외부에 진실이 있다고 하더라도 그것을 내부에서 어떻게 표상할 것인가에 따라 우리의 인지와 판단이 달라진다는 것을(Mental Model) 전제로 월드모델이 나타났다.
World Model 월드모델
월드모델 background
- RNN 같은 경우, 사이즈가 커지게 되면 hyperparameter 숫자가 많아지면서 트레이닝 하기 어렵고 vanishing gradient (학습한 것을 잊어버림) 문제가 발생한다.
- 에이전트가 지속적으로 running 할 때, 강화학습 같은 경우 credit assignment 문제가 심각하다. 어떻게 해결할 수 있을까?
실제 인지구조에서 보고 외부 모델을 압축해서 가져오고 그것을 이용해서 학습하면 될까? 실제 상황에서도 working 하는가?
- 커다란 RNN 기반의 에이전트를 학습할 수 있을까?
- Dividing the agents into
- Larger world model: Unsupervised learning. Not sacrificing capacity and expressiveness (iterate 빠르게, policy 심플하게 해서 강화학습의 약점보완)
- Smaller controller model: VAE를 통해 보이는 것만 가져와서 space가 작아짐 -> credit을 주기 편함, 각각 task 마다 policy가 달라짐 -> 테스크별로 policy를 compact 하게 학습할 수 있음
