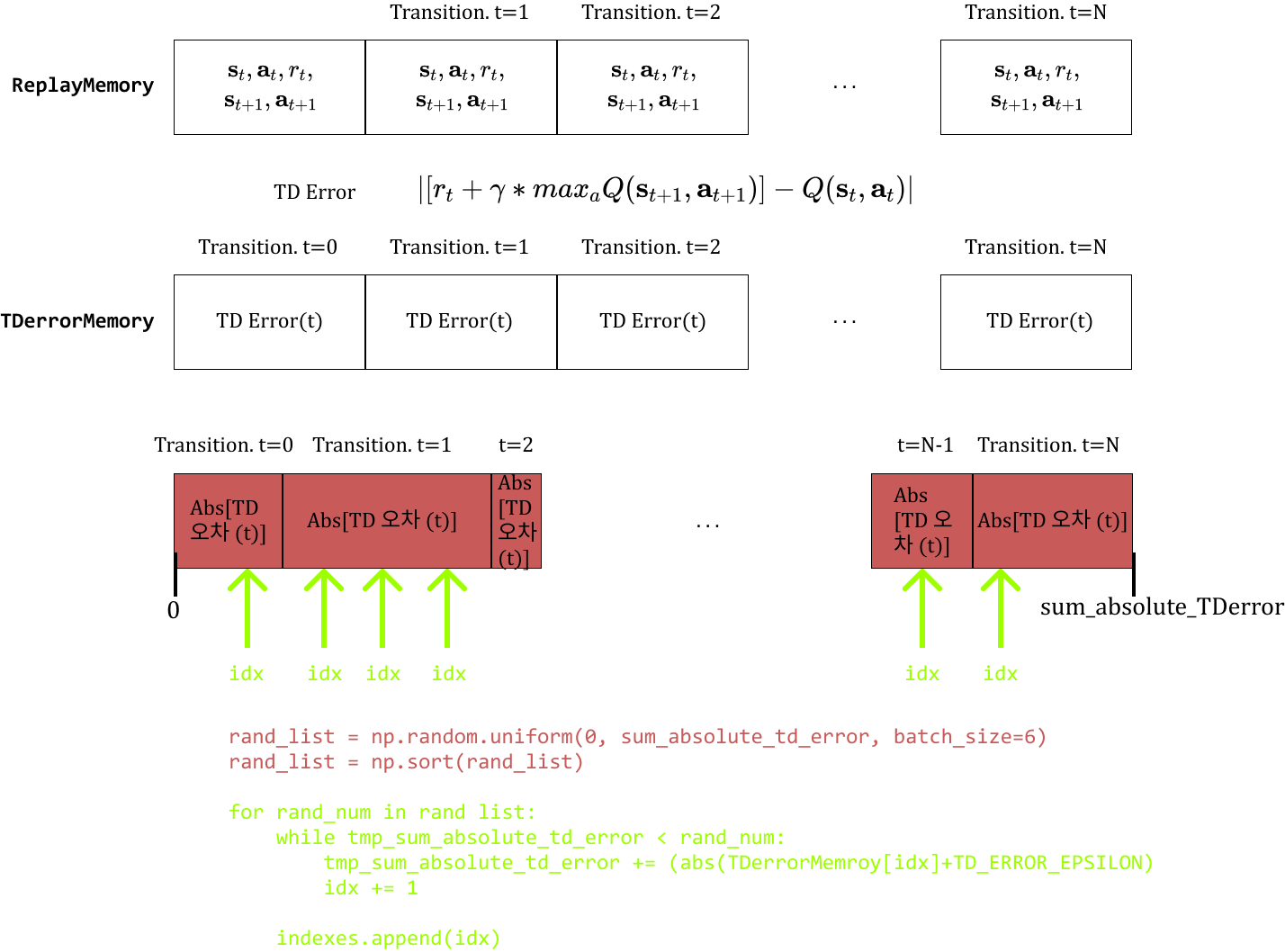
Prioritized Experience Replay
PER: Q-러닝이 제대로 지나가지 않은 state의 transition을 우선적으로 학습시키는 기법.
우선순위를 매기는 기준은 Value 함수의 벨만 방정식의 절댓값 오차.
TD Error가 큰 transition을 우선적으로 Experience Replay에서 노출시켜서 Value Function 신경망의 Output Error를 최적화.
