분리 가용 리스트
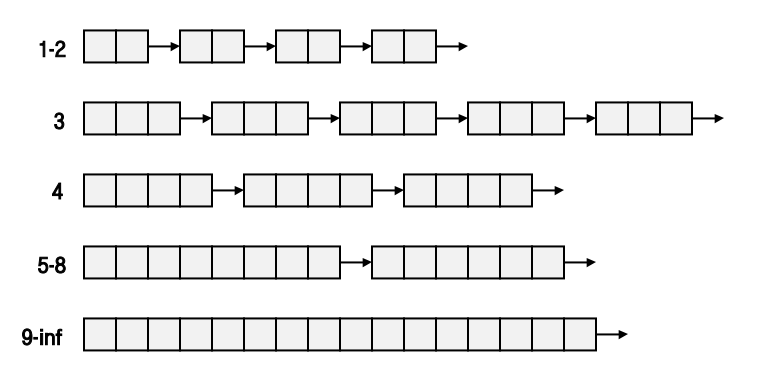
분리 가용 리스트는 저번에 만들었던 명시적 가용 리스트가 단일 가용블록 리스트를 사용하는 것과는 다르게 여러 개의 가용 블록 리스트를 사용해서 할당에 걸리는 시간을 더 줄이는 할당 방법이다.
모든 free block을 크기 클래스 라고 하는 동일 클래스의 집합으로 분리하는 것이 기본적인 아이디어이다.
간단한 분리 저장장치Simple Segregated Storage
각 크기 클래스를 위한 가용 리스트는 간단한 분리 저장장치로 동일한 크기의 블록들을 가지며, 각각은 크기 클래스의 가장 큰 원소의 크기를 갖는다.
17~32 까지의 크기를 위한 리스트는 전부 크기 32의 가용 블록을 갖는다는 이야기이다.
주어진 크기의 블록을 할당하기 위해선 우선 적절한 가용 리스트를 검색한다. 만일 리스트가 비어있지 않다면, 해당 리스트의 첫번째 블록 전체에 데이터를 할당한다. (분할하지 않는다.)
리스트가 비어있는 경우에는 운영체제로부터 추가적인 고정 크기의 메모리를 요청한 후 이를 동일한 크기의 블록으로 나누며 블록들을 함께 연결해서 새로운 가용 리스트를 만든다.
할당된 블록을 반환할 때에는 리스트의 가장 처음에 반환된 블록을 삽입한다.
장점
블록을 할당하고 반환하는 것이 모두 상수시간 연산이라 빠르다.
각 리스트 내의 메모리 블록이 모두 동일한 크기, 분할 없음, 연결 안 함 등의 조건이 결합되어 블록당 오버헤드가 거의 없다.
(오버헤드란 특정 기능을 실행하는데 필요한 시간, 메모리, 자원이 드는 현상을 말한다. 여기서 다루는 동적 메모리 할당기에서는 워드를 따로 할당해서 각 블록의 크기 또는 주소를 기록하거나, 반환된 블록끼리 연결하거나 하는데 드는 시간을 의미한다.)
각 메모리 블록이 동일한 크기의 블록을 가지기 때문에 블록의 크기는 주소로부터 추정할 수 있으며(사이즈 기록할 필요 없음), 연결작업이 필요없기 때문에 헤더에 가용여부를 기록할 필요도 없고 푸터도 쓸 이요가 없다. 할당과 반환 작업 역시 리스트의 시작부분에서만 삽입/삭제가 일어나기 때문에 리스트는 단일 연결만 해도 되므로 블록 내에 필요한 필드는 successor 포인터 뿐이다.
단점
내부 단편화와 외부 단편화에 취약하다. 가용블록이 분할되지 않기 때문에 내부 단편화가 일어나기 쉬우며, 가용 블록이 연결되지 않기 때문에 외부 단편화가 일어날 수 있다.
분리 맞춤Segregated Fits
가용리스트의 배열을 관리하는 방식이다. 각 가용 리스트는 크기 클래스에 연관되며 이 리스트는 명시적 또는 묵시적 리스트로 볼 수 있다.
