매크로 함수
#define 함수명(보통 대문자로 쓰는 것 같음)(인수) (함수식)C 코드에서 앞에 #을 달고 쓰게되면 전처리기 단계에서 해석하고 이를 소스코드로 번역한다.
#include <stdio.h> //맨날맨날 쓰던 이친구처럼사용하는 이유
함수는 호출될 때 스택영역의 메모리를 사용하는데 매크로 함수는 이 단계를 전처리기 단계에서 이미 소스코드로 번역하므로 뛰어넘을 수 있다. 그러므로 메모리 낭비를 줄이고 실행속도를 빠르게 할 수 있다.
그러나 단점으로는 실행파일의 크기가 커지고 재귀호출이 불가능해진다.
유의해야 할 점으로는 일반적인 함수와 연산 순서가 달라질 수 있으므로 괄호를 잘 사용해야 한다는 것이다.
예시 여기에서 가져옴
#include <stdio.h>
#define SQR(X) X*X
#define PRT(X) printf("계산 결과는 %d입니다.\n", X)
int main(void)
{
int result;
int x = 5;
result = SQR(10);
PRT(result); //100
result = SQR(x);
PRT(result); //25
result = SQR(x+3);
PRT(result); //23. 5 + 3 * 5 + 3 = 23
return 0;
} 매크로 함수의 연산자 예시의 출처
#
#연산자는 매크로 함수의 대체 리스트 안의 인수 앞에 사용하여, 토큰을 문자열로 변환시켜준다.
해당 토큰은 실인수로 치환되면서 양쪽에 위치한 큰따옴표("")를 포함해 그대로 문자열 상수로 변환된다.
#연산자를 사용하면 문자열 안에 매크로 함수로 전달된 인수를 포함시킬 수 있다.
#include <stdio.h>
#define ADD1(x,y) x + y
#define ADD2(x,y) #x "+" #y //문자열로 바꿔주는 연산자 #
int main()
{
printf("매크로 함수(ADD1) : %d\n", ADD1(10, 20)); //30
printf("매크로 함수(ADD2) : %s\n", ADD2(10, 20)); //10+20
return 0;
}##
##연산자는 두 개의 토큰을 하나의 토큰으로 결합해 주는 선행처리기 연산자이다.
이 연산자는 함수 같은 매크로뿐만 아니라 객체 같은 매크로의 대체 리스트에도 사용할 수 있다.
이 연산자를 사용하면 변수나 함수의 이름을 프로그램의 런타임에 정의할 수 있다.
#include <stdio.h>
#define CONCAT(x,y,z) x ## y ## z
int main()
{
printf("매크로 함수(CONCAT) : %d\n", CONCAT(10, 20, 30)); //102030
return 0;
}묵시적 가용 리스트에서의 매크로 함수
#define
#define CHUNKSIZE (1<<12) 와 같은 형태로 매번 선언하기 귀찮고 간단한 내용들을 define 이라는 매크로 함수에 담아서 미리 선언한다.
#ifdef
#ifdef와 #endif는 C에서 조건부 컴파일(conditional compilation)을 지원하는 전처리 지시문이다. 이러한 지시문을 사용하면 코드 일부를 컴파일하는 것을 제어하거나 포함하는 조건을 지정할 수 있다.
#ifdef (if defined)
#ifdef 지시문은 특정한 매크로가 정의되어 있는지를 확인하는데 사용된다. 만약 해당 매크로가 정의되어 있다면, 그 다음에 오는 코드 블록을 컴파일한다.
예를 들어, 다음은 DEBUG 매크로가 정의되어 있는 경우에만 코드 블록을 컴파일하는 예이다:
#ifdef DEBUG
// 디버깅 코드
printf("Debugging is enabled.\n");
#endif#endif (end if)
#endif 지시문은 조건부 컴파일 블록의 끝을 나타낸다. #ifdef와 함께 사용되어, 조건부 컴파일 블록의 끝을 표시하고 다음 코드를 다시 정상적으로 컴파일한다.
#ifdef와 #endif는 조건부 컴파일 지시문을 사용하여 특정 상황에서 코드를 활성화 또는 비활성화할 때 유용하다. 이를 통해 디버깅 메시지를 포함하거나 특정 플래그 또는 환경 변수에 따라 코드를 다르게 컴파일할 수 있다.