-
Error 저장법
-Binary Tree
-queue -
필요한 Memory class
-ReplayMemory: 지금까지 transition을 저장하는 데 사용한 Memory class
-TDErrorMemory: 별도로 오차를 저장할 Memory class
TD Error를 확률 삼아 미니배치 크기만큼 transition 꺼내기
- 먼저
ReplayMemory의 각 요소 값의 절대합인sum_absolute_TDerror를 계산. - 그 다음
[0, sum_absolute_TDerror]구간 안에서 uniform 분포를 따라 mini batch(=32) 개수만큼 난수 생성 - 이 난수에 해당하는
TDerrorMemory에서index들을 담고 그 index에 해당하는 transition을 Experience Replay에 사용.
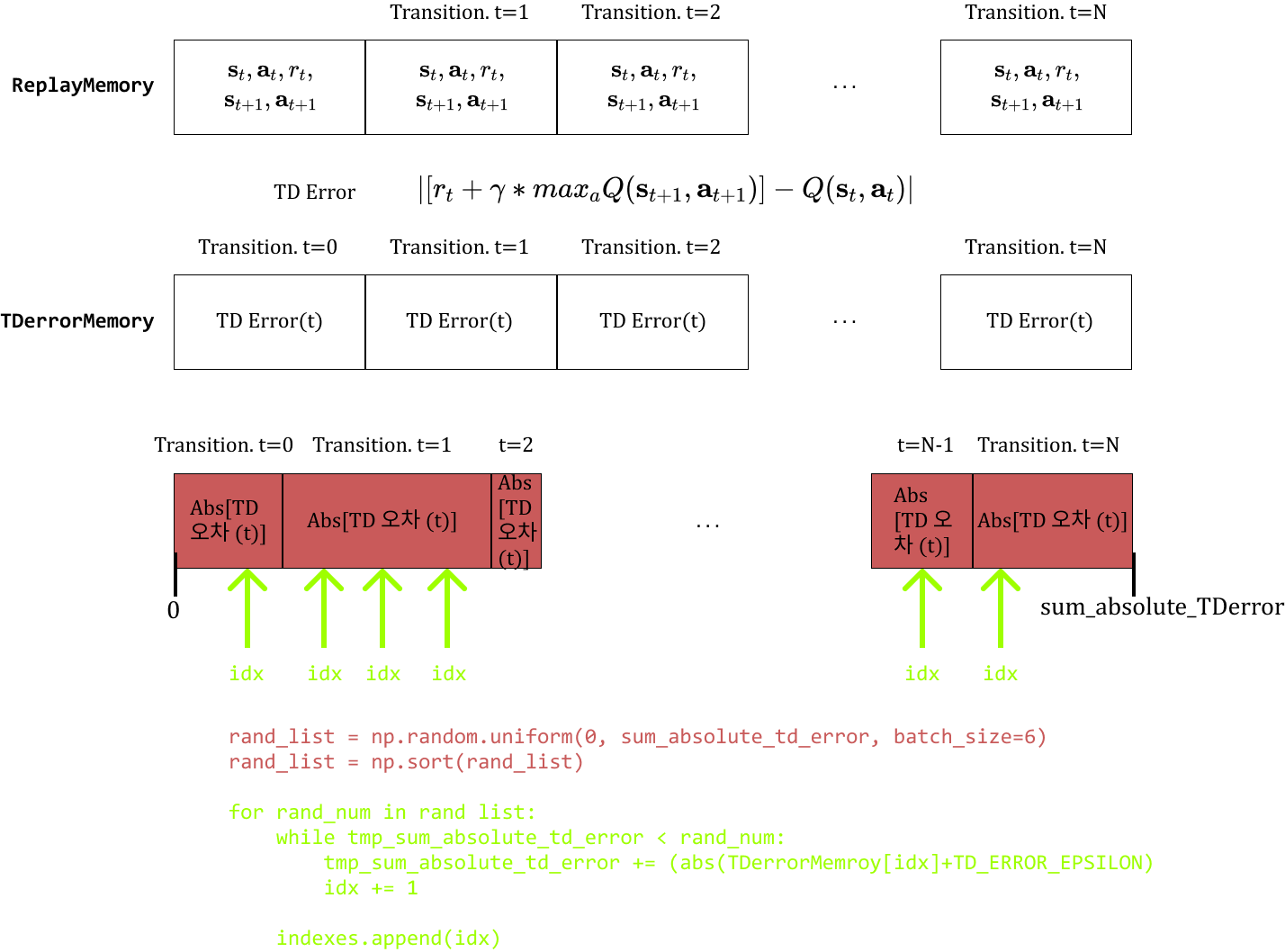
PER 구현
1. TDerrorMemroy 클래스 정의
ReplayMemory의 각 Transition에 대응하는 TD Error를 저장해 둘 클래스 정의
# TD Error를 저장할 메모리 클래스
TD_ERROR_EPSILON = 0.0001 # Error에 더해줄 바이어스
class TDerrorMemory:
def __init__(self, CAPACITY):
self.capacity = CAPACITY # 메모리의 최대 저장 건수
self.memory = [] # 실제 TD Error를 저장할 메모리
self.index = 0 # 저장 위치를 가리킬 index 변수
def push(self, td_error):
'''1. TD Error를 메모리에 저장'''
if len(self.memory) < self.capacity:
self.memory.append(None) # 메모리가 가득차지 않은 경우
self.memory[self.index] = td_error
self.index = (self.index + 1) % self.capacity # 다음 저장할 위치 옮기기
def __len__(self):
'''2. len 함수로 현재 저장된 개수 반환'''
return len(self.memory)1.1 get_prioritized_indexes() 구현
메모리에 저장된 TD Error를 확률 삼아 확률적으로 index를 선택하는 함수.
