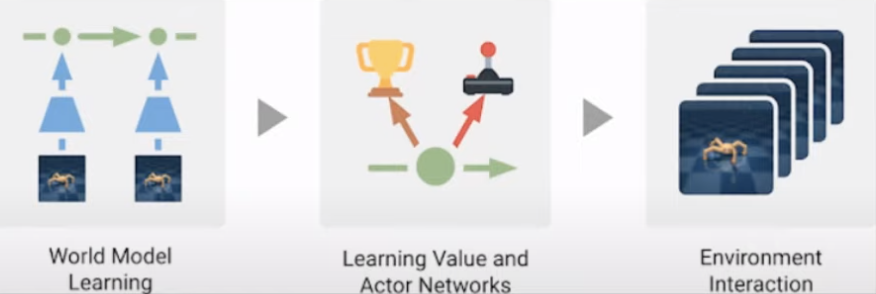
월드모델에 비해 개선된 점
1. Value function (allowing farsighted behaviors)
2. Backpropagation
3. Emphasis on imagination
Dreamer란 모델은
과거 data로부터 World model을 학습한 이후
해당 모델에서 예측한 내용을 토대로
미래 reward를 예측하는 value network와
action을 선택하는 action network를 학습한다.
그러면 실제로 environment 와 interaction을 할 때는
actor network를 통해서 action을 predict하게 된다.
Background
- Artificial agent가 목표를 달성하기 위해 행동을 선택할 수 있는 방법에 대한 연구는 강화 학습(RL)의 활용으로 인해 상당 부분 급속한 진전을 이루고 있습니다.
- 시행착오를 통해 성공적인 행동을 예측하는 RL에 대한 model-free 접근 방식, DeepMind의 DQN은 아타리 게임을 할 수 있고 AlphaStar는 스타크래프트 II에서 세계 챔피언을 이길 수 있습니다.
하지만, 많은 양의 환경 상호 작용이 필요하므로 실제 시나리오에 대한 유용성이 제한됩니다.
- 반대로 model-baed RL 접근 방식은 환경의 단순화된 모델을 추가로 학습합니다. 이 세계 모델을 통해 에이전트는 잠재적인 행동 시퀀스의 결과를 예측할 수 있으며, 이를 통해 새로운 상황에서 정보에 입각한 결정을 내릴 수 있으므로 목표 달성에 필요한 시행착오를 줄일 수 있습니다.
- 과거에는, 정확한 세계 모델을 배우고 성공적인 행동을 배우기 위해 그것들을 활용하는 것이 어려웠습니다. 우리의 심층 계획 네트워크(PlaNet)와 같은 최근 연구는 이미지에서 정확한 세계 모델을 학습하여 이러한 경계를 강화했습니다.
하지만 여전히 모델 기반 접근 방식은 여전히 비효율적이거나 계산 비용이 많이 드는 계획 메커니즘으로 인해 지연되어 어려운 작업을 해결하는 능력을 제한하고 있습니다.
오늘은 이미지에서 World Model을 학습하고 이를 사용하여 먼 미래를 내다보는 행동을 학습할 수 있는 RL 에이전트인 DeepMind와 우리 팀의 공동 작업인 Dreamer를 소개합니다.
- Dreamer는 원시 이미지에서 압축 모델 상태를 계산하고 모델 예측을 통해 역전파를 사용하여 예측된 시퀀스에서 병렬로 효율적으로 학습할 수 있습니다.
- 이 접근 방식을 통해 에이전트는 원시 이미지 입력이 제공될 때 20개의 연속 제어 작업에서 인상적인 성능, 데이터 효율성 및 계산 시간을 달성할 수 있습니다.