묵시적 가용 리스트에서 경계태그를 사용하는 이유
묵시적 가용 리스트에서 만약 footer를 사용하지 않고 header만 사용한다면, 어떤 블록의 헤더에서 그 다음 블록의 헤더의 위치는 알 수 있지만, 그 이전 블록의 헤더의 위치는 알기 어렵다.
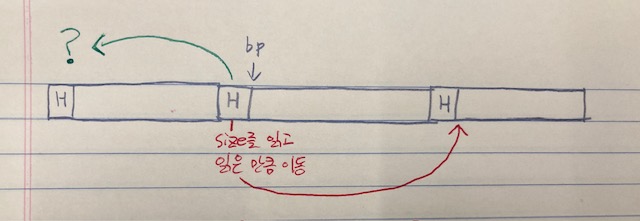
그렇기 때문에 header만 사용하는 상태에서는 그 이전 블록의 할당여부를 알기 위해서 header를 참조하기 위해서, 현재 블록의 bp를 기억하고 heap영역의 맨 앞에서부터 현재 블록의 bp가 나올때까지 header를 탐색한 후, 직전에 탐색했었던 header를 통해 size와 할당여부를 알아내야 한다.
이는 곧 heap영역이 클수록 시간이 오래걸리는 O(N)의 시간복잡도를 가진다.
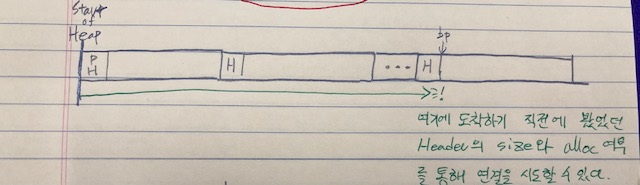
footer를 사용하게 되면 이전 블록의 size와 가용상태를 확인하기 위해선 bp의 두 칸 앞에 있는 이전 블록의 footer를 참고하면 되므로 상수의 시간복잡도가 된다.
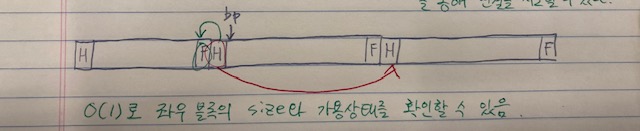
여기에서 더 나아가, 이전블록의 footer가 필요한 경우는 이전 블록이 free한 상태일 뿐이라는 점에서 경계태그를 최적화 할 수 있다.
현재 블록의 헤더에 현재 블록의 가용상태 + 이전 블록의 가용상태를 저장하게 한다면, 할당된 블록들은 footer가 필요없어지고 footer만큼의 공간을 데이터를 위해 사용할 수 있게 되는 것이다.
단 free상태일때는 이전 블록의 사이즈를 알 필요가 있으므로 free상태일때는 여전히 footer가 필요하다.
교과서에 나와있는 예문에 next fit을 적용한 소스코드
/*
* mm-naive.c - The fastest, least memory-efficient malloc package.
*
* In this naive approach, a block is allocated by simply incrementing
* the brk pointer. A block is pure payload. There are no headers or
* footers. Blocks are never coalesced or reused. Realloc is
* implemented directly using mm_malloc and mm_free.
*
* NOTE TO STUDENTS: Replace this header comment with your own header
* comment that gives a high level description of your solution.
*/
#include <stdio.h>
#include <stdlib.h>
#include <assert.h>
#include <unistd.h>
#include <string.h>
#include "mm.h"
#include "memlib.h"
/*********************************************************
* NOTE TO STUDENTS: Before you do anything else, please
* provide your team information in the following struct.
********************************************************/
team_t team = {
/* Team name */
"team 4",
/* First member's full name */
"Jeong Dong-hwan",
/* First member's email address */
"dosadola@gmail.com",
/* Second member's full name (leave blank if none) */
"",
/* Second member's email address (leave blank if none) */
""
};
/* single word (4) or double word (8) alignment */
#define ALIGNMENT 8
/* rounds up to the nearest multiple of ALIGNMENT */
#define ALIGN(size) (((size) + (ALIGNMENT-1)) & ~0x7) //가장 가까운 더 큰 8의 배수로 사이즈를 올려주는 매크로 함수
//사이즈에 +7을 더한 후 ~111(=000)과의 AND연산을 통해 8 아래 수를 전부 지운다.