- TD Error 값이 클수록 index를 가리킬 확률이 높으며 mini batch로 뽑힐 확률이 높다.
- 이 때 TD Error가 매우 작은 경우에는 아예 안 뽑힐 수 있기 때문에 transition이 replay에 전혀 나오지 못할 수 있다. 따라서 충분히 작은
TD_ERROR_EPSILON을 더해줘replay()의make_minibatch()에서 나올 수 있도록 해준다.
def get_prioritized_indexes(self, batch_size):
'''3. TD Error에 따른 확률로 index 추출'''
# TD Error의 총 절댓값 합 계산
sum_absolute_td_error = np.sum(np.absolute(self.memory))
sum_absolute_td_error += TD_ERROR_EPSILON * len(self.memory) # 각 transition마다 충분히 작은 epsiolon을 더함
# [0, sum_absolute_td_error] 구간의 batch_size개 만큼 난수 생성
rand_list = np.random.uniform(0, sum_absolute_td_error, batch_size)
rand_list = np.sort(rand_list) # batch_size개의 생성한 난수를 오름차순으로 정렬
# 위에서 만든 난수로 index 결정
indexes = []
idx = 0
tmp_sum_absolute_td_error = 0
for rand_num in rand_list: # 제일 작은 난수부터 꺼내기
# 각 memory의 td-error 값을 더해가면서, 몇번째 index
while tmp_sum_absolute_td_error < rand_num:
tmp_sum_absolute_td_error += (
abs(self.memory[idx])+TD_ERROR_EPSILON )
idx += 1
# TD_ERROR_EPSILON을 더한 영향으로 index가 실제 개수를 초과했을 경우를 보정
if idx >=len(self.memory):
idx = len(self.memory) -1
indexes.append(idx)
return indexes1.2 update_td_error() 구현
메모리에 저장된 TD Error를 최신 상태로 업데이트하는 함수.