블록을 할당할 때, 요청된 크기에 맞게 크기 클래스를 결정하고 해당 클래스의 가용 리스트를 first-fit 방식으로 탐색한다. 이후는 명시적 가용 리스트와 비슷하다.
분리 맞춤 방식은 빠르고 메모리 관리가 효율적이다. 검색시간은 줄어드는데, 그 이유는 검색이 힙의 특정 부분에 제한되어 일어나기 때문이다. 게다가 크기에 맞게 나누어진 여러 가용리스트 중 적당한 리스트를 찾아 first-fit으로 탐색하는 방식은 best-fit을 단순하게 구현화했다고도 생각할 수 있다.
코드 - 분리 맞춤
/*
* mm-naive.c - The fastest, least memory-efficient malloc package.
*
* In this naive approach, a block is allocated by simply incrementing
* the brk pointer. A block is pure payload. There are no headers or
* footers. Blocks are never coalesced or reused. Realloc is
* implemented directly using mm_malloc and mm_free.
*
* NOTE TO STUDENTS: Replace this header comment with your own header
* comment that gives a high level description of your solution.
*/
#include <stdio.h>
#include <stdlib.h>
#include <assert.h>
#include <unistd.h>
#include <string.h>
#include "mm.h"
#include "memlib.h"
/*********************************************************
* NOTE TO STUDENTS: Before you do anything else, please
* provide your team information in the following struct.
********************************************************/
team_t team = {
/* Team name */
"team 4",
/* First member's full name */
"Jeong Dong-hwan",
/* First member's email address */
"dosadola@gmail.com",
/* Second member's full name (leave blank if none) */
"",
/* Second member's email address (leave blank if none) */
""
};
/* single word (4) or double word (8) alignment */
#define ALIGNMENT 8
/* rounds up to the nearest multiple of ALIGNMENT */
//가장 가까운 더 큰 8의 배수로 사이즈를 올려주는 매크로 함수
//사이즈에 +7을 더한 후 ~111(=000)과의 AND연산을 통해 8 아래 수를 전부 지운다.
#define ALIGN(size) (((size) + (ALIGNMENT - 1)) & ~0x7)
//size_t는 unsigned 32비트 정수(4바이트) => 8바이트
#define SIZE_T_SIZE (ALIGN(sizeof(size_t)))
#define WSIZE 4 //word와 header, footer size = 4bytes
#define DSIZE 8 //double word size = 8bytes
#define LISTLIMIT 20 //list의 limit 설정
#define CHUNKSIZE (1<<9) //sbrk 함수로 늘어나는 힙의 양 (2^9 byte). 이진수 1을 왼쪽으로 9칸 민다.
#define MAX(x,y) ((x) > (y)? (x) : (y))
//size와 alloc을 OR연산자로 합치기. 이 함수에서 size에 alloc 여부를 저장하게 된다.
#define PACK(size, alloc) ((size) | (alloc))
//주소 p에서 word 읽기. void 포인터는 참조를 할 수 없고,
//이 할당기에선 주소를 word단위, 4byte씩 연산하기 때문에 unsigned int로 포인터 변환을 해서 가져옴
#define GET(p) (*(unsigned int *)(p))
#define PUT(p, val) (*(unsigned int *)(p) = (val)) //주소 p에서 word 쓰기
//주소 p에서 사이즈를 가져오는 매크로 함수
//0x7은 2진수로 111이고 ~111은 000이므로 GET(p)로 가져온 값에 마지막 3자리를 000으로 만드는 역할
#define GET_SIZE(p) (GET(p) & ~0x7)
//주소 p의 마지막 자리와 1을 AND연산하여 1이면 할당됨, 아니면 가용상태라고 판단하기 위한 매크로 함수
#define GET_ALLOC(p) (GET(p) & 0x1)
//블록 포인터 bp를 이용해 header의 주소를 계산. header는 bp가 가리키는 곳 보다 4바이트 앞이기 때문에 WSIZE 만큼 빼준다.