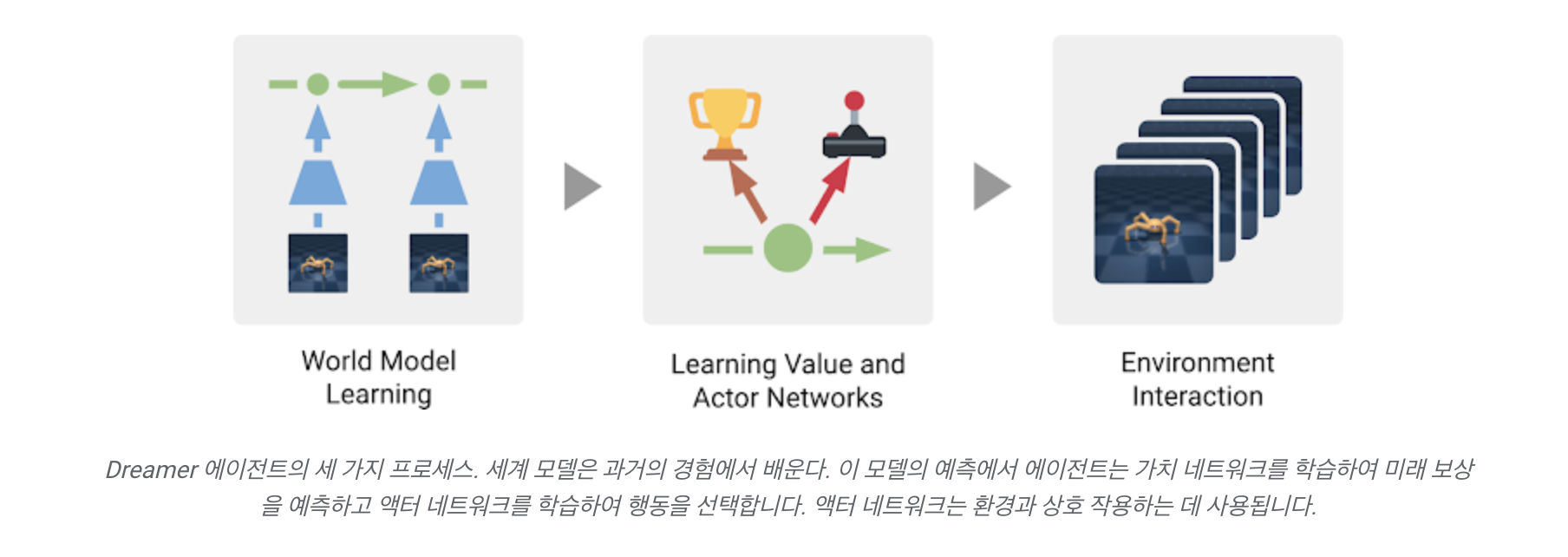
Dreamer 는 어떻게 작동할까?
세 가지 process 로 구성
-
월드모델 학습
과거 이미지와 action 데이터를 활용해서 reward를 예측하고 이미지 데이터를 재구성하는 과정에서 보다 latent한 compact model state 계산 -
Learning behavior in imagination
학습한 월드모델로 부터 미래 행동들을 예측하고 그것을 바탕으로 보다 long horizontal한 long sighted된 행동을 학습
이를 위해 먼저 예측한 미래의 각 상태에 대한 reward와 가치를 학습하고 그 이후 actor network 를 통해 backpropagation을 하면서 높은 reward와 가치를 줄 것으로 기대되는 최적의 action을 예측 -
Act in the environment 새로운 경험을 수집하기 위해 환경에서 학습된 행동 실행
실제 환경과 상호작용할 수 있는 action을 제안