weight를 update하면서 각 transition의 TD Error가 기존 저장된 값과 달라짐. 따라서 적당한 간격으로 TD Error 역시 수정.(ex 1 Episode 마다)
def update_td_error(self, updated_td_errors):
'''4. TD Error 업데이트'''
self.memory = update_td_errors2. replay() 수정, update_td_error_memory() 추가
2.1 Brain 객체 생성 시 위의 TDerrorMemory 객체 생성
Brain 객체 생성자 코드
기존 코드
class Brain:
def __init__(self, num_actions, model_path, device):
self.device = device
self.main_q_network = DuelingNet(1, num_actions).to(self.device)
self.target_q_network = DuelingNet(1, num_actions).to(self.device)
self.num_actions = num_actions # 상하좌우 행동 수
# transition을 기억하기 위한 Memory 객체 10000개 설정
self.memory = ReplayMemory(CAPACITY)
self.model_path = model_path
# 최적화 기법
self.optimizer = optim.Adam(self.main_q_network.parameters(), lr=0.0001)추가된 코드
##### TD Error를 기억하기 위한 메모리 객체 생성
self.td_error_memory = TDerrorMemory(CAPACITY)2.2 replay()의 인자에 episode 추가
make_minibatch()를 episode에 따라 다르게 하기 위해 `make_minibatch(episode)로 변경
def replay(self, episode):
'''1. Experience Replay로 NN의 weight 학습'''
# 1. 저장된 transition 수 확인
if len(self.memory) < BATCH_SIZE:
return
# 2. mini batch 생성
self.batch, self.state_batch, self.action_batch, self.reward_batch, self.non_final_next_states = self.make_minibatch(episode)
# 3. 정답용 Q(s,a) 계산
self.expected_action_state_values = self.get_expected_action_state_values()
# 4. weight 수정
self.update_main_q_network()
make_minibatch(episode)
- episode가 30 미만이면 기존 uniform sampling을 통해
ReplayMemory에서BATCH_SIZE만큼 샘플링하기 - episode가 30 이상이면 TD Error를 이용해 미니 배치를 추출하도록 수정
-indexes=self.td_error_memory.get_prioritized_indexes(BATCH_SIZE)
-transitions=[self.memory.memory[n] for n in indexes]
def make_minibatch(self, episode):
'''3. 미니배치 생성'''
# 3.1 Memory 객체에서 mini batch 추출
if episode < 30:
transitions = self.memory.sample(BATCH_SIZE)
else:
# TD Error를 이용해 mini batch 추출
indexes = self.td_error_memory.get_prioritized_indexes(BATCH_SIZE)
transitions = [self.memory.memory[n] for n in indexes]
# 3.2 transition을 미니 배치에 맞는 형태로 변형
# transitions는 각 step 별로 (state, action, state_next, reward) 형태가 BATCH_SIZE 수만큼 저장
# (state, action, state_next, reward) * BATCH_SIZE ----->
# (state*BATCH_SIZE, action*BATCH_SIZE, state_next*BATCH_SIZE, reward*BATCH_SIZE)
batch = Transition(*zip(*transitions))
# 3.3 state들을 미니 배치에 맞게 변형 후 신경망으로 다룰 수 있는 변수로 변형
# state를 예로 들면, [torch.FloatTensor of size 1*4] 형태의 요소가 BATCH_SIZE 개수만큼 있는 형태
# state_batch, action_batch, reward_batch, non_final_next_states batch 생성
state_batch = torch.cat(batch.state).to(self.device)
action_batch = torch.cat(batch.action).to(self.device)
reward_batch = torch.cat(batch.reward).to(self.device)
non_final_next_states = torch.cat([s for s in batch.next_state
if s is not None]).to(self.device)
return batch, state_batch, action_batch, reward_batch, non_final_next_states2.3 update_td_error_memory() 추가
TDerrorMemory에 저장해 둔 전체 transition의 TD error를 재계산한다.
batch_size만큼 update하는 게 아니라,TDerrorMemory전체를 update 해줘야한다.TDerrorMemory를 update할 때 pytorch의 신경망 결과(Tensor 타입)을 GPU에서 CPU로, NumPy 타입으로 변환, 파이썬 List로 변환이 필요.