#define HDRP(bp) ((char *)(bp) - WSIZE)
//블록 포인터 bp를 이용해 footer의 주소를 계산.
//현재 블록의 크기만큼 뒤로 간 다음 8바이트 빼주면(앞으로 2칸 전진) footer의 주소를 알 수 있다.
//이 때 (char *)로 bp를 받는 이유는 그래야 1바이트씩 포인트 연산을 할 수 있기 때문
#define FTRP(bp) ((char *)(bp) + GET_SIZE(HDRP(bp)) - DSIZE)
//bp를 이용해 다음 블록의 주소를 계산. 지금 블록의 헤더에서 사이즈를 읽고 그 사이즈만큼 더함
#define NEXT_BLKP(bp) ((char *)(bp) + GET_SIZE(((char *)(bp) - WSIZE)))
//bp를 이용해 이전 블록의 주소를 계산. 이전 블록의 푸터에서 사이즈를 읽고 그 사이즈만큼 뺌
#define PREV_BLKP(bp) ((char *)(bp) - GET_SIZE(((char *)(bp) - DSIZE)))
//bp를 이용해서 free블록 내의 predeccessor 블록의 워드에 담긴 주소가 가리키는 곳으로 가는 이중포인터
#define PRED_FREEP(bp) (*(void**)(bp))
//bp를 이용해서 free블록 내의 successor 블록(한 칸 뒤)의 워드에 담긴 주소가 가리키는 곳으로 가는 이중포인터
#define SUCC_FREEP(bp) (*(void**)(bp + WSIZE))
/* global variable & functions */
// static 변수는 함수 내부(지역)에서도 사용이 가능하고 함수 외부(전역)에서도 사용이 가능하다.
// 항상 prologue block을 가리키는 정적 전역 변수 설정
static void* heap_listp;
static void* segragation_list[LISTLIMIT];
static void* extend_heap(size_t words);
static void* coalesce(void* bp);
static void* find_fit(size_t asize);
static void place(void* bp, size_t newsize);
static void removeBlock(void* bp);
static void insertBlock(void* bp, size_t size);
int mm_init(void);
void *mm_malloc(size_t size);
void mm_free(void *bp);
void *mm_realloc(void *ptr, size_t newsize);
/*
* mm_init - initialize the malloc package.
*/
int mm_init(void) {
//seglist의 포인터 전부 초기화
int list;
for (list = 0; list < LISTLIMIT; list++) {
segragation_list[list] = NULL;
}
//memlib.c 파일내의 mem_sbrk함수는 heap영역을 늘리는데에 실패하면 (void*)-1을 반환한다.
if ((heap_listp = mem_sbrk(4 * WSIZE)) == (void*) -1) {
return -1;
}
PUT(heap_listp, 0); //alignment padding.
PUT(heap_listp + (1 * WSIZE), PACK(DSIZE, 1)); //prologue header
PUT(heap_listp + (2 * WSIZE), PACK(DSIZE, 1)); //prologue footer
PUT(heap_listp + (3 * WSIZE), PACK(0, 1)); //epliogue header
//heap_listp를 prologue header의 위치로 초기화
heap_listp += (2 * WSIZE);
//바로 CHUNKSIZE(2^12 byte) 만큼 heap을 확장해 초기 free블록을 생성.
if (extend_heap(CHUNKSIZE/WSIZE) == NULL) {
return -1;
}
return 0;
}
//word단위의 메모리를 인자로 받아서 힙을 늘려준다.
static void* extend_heap (size_t words) {
char* bp;
size_t size;
//alignment를 유지하기 위해서 받은 워드를 짝수로 바꿈
size = (words % 2 == 1) ? (words + 1) * WSIZE : words * WSIZE;
//메모리 확보에 실패했다면 NULL을 반환. bp 자체의 값, 즉 주소값이 32bit이므로 long으로 캐스팅
//그리고 mem_sbrk 함수가 실행되어 heap영역이 확장되고 bp는 새로운 메모리의 첫 주소값을 가리킴
if ((long)(bp = mem_sbrk(size)) == -1) {
return NULL;
}
//에필로그 헤더를 새로운 free block header로 변경
PUT(HDRP(bp), PACK(size, 0)); //free block header
PUT(FTRP(bp), PACK(size, 0)); //free block footer
PUT(HDRP(NEXT_BLKP(bp)), PACK(0, 1)); //new epilogue header
//주위 블록이 비었다면 연결하고 bp를 반환.
return coalesce(bp);
}
/*
* mm_malloc - Allocate a block by incrementing the brk pointer.