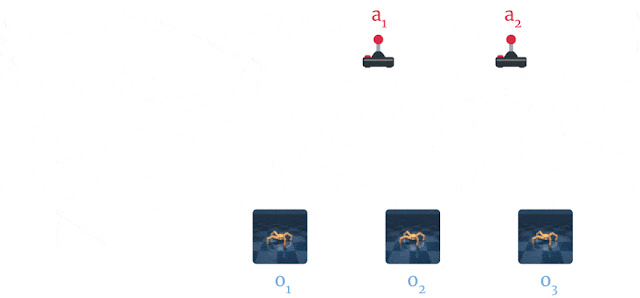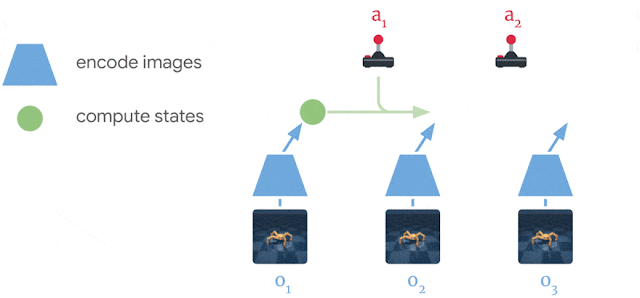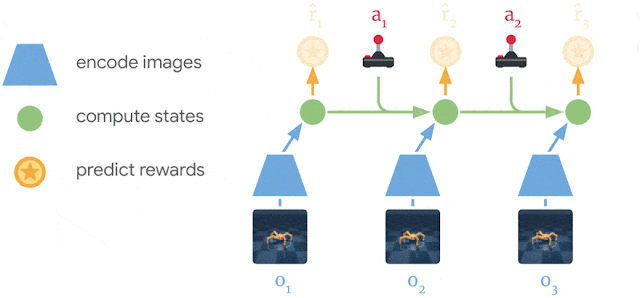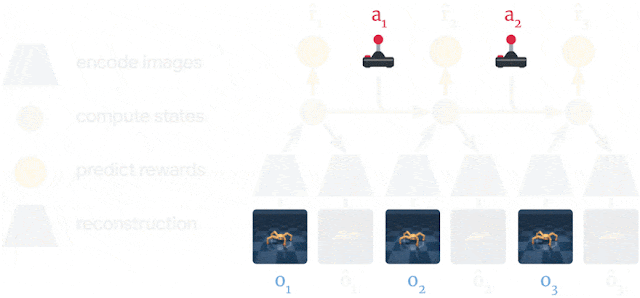
PlaNet World Model 사용의 장점
- 계산 효율성 증가
이미지 대신 압축 모델 상태를 사용하여 미리 예측하여 단일 GPU에서 수천 개의 시퀀스를 병렬로 예측 - 정확한 장기 비디오 예측을 위한 일반화 개선
모델의 작동방식을 더 잘 이해하기 위해 DeepMind Control Suite 및 DeepMind Lab 환경의 예에서 볼 수 있듯이 압축 모델 상태를 이미지로 다시 디코딩하여 예측된 시퀀스를 시각화할 수 있습니다.
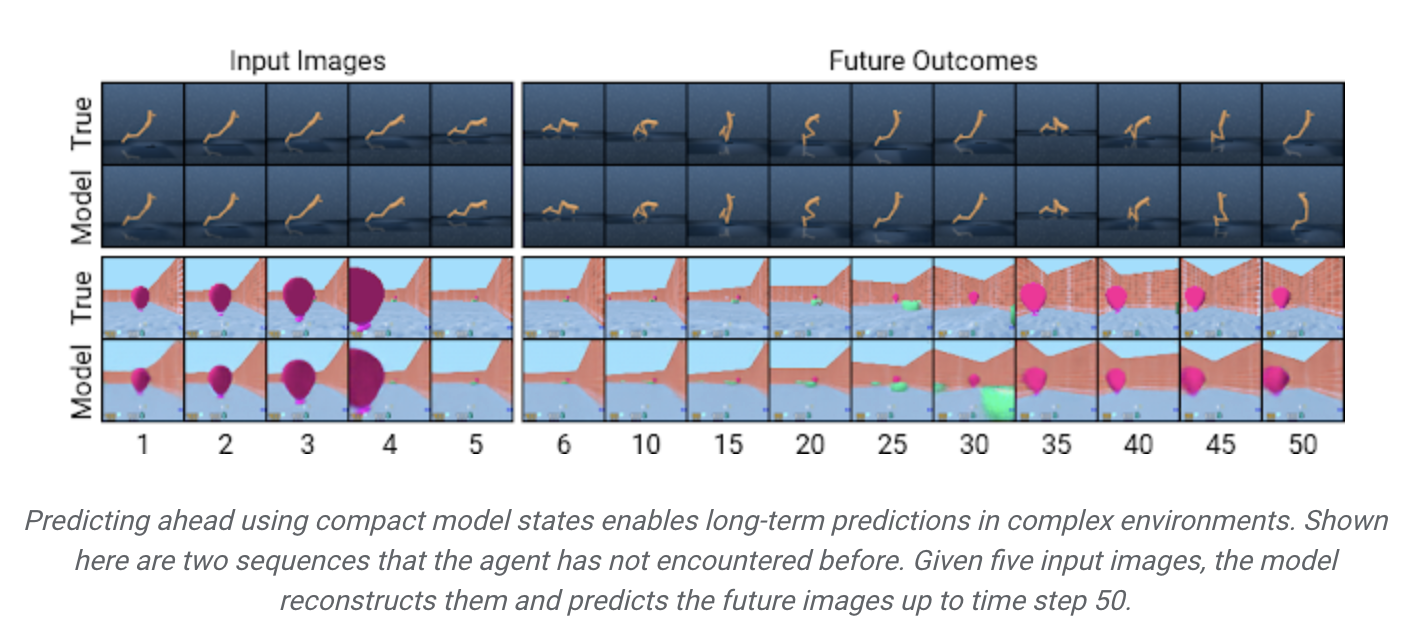
Efficient Behavior Learning
이전에 개발된 모델 기반 에이전트
- 일반적으로 많은 모델 예측을 통해 계획하거나, 기존 모델이 없는 기술을 재사용하기 위해 시뮬레이터 대신 월드 모델을 사용하여 작업을 선택합니다.