#define SIZE_T_SIZE (ALIGN(sizeof(size_t))) //size_t는 unsigned 32비트 정수(4바이트) => 8바이트
#define WSIZE 4 //word와 header, footer size = 4bytes
#define DSIZE 8 //double word size = 8bytes
#define CHUNKSIZE (1<<12) //sbrk 함수로 늘어나는 힙의 양 (2^12 byte). 이진수 1을 왼쪽으로 12칸 민다 1 -> 1000000000000
#define MAX(x,y) ((x) > (y)? (x) : (y))
#define PACK(size, alloc) ((size) | (alloc)) //size와 alloc을 OR연산자로 합치기. 이 함수에서 size에 alloc 여부를 저장하게 된다.
#define GET(p) (*(unsigned int *)(p)) //주소 p에서 word 읽기. void 포인터는 참조를 할 수 없고,
//이 할당기에선 주소를 word단위, 4byte씩 연산하기 때문에 unsigned int로 포인터 변환을 해서 가져옴
#define PUT(p, val) (*(unsigned int *)(p) = (val)) //주소 p에서 word 쓰기
#define GET_SIZE(p) (GET(p) & ~0x7) //주소 p에서 사이즈를 가져오는 매크로 함수
//0x7은 2진수로 111이고 ~111은 000이므로 GET(p)로 가져온 값에 마지막 3자리를 000으로 만드는 역할
#define GET_ALLOC(p) (GET(p) & 0x1) //주소 p의 마지막 자리와 1을 AND연산하여 1이면 할당됨, 아니면 가용상태라고 판단하기 위한 매크로 함수
#define HDRP(bp) ((char *)(bp) - WSIZE) //블록 포인터 bp를 이용해 header의 주소를 계산. header는 bp가 가리키는 곳 보다 4바이트 앞이기 때문에 WSIZE 만큼 빼준다.
#define FTRP(bp) ((char *)(bp) + GET_SIZE(HDRP(bp)) - DSIZE) //블록 포인터 bp를 이용해 footer의 주소를 계산.
//현재 블록의 크기만큼 뒤로 간 다음 8바이트 빼주면(앞으로 2칸 전진) footer의 주소를 알 수 있다.
//이 때 (char *)로 bp를 받는 이유는 그래야 1바이트씩 포인트 연산을 할 수 있기 때문
#define NEXT_BLKP(bp) ((char *)(bp) + GET_SIZE(((char *)(bp) - WSIZE))) //bp를 이용해 다음 블록의 주소를 계산. 지금 블록의 헤더에서 사이즈를 읽고 그 사이즈만큼 더함
#define PREV_BLKP(bp) ((char *)(bp) - GET_SIZE(((char *)(bp) - DSIZE))) //bp를 이용해 이전 블록의 주소를 계산. 이전 블록의 푸터에서 사이즈를 읽고 그 사이즈만큼 뺌
#define NEXT_FIT //next fit 방식 적용. 주석 처리하면 first fit으로 작동
/* global variable & functions */
static char* heap_listp; // 항상 prologue block을 가리키는 정적 전역 변수 설정
// static 변수는 함수 내부(지역)에서도 사용이 가능하고 함수 외부(전역)에서도 사용이 가능하다.
#ifdef NEXT_FIT // #ifdef ~ #endif를 통해 조건부로 컴파일이 가능하다. NEXT_FIT이 선언되어 있다면 밑의 변수를 컴파일 할 것이다.
static void* last_freep; // next_fit 사용 시 마지막으로 탐색한 free 블록을 가리키는 포인터이다.
#endif
static void* extend_heap(size_t words);
static void* coalesce(void* bp);
static void* find_fit(size_t asize);
static void place(void* bp, size_t newsize);
int mm_init(void);
void *mm_malloc(size_t size);
void mm_free(void* bp);
void *mm_realloc(void* ptr, size_t newsize);
/*
* mm_init - initialize the malloc package.
*/
int mm_init(void) {
if ((heap_listp = mem_sbrk(4 * WSIZE)) == (void*) -1) { //memlib.c 파일내의 mem_sbrk함수는 heap영역을 늘리는데에 실패하면 (void*)-1을 반환한다.
return -1;
}
PUT(heap_listp, 0); //alignment padding. 8바이트 정렬을 위해 사용하는 미사용 패딩
PUT(heap_listp + (1 * WSIZE), PACK(DSIZE, 1)); //prologue header. 프롤로그의 사이즈와 allocated를 나타내는 1을 담고 있다.
PUT(heap_listp + (2 * WSIZE), PACK(DSIZE, 1)); //prologue footer. 헤더와 동일해야 한다.