* Always allocate a block whose size is a multiple of the alignment.
*/
void *mm_malloc(size_t size) {
//수정된 블록의 크기
size_t asize;
//알맞은 크기의 free블록이 없을 시 확장하는 사이즈
size_t extendsize;
char *bp;
//size가 0인 요청은 무시
if (size == 0) {
return NULL;
}
asize = ALIGN(size + SIZE_T_SIZE);
//asize가 들어갈 수 있는 블록을 찾았다면 배치 후 필요하다면 분할
if ((bp = find_fit(asize)) != NULL) {
place(bp, asize);
return bp;
}
//적당한 공간을 찾지 못했다면 heap을 (CHUNKSIZE) 또는 asize 중 더 큰 값만큼 늘려줌
extendsize = MAX(asize, CHUNKSIZE);
//extend_heap이 실패시 NULL을 반환함
if ((bp = extend_heap(extendsize / WSIZE)) == NULL) {
return NULL;
}
//위의 if문에서 실행한 extend_heap이 성공해서 heap이 늘어났다면 그 늘어난 공간에 할당함.
place(bp, asize);
return bp;
}
/*
* mm_free - Freeing a block does nothing.
*/
void mm_free(void *bp) {
size_t size = GET_SIZE(HDRP(bp));
PUT(HDRP(bp), PACK(size, 0));
PUT(FTRP(bp), PACK(size, 0));
coalesce(bp);
}
static void *coalesce(void *bp) {
//이전 블록의 가용상태 여부
size_t prev_alloc = GET_ALLOC(FTRP(PREV_BLKP(bp)));
//이후 블록의 가용상태 여부
size_t next_alloc = GET_ALLOC(HDRP(NEXT_BLKP(bp)));
//현재 블록의 사이즈
size_t size = GET_SIZE(HDRP(bp));
//case 1. 인접 블록이 모두 할당중
if (prev_alloc && next_alloc) {
insertBlock(bp, size);
return bp;
}
//case 2. 다음 블록이 가용상태
else if (prev_alloc && !next_alloc) {
//다음 블록을 리스트에서 제거
removeBlock(NEXT_BLKP(bp));
//사이즈 = 현재 사이즈 + 이후 블록의 사이즈
size += GET_SIZE(HDRP(NEXT_BLKP(bp)));
//현재 헤더에 새롭게 구한 헤더 다시 쓰기
PUT(HDRP(bp), PACK(size, 0));
//다음 블록의 푸터에 새롭게 구한 푸터 다시 쓰기
PUT(FTRP(bp), PACK(size, 0));
}
//case 3. 이전 블록이 가용상태
else if (!prev_alloc && next_alloc) {
//이전 블록을 리스트에서 제거
removeBlock(PREV_BLKP(bp));
//사이즈 = 현재 사이즈 + 이전 블록의 사이즈
size += GET_SIZE(HDRP(PREV_BLKP(bp)));
//bp를 이전블록으로 옮기고
bp = PREV_BLKP(bp);
PUT(HDRP(bp), PACK(size, 0));
PUT(FTRP(bp), PACK(size, 0));
}
//case 4. 양쪽 블록 모두 가용상태
else {
//이전, 이후 블록을 리스트에서 제거
removeBlock(PREV_BLKP(bp));
removeBlock(NEXT_BLKP(bp));
//사이즈 = 현재 사이즈 + 이전 블록의 사이즈 + 다음 블록의 사이즈
size += GET_SIZE(HDRP(PREV_BLKP(bp))) + GET_SIZE(FTRP(NEXT_BLKP(bp)));
//bp를 이전블록으로 옮기고
bp = PREV_BLKP(bp);
PUT(HDRP(bp), PACK(size, 0));
PUT(FTRP(bp), PACK(size, 0));
}
//새롭게 만든 free block의 bp를 리스트 안에 넣기
insertBlock(bp, size);
return bp;
}
/*
* mm_realloc - Implemented simply in terms of mm_malloc and mm_free
*/
//이미 할당된 사이즈를 직접 건드리는 것이 아니라 요청한 사이즈만큼의 블록을 새로 메모리 공간에 만들고 현재의 블록을 반환하는 것이다.
