- ROW_NUMBER(), RANK(), DENSE_RANK() 의 각각의 특성을 안다.
- 각 차이점을 암기한다.
1. SQL 순위 함수 종류 (3)
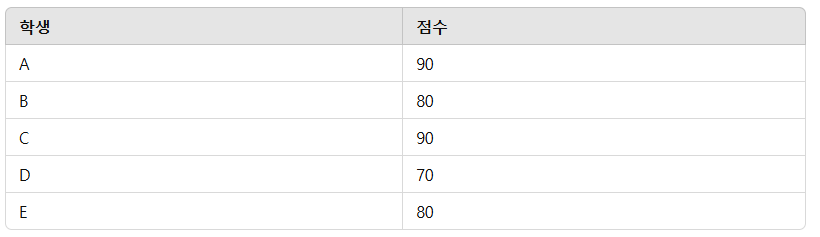
예시 데이터
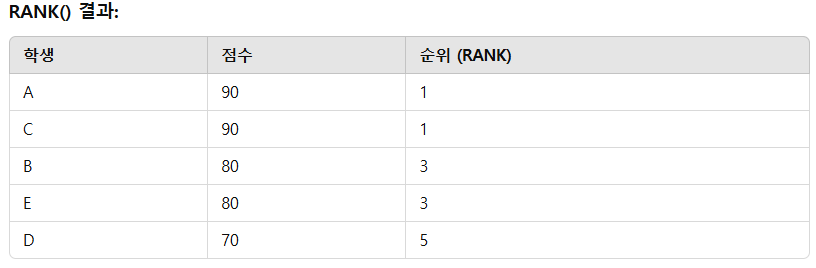
1) RANK() 함수
중복된 값이 있으면 순위에 "갭"이 생깁니다. 예를 들어, 두 학생이 같은 점수를 받으면 그 학생들은 같은 순위를 부여받고, 그 다음 순위는 두 칸이 밀려서 부여됩니다.
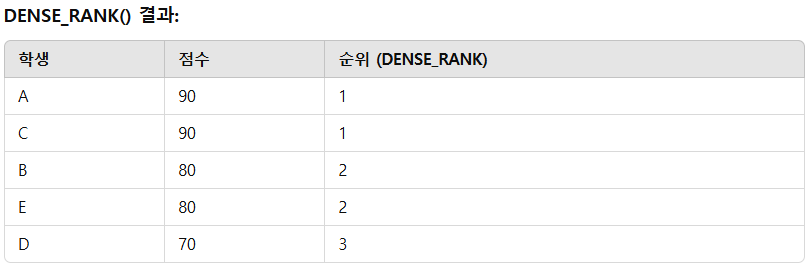
2) DENSE_RANK() 함수
중복된 값이 있어도 순위에 갭이 생기지 않습니다. 즉, 같은 점수의 학생들이 있으면 같은 순위를 부여하지만 그 다음 순위는 그 바로 다음 순위로 부여됩니다.
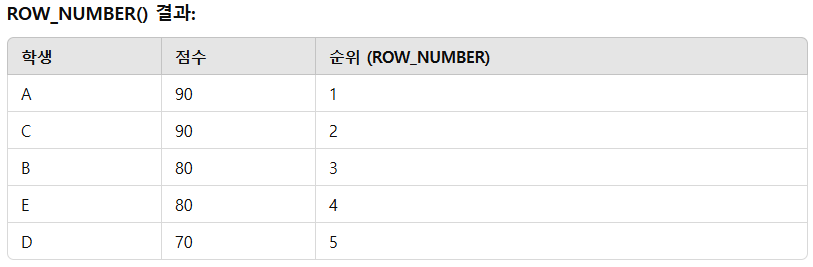
3) ROW_NUMBER()
중복된 값이 있어도 순위에 영향을 주지 않습니다. 중복 값이 있더라도 순위를 "단순히" 부여하므로, 항상 고유한 순위를 생성합니다.
2. 차이점 정리
- RANK : 중복 순위가 있으면, 중복 처리 하고 그 이후의 순위는 갭이 생김
- DENSE_RANK : 중복 순위가 있으면, 중복 처리 하고 그 이후의 순위는 갭이 없음(촘촘히,DENSE 하게 메김)
- ROW_NUMBER: 중복값이 있어도 고유한 순위 부여
| 함수 | 중복 순위 취급 여부 | 순위 부여 방법 | 갭 여부 | 예시 (90점 2명, 80점 2명) |
|---|---|---|---|---|
| RANK() | 중복 순위 취급 | 동일 순위 부여 후, 그 뒤 순위 건너뛰기 | 갭 있음 | 1, 1, 3, 3, 5 |
| DENSE_RANK() | 중복 순위 취급 | 동일 순위 부여 후, 순위 연속 부여 | 갭 없음 | 1, 1, 2, 2, 3 |
| ROW_NUMBER() | 중복 순위 취급 안함 | 각 행에 고유 번호 부여 | 없음 | 1, 2, 3, 4, 5 |
3. SQL 구문 예시
SELECT
employee_id,
salary,
RANK() OVER (ORDER BY salary DESC) AS salary_rank
-- DENSE_RANK() OVER (ORDER BY salary DESC) AS salary_rank2
-- row_number() over (order by salary desc) as salary_rank3
FROM employees;

질문 없는 성장은 없다. 3년차 데이터 분석가