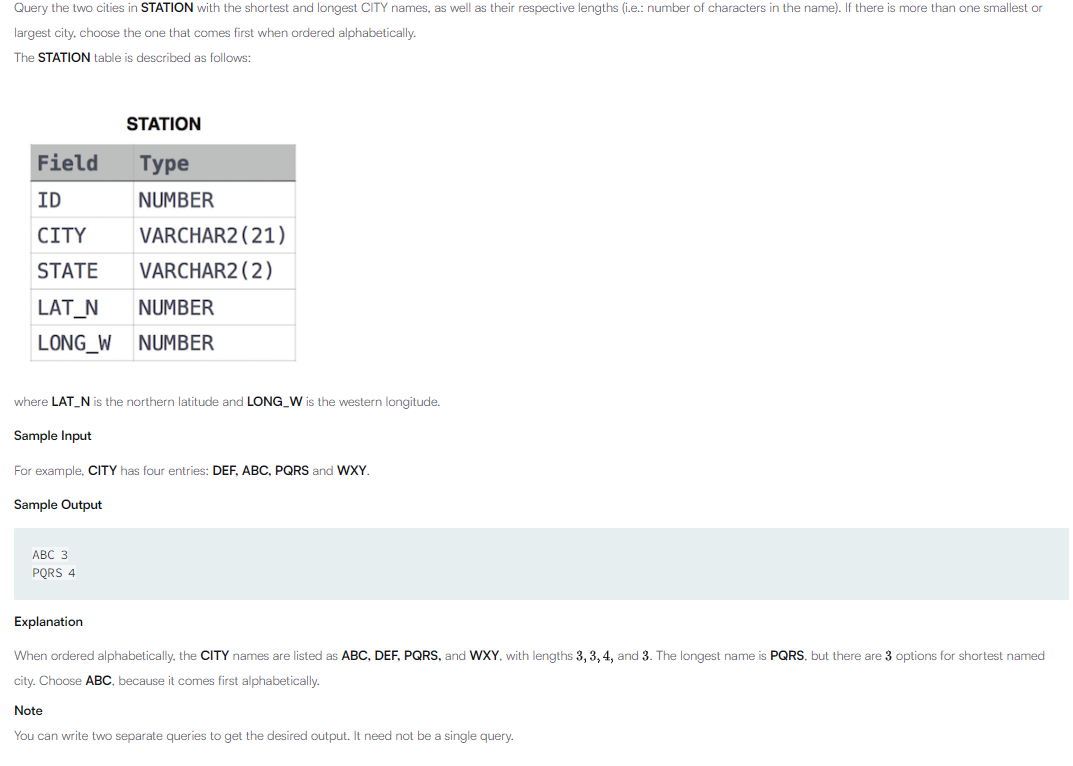
테이블 설명 :가장 문자의 길이가 짧은 도시와, 그 길이가장 길이가 긴 도시와 그 길이를 반환하게끔 하면 된다ex) abc 3set 3xya 3asdf 4이렇게 테이블이 구성된다고 하면 abc 3asdf 4 이렇게 반환되야 한다첫번째 생각"테이블을 세개로 나눠야 하며
10.집계 함수와 GROUP BY
Q. 집계 함수와 GROUP BY는 함께 쓰여야 하는 것인가?A. 꼭그렇지만은 않다.ㄴ 1. 집계 함수는 단독으로 쓸 수 있다EX.)SELECT MAX/SUM/AVG...(CITY)FROM STATIONㄴ 2. 집계 함수와 GROUP BY가 함께 쓰는 경우는 SELEC
11.distinct 함수 활용

내 첫번째 오답with founder as (select e.\*, c.founderfrom Employee eleft join Company c on e.company_code =c.company_code ) select f.company_code ,
12.between 조인
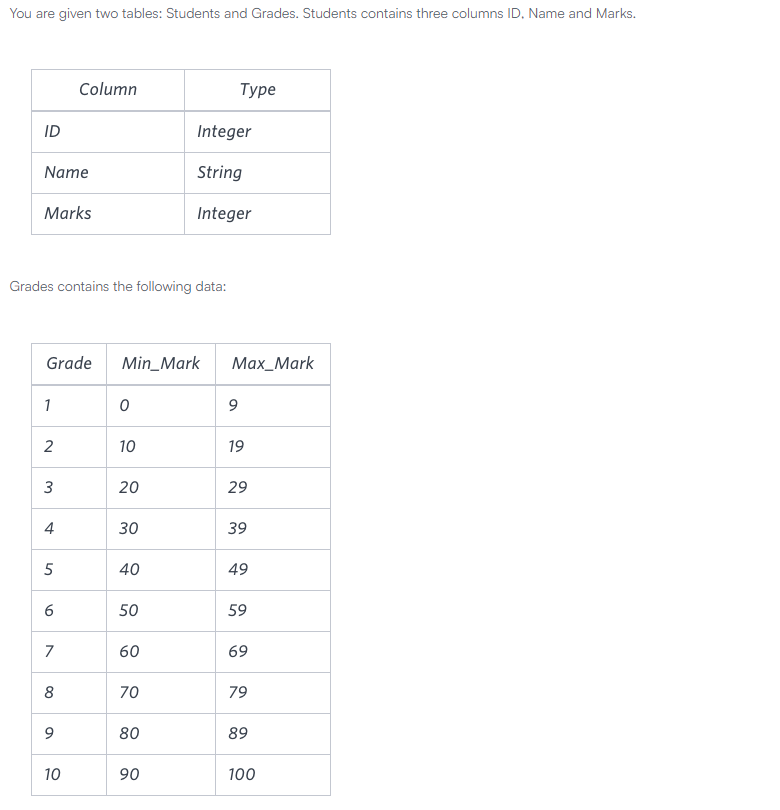
첫번째 오답사잇값 조인8 이상일때만 이름 반영하도록 case when절 추가ㅣWith main as (SELECT s.Name as name , g.Grade as grade , s.Marks as marks FROM Students sJOIN Grades g on s
13.해커아이디
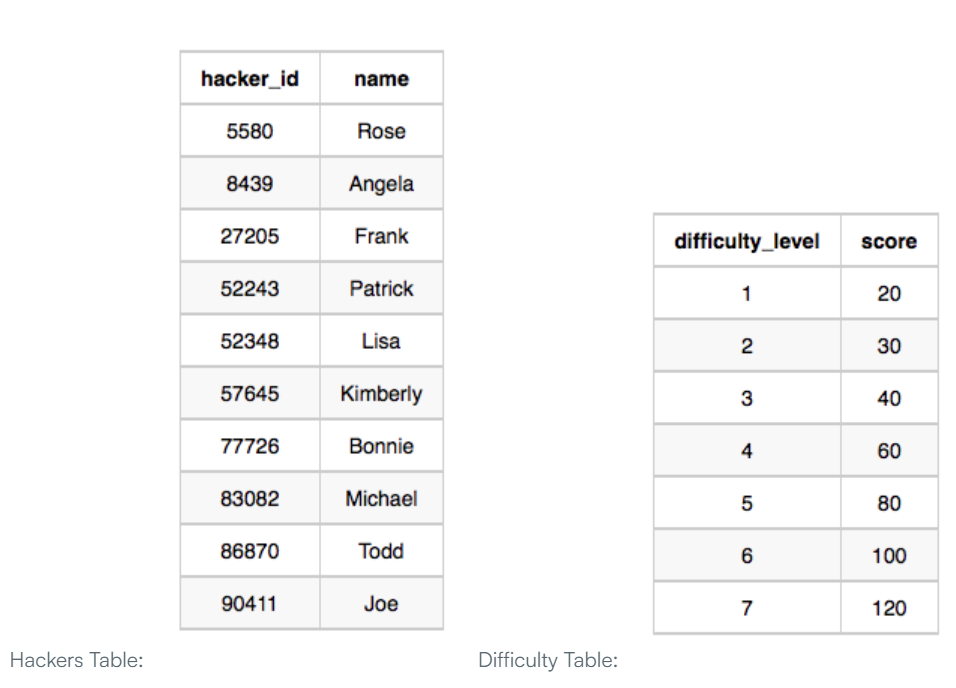