PUT(heap_listp + (3 * WSIZE), PACK(0, 1)); //Epilogue header
heap_listp += (2 * WSIZE); //heap_listp가 prologue footer를 가리키도록 조정
#ifdef NEXT_FIT //next fit 방식이라면
last_freep = heap_listp; //last_freep를 heap_listp와 일치시킴
#endif
if (extend_heap(CHUNKSIZE / WSIZE) == NULL) { //바로 CHUNKSIZE(2^12 byte) 만큼 heap을 확장해 초기 free블록을 생성.
return -1;
}
return 0;
}
static void* extend_heap (size_t words) { //word단위의 메모리를 인자로 받아서 힙을 늘려준다.
char* bp;
size_t size;
size = (words % 2 == 1) ? (words + 1) * WSIZE : words * WSIZE; //alignment를 유지하기 위해서 받은 워드를 짝수로 바꿈
if ((long)(bp = mem_sbrk(size)) == -1) { //메모리 확보에 실패했다면 NULL을 반환. bp 자체의 값, 즉 주소값이 32bit이므로 long으로 캐스팅
return NULL; //그리고 mem_sbrk 함수가 실행되어 heap영역이 확장되고 bp는 새로운 메모리의 첫 주소값을 가리킴
}
PUT(HDRP(bp), PACK(size, 0)); //free block header 에필로그 헤더를 새로운 free block header로 변경
PUT(FTRP(bp), PACK(size, 0)); //free block footer
PUT(HDRP(NEXT_BLKP(bp)), PACK(0, 1)); //new epilogue header
//주위 블록이 비었다면 연결하고 bp를 반환.
return coalesce(bp);
}
/*
* mm_malloc - Allocate a block by incrementing the brk pointer.
* Always allocate a block whose size is a multiple of the alignment.
*/
void *mm_malloc(size_t size) {
size_t asize; //수정된 블록의 크기
size_t extendsize; //알맞은 크기의 free블록이 없을 시 확장하는 사이즈
char *bp;
if (size == 0) { //size가 0인 요청은 무시
return NULL;
}
asize = ALIGN(size + SIZE_T_SIZE);
if ((bp = find_fit(asize)) != NULL) { //asize가 들어갈 수 있는 블록을 찾았다면
place(bp, asize); //배치 후 필요하다면 분할
return bp;
}
extendsize = MAX(asize, CHUNKSIZE);
if ((bp = extend_heap(extendsize / WSIZE)) == NULL) { //extend_heap이 실패시 NULL을 반환함
return NULL;
}
place(bp, asize); //위의 if문에서 실행한 extend_heap이 성공해서 heap이 늘어났다면 그 늘어난 공간에 할당함.
return bp;
}
/*
* mm_free - Freeing a block does nothing.
*/
void mm_free(void *bp) {
size_t size = GET_SIZE(HDRP(bp));
PUT(HDRP(bp), PACK(size, 0));
PUT(FTRP(bp), PACK(size, 0));
coalesce(bp);
}
static void* coalesce(void* bp) {
size_t prev_alloc = GET_ALLOC(FTRP(PREV_BLKP(bp))); //이전 블록의 가용상태 여부
size_t next_alloc = GET_ALLOC(HDRP(NEXT_BLKP(bp))); //이후 블록의 가용상태 여부
size_t size = GET_SIZE(HDRP(bp)); //현재 블록의 사이즈
//case 1. 인접 블록이 모두 할당중
if (prev_alloc && next_alloc) {
return bp;
}
//case 2. 다음 블록이 가용상태
else if (prev_alloc && !next_alloc) {
size += GET_SIZE(HDRP(NEXT_BLKP(bp))); //사이즈 = 현재 사이즈 + 이후 블록의 사이즈
PUT(HDRP(bp), PACK(size, 0)); //현재 헤더에 새롭게 구한 헤더 다시 쓰기
PUT(FTRP(bp), PACK(size, 0)); //다음 블록의 푸터에 새롭게 구한 푸터 다시 쓰기
}
//case 3. 이전 블록이 가용상태
else if (!prev_alloc && next_alloc) {
size += GET_SIZE(HDRP(PREV_BLKP(bp))); //사이즈 = 현재 사이즈 + 이전 블록의 사이즈
