Big Data Basics
What is a distributed computing?
- A local process will use the computation resources of a single machine
- A distributed process has access to the computational resources across a number of machines connected through network
Why should you use distributed computing?
- After a certain point, it is easier to scale out to many lower CPU machines, than to try to scale up to a single machine with a high CPU
- Fault Tolerance : if one machine fails, the whole network still goes on
What is Hadoop?
- a way to distribute large files across multiple machines
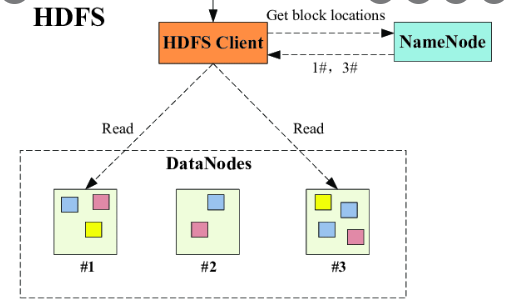
- it uses HDFS
- HDFS duplicates blocks of data for fault tolerance
- MapReduce manipulates and used the data
Hadoop Basic Structure
HDFS
- use blocks of data, with a default size of 128MB
- Each block is replicated 3 times
MapReduce
- MapReduce is a way to split a computation task to a distributed set of files
- Job Tracker : Sends code to run on the task trackers
- Task Tracker : allocates CPU and memory for the tasks and monitor the tasks on the worker nodes
Spark Basics
What is Spark?
- an open source project on Apache
- a flexible alternative to MapReduce
Why use Spark?
- can use data stored in variety of formats
- Cassandra
- AWS S3
- HDFS
- and more - can perform operations up to 100x faster than MapReduce
- Spark keeps most of the data in memory after each transformation / uses disk when the memory is filled
What is RDD (Resilient Distributed Dataset)?
-
4 Main Features
- Distributed Collection of Data
- Fault Tolerant
- Parallel operation-partitioned
- Ability to use many data sources
-
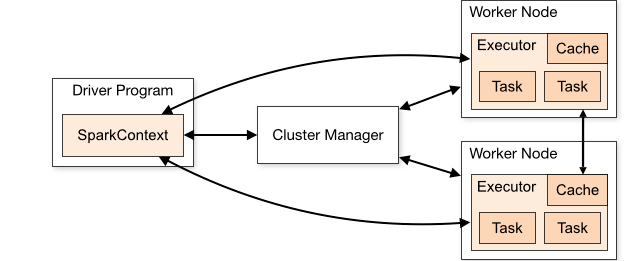
4 Stages of Spark Operation
- Users Manipulate RDD Objects
- Spark schedules those tasks with DAG Scheuduler
- Task Scheduler schedules the tasks onto slave instances
- Worker carries out the actions
-
RDDs are immutable, lazily evaluated, and cacheable
-
There are two types of RDD operations
- Transformations
- Actions
-
Basic Actions
- First
- Collect
- Count
- Take -
Basic Transformations
-RDD.filter(): applies a function to each element and returns elements that evaluate to TrueRDD.map(): transforms each element and preserves # of elements, very similar idea topandas.apply()RDD.flatmap(): transforms each element into 0-N element and chages # of elements- Transforming a corpus of texts into a list of words
-
Often RDDs will be holding their values in tuples (key,value)
-
Reduce()andReduceByKey()
-Reduce(): an action that will aggregte RDD elements using a function that returns a single elementReduceByKey(): an action that will aggregate RDD elements using a function that return a pair RDD