WITH main AS(SELECT S.\*, H.name, C.difficulty_level,C.score FROM Submissions S JOIN Hackers H ON H.hacker_id = S.hacker_id JOIN Challenges ON C.chal
14.where 조건 절 vs having 조건절 구별
15.집계함수 총정리
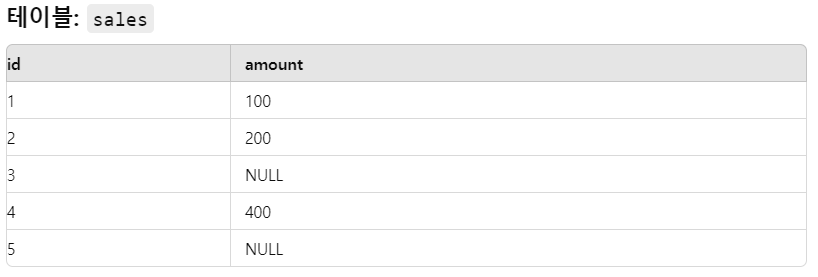
주요 포인트ㄴ 집계 함수에서 NULL값을 포함하는 함수인지 여부 확인하기ㄴ 집계 함수와 GROUP BY의 연관성 이해하기
16.윈도우 함수 총정리
주요 포인트 ㄴ 윈도우 함수의 정의와 윈도우 함수를 쓰는 이유 이해하기 ㄴ 어떤 종류의 윈도우 함수가 있는지 인지하기 ㄴ 어떤 상황에서 그 윈도우 함수가 쓰여야 하는지 이해하기 1. 윈도우 함수란? *Window(=데이터의 특정 그룹이나 범위 ) : 데이터를 원하는
17.조인 총정리
주요 포인트 ㄴ 조인 종류 암기하기 ㄴ 어떤 상황에서 조인 함수가 쓰이는지 이해하기 ㄴ 내가 어떤 포인트에서 자꾸 JOIN VS INNER JOIN 헷갈리는지 인지하기 ㄴ 중복값이 존재하는 테이블에서 조인시 주의해야할 점 : 조인시 중복된 테이블이 나와 원하는 결과 값
18.CTE & 서브쿼리 총정리
주요 포인트ㄴ 서브 쿼리의 종류에 대해 알기ㄴ 어떤 상황에 어떤 서브쿼리를 써야 효율적인지 인지하기ㄴ 내 데이터에 적용시켜 보기
19.서브쿼리 총정리
주요 포인트ㄴ 서브쿼리와 CTE의 차이점 알기ㄴ 서브쿼리의 종류 암기하기ㄴ 어떤 상황에서 적용해야 하는지 인지 후 적용시키기
20.*** SQL 오답노트(인사이트)