//size에 해당 블록의 사이즈가 변경되길 원하는 사이즈를 담는다.
void *mm_realloc(void *ptr, size_t size) {
void *oldptr = ptr;
void *newptr;
size_t copySize;
newptr = mm_malloc(size);
if (newptr == NULL) {
return NULL;
}
copySize = GET_SIZE(HDRP(oldptr));
//영역의 크기를 줄이는 것이라면 그냥 줄인다. 사라지는 공간의 데이터는 잘리게 된다.
if (size < copySize) {
copySize = size;
}
//늘린다면 예전 영역의 내용을 새 영역에 복사한다. oldptr부터 copySize까지의 데이터를 newptr부터 심는다는 뜻.
memcpy(newptr, oldptr, copySize);
//예전 oldptr 영역은 free로 반환
mm_free(oldptr);
return newptr;
}
//first-fit 방식. 해당 블록의 사이즈가 속할 수 있는 사이즈 범위를 가진 연결리스트를 탐색하고, 그 연결리스트 내에서 적절한 블록을 또 탐색한다.
static void* find_fit(size_t asize) {
void* bp;
int list = 0;
size_t searchSize = asize;
//LISTLIMIT = 20
while (list < LISTLIMIT) {
//bp가 마지막 연결리스트(19번째)에 도달(끝 지점에 도달했음)
//또는, searchsize가 1 이하(while 반복문을 돌면서 찾았다는 뜻)
//그리고 해당 사이즈의 연결 리스트가 존재할 때
if ((list == LISTLIMIT - 1) || (searchSize <= 1) && (segragation_list[list] != NULL)) {
//bp는 그 연결 리스트로 들어감
bp = segragation_list[list];
//리스트가 비어있지 않고, 사이즈가 현재 bp의 사이즈보다 크다면
while((bp != NULL) && (asize > GET_SIZE(HDRP(bp)))) {
//다음 블록으로 넘어감
bp = SUCC_FREEP(bp);
}
//리스트가 비어있지 않다면
if (bp != NULL) {
//할당하기에 알맞은 블록의 bp를 리턴함
return bp;
}
}
// seachsize를 2로 나눠가면서(shift 비트연산을 하면서) while문에서 적절한 사이즈를 가진 연결리스트를 찾도록 해준다.
searchSize >>= 1;
list++;
}
return NULL;
}
static void place(void* bp, size_t asize) {
// 현재 할당할 수 있는 후보, 즉 실제로 할당할 free 블록의 사이즈
size_t csize = GET_SIZE(HDRP(bp));
//할당하는 블록은 연결리스트에서 제거
removeBlock(bp);
// 분할 할 수 있는 경우.
//free블록의 최소 사이즈는 header 1word, footer 1word, pred 1word, succ 1word 로 총 4words = 16bytes이다.