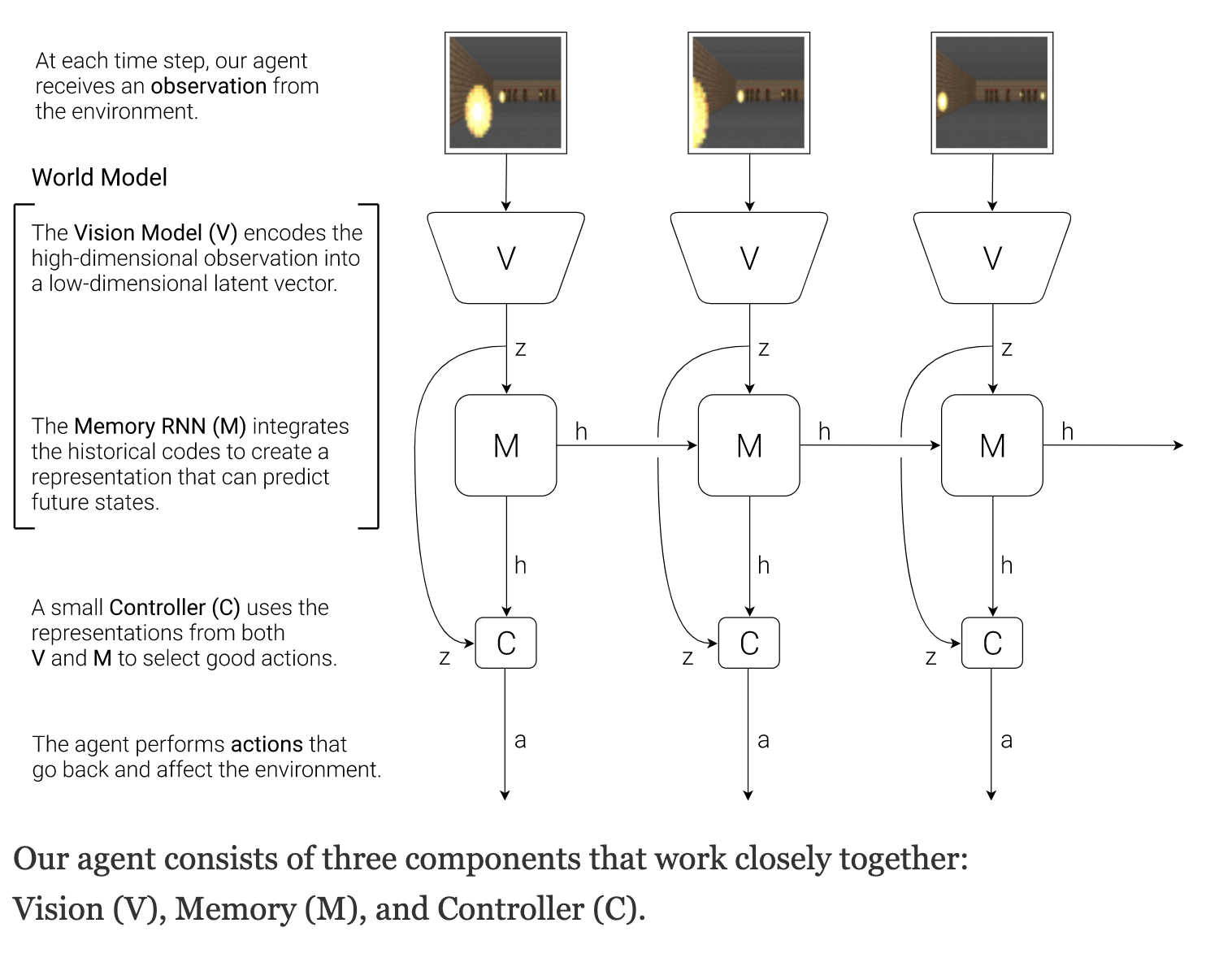
1. Vision
VAE 사용
latent space에 우리가 보고 있는 세상을 압축해서 넣고 재현
- High dementional observation을 통해 차원이 낫게 VAE를 이용해 encoding - Z - decoding
- z 라고 하는 Latent space 커다란 이미지에 들어가있는 representation을 압축하고 추상적으로 만들어서 보관을 할 수 있다.
잘 조정을 하면 구체적으로 에이전트가 뭘 보고 있는지 시각화 할 수 있다.
2. Memory
MDN-RNN Model 사용
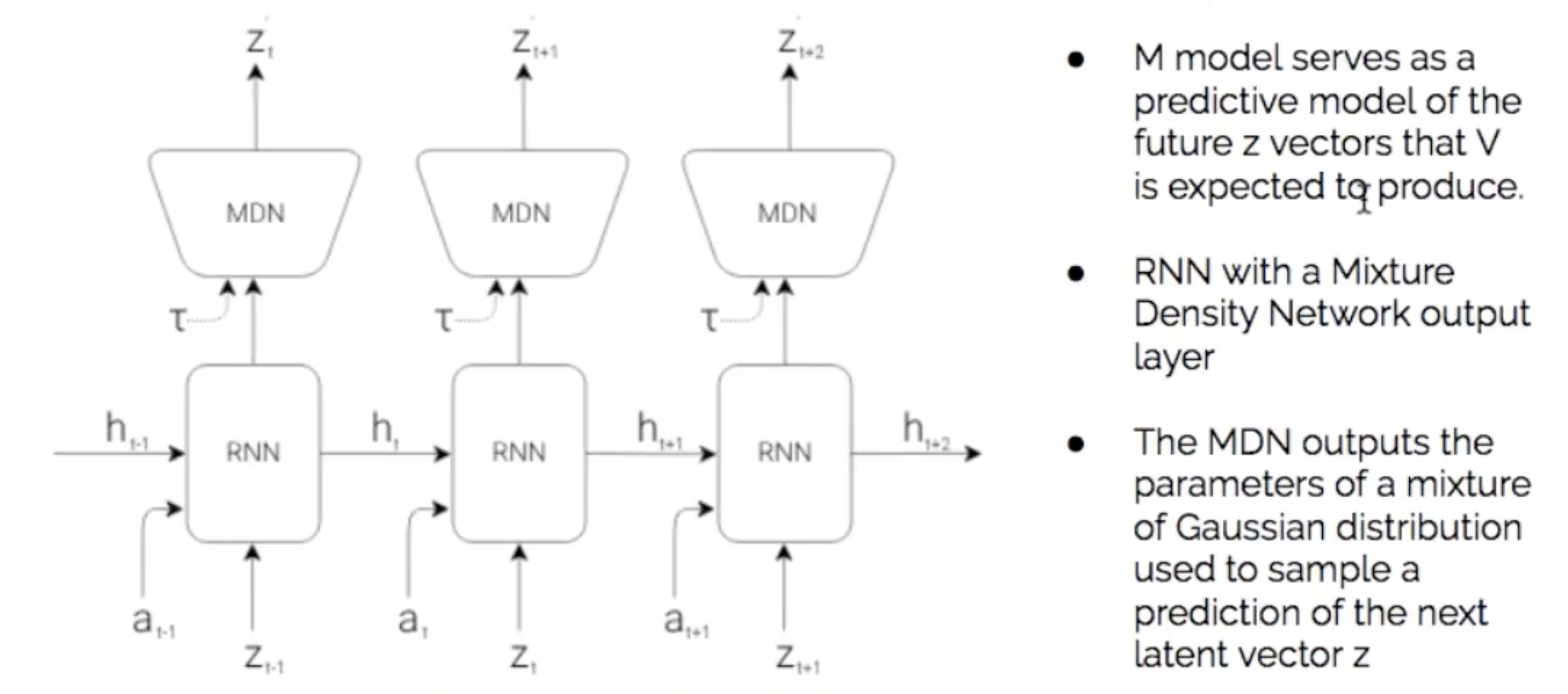
MDN
- 비지도학습의 한 종류로 데이터 클러스터링에 사용 (Gaussian mixture 이용)
- MDN은 다음 latent vector z의 예측을 샘플링하는 데 사용되는 Gaussian Mixture의 혼합 parameter 출력
Latent Space
- z = 보이는 것
- h = 과거의 행동, 상태를 추상화한 것에 대한 latent space
3. Controller
- RLL 사용
- 어떤 action을 만들어 낼거냐
리워드들을 합쳐서 최종목표가 되는 리워드를 maximize 해서 어떻게 하면 보여줄 수 있을까


장단점




출처
World Models

배낭여행자 도로시, 주변을 살피며 걷는 중입니다. (소개글을 참고해 주세요 찡긋)