def update_td_error_memory(self): # PrioritizedExpereienceReplay
'''6. TD Error Memory에 저장된 TD Error update'''
# 신경망을 추론 모드로 전환
self.main_q_network.eval()
self.target_q_network.eval()
# 전체 transition으로 배치 생성
transitions = self.memory.memory
batch = Transition(*zip(*transitions))
state_batch = torch.cat(batch.state).to(self.device)
action_batch = torch.cat(batch.action).to(self.device)
reward_batch = torch.cat(batch.reward).to(self.device)
non_final_next_states = torch.cat([s for s in batch.next_state
if s is not None]).to(self.device)
# 6.2 main_q_netowrk로 Q(s,a) 계산
action_state_values = self.main_q_network(
state_batch).gather(1, action_batch).to(self.device) # [BATCH_SIZE*1]
# 6.3 max{ Q(next_state, a) } 값 계산, 다음 상태 존재하는지 확인 필요
# 6.3.1 next_state 존재 확인하는 index 마스크 만들기
# [BATCH_SIZE * 1]
non_final_mask = torch.tensor(list(map(lambda s: s is not None,
batch.next_state)), dtype=torch.bool).to(self.device)
# 6.3.2 TD memory 전체 Q(s,a) 계산에 쓰일 next_state 초기화하기
next_max_state_values = torch.zeros(len(self.memory)).to(self.device) # [BATCH_SIZE]
action_max = torch.zeros(len(self.memory)).type(torch.LongTensor).to(self.device) # [BATCH_SIZE]
# 6.3.3 next_state에서 Q 값이 최대가 되는 행동 action_max를 Main Q-Network으로 계산
action_max[non_final_mask] = self.main_q_network(
non_final_next_states.to(self.device)).detach().max(1)[1]
# next_state가 있는 것만을 걸러내고, size=len(memory)를 len(memory)*1로 변환
action_max_non_final_next_states = action_max[non_final_mask].view(-1,1).to(self.device)
# 6.3.4 state_next가 존재하는 action의 Q 값을 target Q-Network로 계산
# max { Q(next_state, a) } 값 구하기
# model 출력 값에서 col 방향 최댓값 (max(axis=1))이 되는 [value, index]를 구함
next_max_state_values[non_final_mask] = self.target_q_network(
non_final_next_states).gather(1, action_max_non_final_next_states).detach().squeeze()
# TD Error 계산
td_errors = (reward_batch + GAMMA * next_max_state_values) - action_state_values.squeeze()
# state_action_values는 size는 [minibatch*1]이므로 squeeze() 메서드로 [minibatch]
# TD Error memory 업데이트, Tensor를 detach() 메서드로 꺼내와 numpy 변수 -> list로 변환
self.td_error_memory.memory = td_errors.detach().to('cpu').numpy().tolist()3. 기존 Agent 클래스에 추가
기존 Agent
class Agent:
def __init__(self, num_actions, model_path, device):
'''task의 state 및 action 수 설정'''
self.brain = Brain(num_actions, model_path, device) # Brain 객체 생성
def update_q_function(self, episode):
''' Q 함수 update'''
# 1. 저장된 transition 수 확인
# 2. 미니배치 생성
# 3. 정답신호로 사용할 Q 계산
# 4. weight 수정
self.brain.replay(episode)
def get_action(self, state, episode):
'''action 결정'''
action = self.brain.decide_action(state, episode)
return action
def memorize(self, state, action, state_next, reward):
''' memory 객체에 state, action, state_next, reward 내용 저장'''
self.brain.memory.push(state, action, state_next, reward)
def save_model(self, episode):
return self.brain.save(episode)
def update_target_q_function(self):
self.brain.update_target_q_network()
3.1 update_q_function 수정
def update_q_function(self, episode):
'''Q 함수 수정'''
self.brain.replay(episode)3.2 memorize_td_error() 추가
def memorize_td_error(self, td_error): # PrioritizedExperienceReplay에서 추가
'''TD Error 메모리에 TD Error 저장'''
self.brain.td_error_memory.push(td_error)3.3 update_td_error_memory() 추가
def update_td_error_memory(self): # PriroritizedExpereienceReplay에서 추가
'''TD Error 메모리의 TD Error update'''
self.brain.update_td_error_memory()
4. Environment 실행 시
agent.memorize_td_error(0)- TD Error를 0으로TDErrorMemory에 저장agent.update_q_function(episode)- Episode에 따라 어떤 Memory(ReplayMemory,TDerrorMemory)에서 batch_size만큼 sampling할지 결정agent.update_td_error_memory()- Episode가 종료될 때마다, Memory의 있는 모든 Transition에 대한 TD Error 값을 update하기
'''
...
'''
# memory에 Experience(state, action, state_next, reward) 저장
agent.memorize(state, action, state_next, reward)
agent.memorize_td_error(0) # 여기서는 정확한 값 대신 0을 저장
# PrioritizedExpereienceReplay로 Q함수 수정
agent.update_q_function(episode)
'''
...
'''
# episode 종료 시
if done:
# TD Error memory의 TD Error update
agent.update_td_error_memory()
'''
...
'''
Don't hesitate!