if ((csize - asize) >= (2*DSIZE)) {
PUT(HDRP(bp), PACK(asize, 1));
PUT(FTRP(bp), PACK(asize, 1));
bp = NEXT_BLKP(bp);
PUT(HDRP(bp), PACK(csize - asize, 0));
PUT(FTRP(bp), PACK(csize - asize, 0));
coalesce(bp);
} else { //분할이 불가능한 경우
PUT(HDRP(bp), PACK(csize, 1));
PUT(FTRP(bp), PACK(csize, 1));
}
}
static void removeBlock(void *bp) {
int list = 0;
size_t size = GET_SIZE(HDRP(bp));
//지우고자 하는 블록의 사이즈가 속할 수 있는 사이즈 범위의 연결리스트 탐색
while ((list <LISTLIMIT - 1) && (size > 1)) {
size >>= 1;
list++;
}
//지울 블록에 다음 블록이 있을 때
if (SUCC_FREEP(bp) != NULL) {
//이전 블록도 있다면
if (PRED_FREEP(bp) != NULL) {
//이전블록과 다음블록을 서로 이어줌
PRED_FREEP(SUCC_FREEP(bp)) = PRED_FREEP(bp);
SUCC_FREEP(PRED_FREEP(bp)) = SUCC_FREEP(bp);
//이전 블록이 없다면
} else {
//다음 블록의 이전 블록을 없앰
PRED_FREEP(SUCC_FREEP(bp)) = NULL;
//리스트의 시작은 현재 bp의 다음블록이 된다.
segragation_list[list] = SUCC_FREEP(bp);
}
//지울 블록에 다음 블록이 없을 때
} else {
//이전 블록이 있다면
if (PRED_FREEP(bp) != NULL) {
//이전 블록의 다음블록을 없앰
SUCC_FREEP(PRED_FREEP(bp)) = NULL;
//이전 블록도, 다음 블록도 없다면
} else {
//리스트가 빈 리스트가 된다.
segragation_list[list] = NULL;
}
}
return;
}
static void insertBlock(void *bp, size_t size) {
int list = 0;
//블록들을 탐색하는 포인터
void *search_ptr;
//search ptr 바로 앞을 탐색하고 실제로 삽입할 곳을 가리키는 포인터
void *insert_ptr = NULL;
//추가하고자 하는 블록의 사이즈가 속할 수 있는 리스트를 찾는다.
while ((list < LISTLIMIT - 1) && (size > 1)) {
size >>= 1;
list++;
}
//적절한 사이즈의 연결리스트에서 넣을 수 있는 블록을 탐색
search_ptr = segragation_list[list];
//오름차순으로 저장하기 위해서 나보다 작은 블록은 넘기고 큰 블록을 만났을 때 멈추게 됨
//따라서 실제로 삽입하는 곳은 search_ptr보다 한 블록 앞(insert_ptr이 가리키는 곳)
while ((search_ptr != NULL) && (size > GET_SIZE(HDRP(search_ptr)))) {
//반복문이 한 번 돌때마다 search_ptr은 다음 포인터로 넘어가고 insert_ptr이 search_ptr의 값을 이어받는다.
insert_ptr = search_ptr;
search_ptr = SUCC_FREEP(search_ptr);
}
//더 큰 블록을 찾았을 때
if (search_ptr != NULL) {
//insert_ptr도 찾았다면
if (insert_ptr != NULL) {
//insert_ptr와 search_ptr 사이에 bp를 넣는다.
SUCC_FREEP(bp) = search_ptr;
PRED_FREEP(bp) = insert_ptr;
PRED_FREEP(search_ptr) = bp;
SUCC_FREEP(insert_ptr) = bp;
//insert_ptr를 찾을 수 없었다면 리스트의 맨 처음이라는 뜻
} else {
SUCC_FREEP(bp) = search_ptr;
PRED_FREEP(bp) = insert_ptr;
PRED_FREEP(search_ptr) = bp;
//bp는 연결리스트의 처음을 가리킴
segragation_list[list] = bp;
}
//더 큰 블록이 존재하지 않음
} else {
//insert_ptr이 있었다면 리스트의 가장 끝이라는 뜻
if (insert_ptr != NULL) {
SUCC_FREEP(bp) = NULL;
PRED_FREEP(bp) = insert_ptr;
SUCC_FREEP(insert_ptr) = bp;
//insert_ptr이 존재하지 않는다면 연결리스트를 만들어야 한다는 뜻
} else {
SUCC_FREEP(bp) = NULL;
PRED_FREEP(bp) = NULL;
//bp는 연결리스트의 처음을 가리킴
segragation_list[list] = bp;
}
}
return;
}