PUT(FTRP(bp), PACK(size, 0)); //현재 푸터에 새롭게 구한 푸터 다시 쓰기
PUT(HDRP(PREV_BLKP(bp)), PACK(size, 0)); //이전 블록의 헤더에 새롭게 구한 헤더 다시 쓰기
bp = PREV_BLKP(bp); //bp가 이전 블록의 bp를 가리키도록 수정
}
//case 4. 양쪽 블록 모두 가용상태
else {
size += GET_SIZE(HDRP(PREV_BLKP(bp))) + GET_SIZE(FTRP(NEXT_BLKP(bp))); //사이즈 = 현재 사이즈 + 이전 블록의 사이즈 + 다음 블록의 사이즈
PUT(HDRP(PREV_BLKP(bp)), PACK(size, 0)); //이전 블록의 헤더에 새롭게 구한 헤더 다시 쓰기
PUT(FTRP(NEXT_BLKP(bp)), PACK(size, 0)); //다음 블록의 푸터에 새롭게 구한 푸터 다시 쓰기
bp = PREV_BLKP(bp);
}
#ifdef NEXT_FIT
last_freep = bp; //현재 bp를 last_freep로 설정
#endif
return bp;
}
/*
* mm_realloc - Implemented simply in terms of mm_malloc and mm_free
*/
//이미 할당된 사이즈를 직접 건드리는 것이 아니라 요청한 사이즈만큼의 블록을 새로 메모리 공간에 만들고 현재의 블록을 반환하는 것이다.
//size에 해당 블록의 사이즈가 변경되길 원하는 사이즈를 담는다.
void *mm_realloc(void *ptr, size_t size) {
void *oldptr = ptr;
void *newptr;
size_t copySize;
newptr = mm_malloc(size);
if (newptr == NULL) {
return NULL;
}
copySize = GET_SIZE(HDRP(oldptr));
if (size < copySize) {//영역의 크기를 줄이는 것이라면 그냥 줄인다. 사라지는 공간의 데이터는 잘리게 된다.
copySize = size;
}
memcpy(newptr, oldptr, copySize); //늘린다면 예전 영역의 내용을 새 영역에 복사한다. oldptr부터 copySize까지의 데이터를 newptr부터 심는다는 뜻.
mm_free(oldptr); //예전 oldptr 영역은 free로 반환
return newptr;
}
static void* find_fit(size_t asize) {
//next fit 방식
#ifdef NEXT_FIT
void* bp;
void* old_last_freep = last_freep;
for (bp = last_freep; GET_SIZE(HDRP(bp));bp = NEXT_BLKP(bp)) {
if(!GET_ALLOC(HDRP(bp)) && (asize <= GET_SIZE(HDRP(bp)))) {
return bp;
}
}
for (bp = heap_listp; bp < old_last_freep; bp = NEXT_BLKP(bp)) {
if (!GET_ALLOC(HDRP(bp)) && (asize <= GET_SIZE(HDRP(bp)))) {
return bp;
}
}
last_freep = bp;
return NULL;
#else //first fit 방식
void *bp;
for (bp = heap_listp; GET_SIZE(HDRP(bp)) > 0; bp = NEXT_BLKP(bp)) { // heap_listp, 즉 prologue부터 탐색한다. 전에 우리는 heap_listp += (2 * WSIZE)를 해두었다.
if (!GET_ALLOC(HDRP(bp)) && (asize <= GET_SIZE(HDRP(bp)))) { // 할당된 상태가 아니면서 해당 블록의 사이즈가 asize보다 크다면 해당 블록에 할당이 가능하므로 곧바로 bp를 반환한다.
return bp;
}
}
return NULL; //맞는 영역 없음.
#endif
}
static void place(void* bp, size_t asize) {
size_t csize = GET_SIZE(HDRP(bp)); // 현재 할당할 수 있는 후보, 즉 실제로 할당할 free 블록의 사이즈
if ((csize - asize) >= (2*DSIZE)) { // 분할 할 수 있는 경우.
PUT(HDRP(bp), PACK(asize, 1)); // free블록의 최소 사이즈는 header 1word, footer 1word, payload 1word, padding 1word 로 총 4words = 8bytes이다.
PUT(FTRP(bp), PACK(asize, 1));
bp = NEXT_BLKP(bp);
PUT(HDRP(bp), PACK(csize - asize, 0));
PUT(FTRP(bp), PACK(csize - asize, 0));
} else {
PUT(HDRP(bp), PACK(csize, 1));
PUT(FTRP(bp), PACK(csize, 1));
}
}