- 두 설계 모두 계산이 까다롭고 학습된 세계 모델을 완전히 활용하지는 못합니다.
- 게다가, 강력한 세계 모델조차도 정확하게 예측할 수 있는 범위가 제한되어 이전의 많은 모델 기반 에이전트를 근시안적으로 만듭니다.
Dreamer은 세계 모델의 예측을 통해 역전파(backpropagation)를 통해 value network와 actor network를 학습함으로써 이러한 한계를 극복합니다.
Dreamer은 예측된 상태 시퀀스를 통해 보상의 기울기를 거꾸로 전파하여 성공적인 행동을 예측하기 위해 actor network를 효율적으로 학습합니다. 이는 model-free 접근 방식에서는 불가능합니다.
이를 통해 Dreamer는
1. 행동의 작은 변화가 미래에 예측되는 보상에 어떤 영향을 미치는지 알려주고
2. 보상을 가장 많이 증가시키는 방향으로 행위자 네트워크를 개선할 수 있습니다.
3. 예측 범위를 넘어서는 보상을 고려하기 위해 가치 네트워크는 각 모델 상태에 대한 미래 보상의 합계를 추정합니다.
4. 그런 다음 보상과 가치가 역전파되어 액터 네트워크를 개선하여 개선된 작업을 선택합니다.
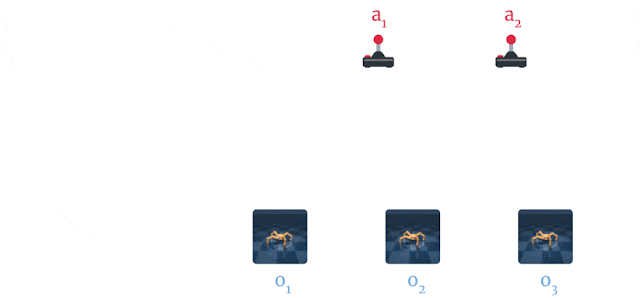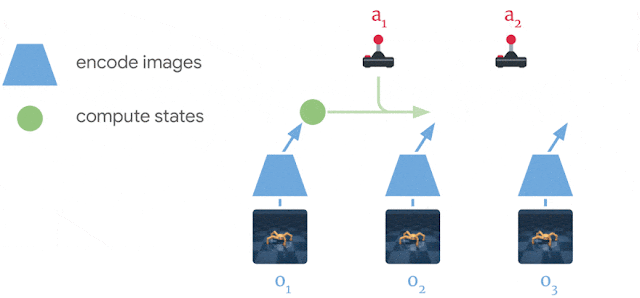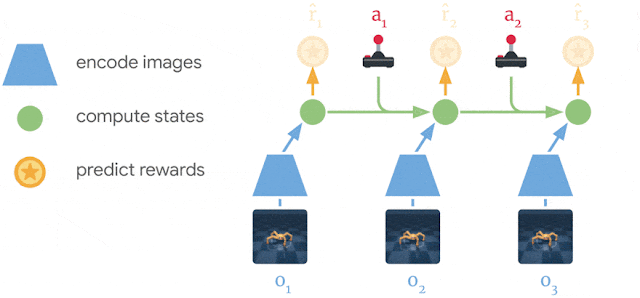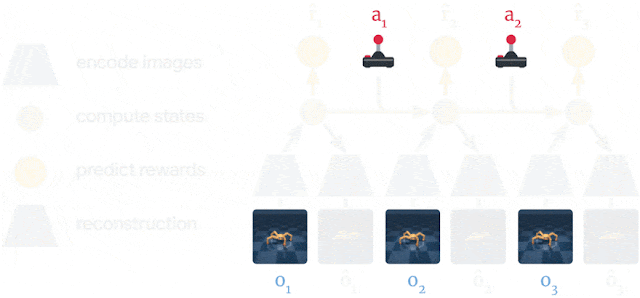
Dreamer는 PlaNet 과 좀 다르다.