DISTINCT를 써서 중복값을 제거 했음에도 중복 데이터가 나오는 경우
21.SQL 기본 사항
현재 근무 중인 회사 (우아한 청년들)의 SQL의 종류는 Trino 엔진을 사용 하므로 ANSI를 사용하고 있다.회사 마다 데이터 사용 환경에 따라 SQL 종류가 달라짐우아한 청년들 데이터 환경 개요모든 우청 사람들이 우청 데이터에 접근 하기 위해선 외부 클라우딩 환경
22.(윈도우 함수) 순위 함수 정리
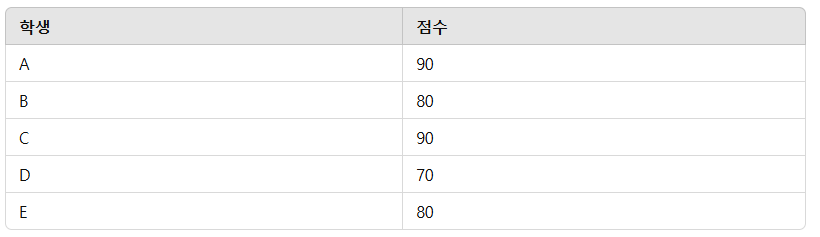
ROW_NUMBER(), RANK(), DENSE_RANK() 의 각각의 특성을 안다.각 차이점을 암기한다.예시 데이터1) RANK() 함수 중복된 값이 있으면 순위에 "갭"이 생깁니다. 예를 들어, 두 학생이 같은 점수를 받으면 그 학생들은 같은 순위를 부여받고, 그
23.(윈도우 함수) 이전(lag)/이후(lead) 값 가져오는 함수 정리
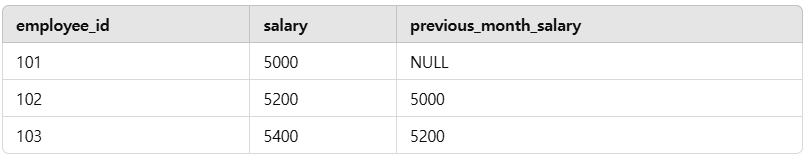
lag, lead 함수의 정의를 배운다둘의 차이점과 실제 쿼리 예시에 대해 배운다(Window Function) 중 하나로, 현재 행의 이전 또는 다음 행의 값을 가져오는 데 사용됩니다. 주로 시간 순서가 있는 데이터에서 이전 값이나 다음 값을 참조해야 할 때 유용합니
24.재구매 고객 확인 하는 방법
SELECT CUSTOMER_ID, COUNT()FROM ORDERGROUP BY CUSTOMOER_IDHAVING COUNT() >=2 ----- 재구매한 고객 필터링 (WHERE 조건은 불가능, COUNT(\*)는 WHERE 조건에서 먼저 실행 되므로 SELECT