PlaNet
- 환경의 주어진 상황에서 다양한 작업 시퀀스에 대한 많은 예측 중에서 최상의 작업을 검색
Dreamer - 계획과 행동을 분리함으로써 이 값비싼 검색을 보조
- 행위자 네트워크가 예측 시퀀스에 대해 훈련되면 추가 검색 없이 환경과 상호 작용하기 위한 작업을 계산
- Dreamer는 가치 함수를 사용하여 계획 지평선 너머의 보상을 고려하고 효율적인 계획을 위해 역 전파를 활용
Performance on Control Tasks
Dreamer vs PlaNet
Dreamer의 성능을
이전의 최고로 손꼽히는 model-based agent인 PlaNet의 성능, 인기 있는 model-free agent인 A3C 및 model-free RL의 여러 발전을 결합한 이 벤치마크인 D4PG의 현재 최고의 model-free agent와 비교
지속적인 행동과 이미지 입력을 통해 20개의 다양한 작업에 대한 표준 벤치마크에서 Dreamer를 평가했습니다.
- 작업에는 다양한 시뮬레이션 로봇의 이동뿐만 아니라 물체의 균형을 맞추고 잡는 것이 포함
- 이 작업은 RL 에이전트에게 충돌을 예측하기 어려운 문제, 희박한 보상, 혼돈 역학, 작지만 관련 있는 물체, 높은 자유도 및 3D 관점을 포함하여 다양한 과제를 제기하도록 설계됨
결과:
-
model based agent는 시뮬레이션 내 28시간에 해당하는 500만 프레임 미만에서 효율적으로 학습
model free agent는 더 천천히 학습하고 시뮬레이션 내 23일에 해당하는 1억 개의 프레임이 필요 -
20개 작업의 벤치마크에서 Dreamer는 786과 비교하여 평균 823점으로 최고의 모델 프리 에이전트(D4PG)를 능가
-
동시에 20배 적은 환경 상호 작용에서 학습
-
또한 거의 모든 작업에서 이전에 가장 우수했던 모델 기반 에이전트(PlaNet)의 최종 성능을 능가
-
Dreamer 교육을 위한 16시간의 계산 시간은 다른 방법에 필요한 24시간보다 적습니다.
4개 에이전트의 최종 성능은 다음과 같습니다
연속 제어 작업에 대한 주요 실험 외에도, 우리는 Dreamer의 일반성을 별개의 동작이 있는 작업에 적용하여 입증합니다. 이를 위해 반응적 행동과 장기적 행동, 공간 인식 및 시각적으로 더 다양한 장면에 대한 이해가 모두 필요한 아타리 게임과 딥마인드 랩 수준을 선택합니다. 결과적인 행동은 아래에 시각화되어 있으며, Dreamer는 이러한 더 어려운 작업을 효율적으로 해결하는 방법도 학습한다는 것을 보여줍니다:

Conclusion of Dream
- 세계 모델에 의해 예측된 시퀀스로부터 행동을 학습하는 것만으로도 이미지 입력으로부터 어려운 시각적 제어 작업을 해결할 수 있어 이전 모델이 없는 접근 방식의 성능을 능가할 수 있음을 보여줍니다.
- Dreamer는 콤팩트 모델 상태의 예측된 시퀀스를 통해 값 그레이디언트를 역 전파하여 학습 행동이 성공적이고 강력하여 연속적이고 이산적인 제어 작업의 다양한 모음을 해결한다는 것을 보여줍니다.
- Dreamer가 더 나은 표현 학습, 불확실성 추정치를 사용한 방향 탐색, 시간적 추상화 및 다중 작업 학습을 포함하여 강화 학습의 한계를 더욱 밀어붙일 수 있는 강력한 기반을 제공합니다.
출처
