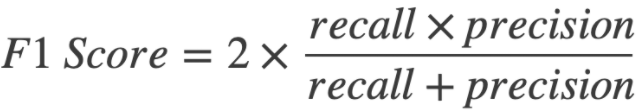
1. Supervised Learning Overview
- trained using labeled examples, such as an input where the desired output is known
- For example, a segment of text could have a category label, such as
- Spam vs Legitimate Email
- Positive vs Negative review
- Network receives a set of inputs along with the corresponding correct outputs, and the algorithms learns by comparing its outputs
- likely to predict future events
- Data is often split into 3 sets
- Training Data : train the model parameters
- Validatation Data : determined what model hyperparameters to adjust
- Test Data : get some true final performance metric- You cannot tweak the parameters based on the Test data
2. Evaluating Performance - Classification Error Metrics
- Once we have the model's predictions from the X_test data, we compare it to the true y data.
- We could organize our predicted values compared to the real values in a confusion matrix
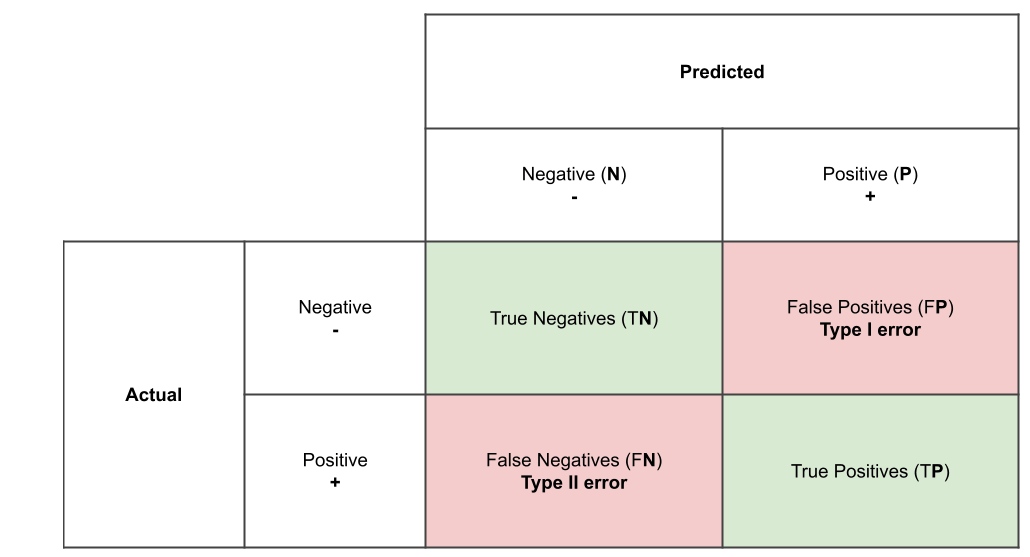
Accuracy
- Accuracy in classification problems is the number of correct predictions made by the model divided by the total number of predictions
- useful when target classes are well balanced (e.g. equal ratio of dog and cat images)
- not a good choice with unbalanced classes (e.g. 99% of images are dogs)
Recall
- ability of a model to find all the relevant cases within a dataset
- (true positives)/ (true positives + false negatives)
Precision
- ability of a classification model to identify only the relevant data points
- (true positives) / (true positives + false positives)
F1-Score
- Optimal blend of precision and recall
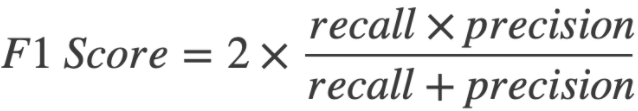
- it punishes extreme values
- precision 1.0 recall 0.0 => average of 0.5 but F1 of 0
What is a good enough accuracy?
- Do we have a balanced population?
- What is the goal of the model?
- is it to fix false positives?
- is it to fix false negatives? (disease diagnosis) - It all depends on the context of the problem
3. Evaluating Performance - Regression Error Metrics
Overall concept
- recall and precision might not be useful
- regression models are composed of continuous variables
- Common metrics used
- Mean Absolute Error
- Mean Squared Error
- Root Mean Square Error
Mean Absolute Error (MAE)
- This is the mean of the absolute value of errors
- Easy to understand
- Shortcoming: MAE won't punish large errors
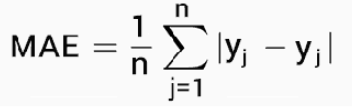
Mean Squared Error (MSE)
- This is the mean of the squared errors
- Larger errors are noted more than with MAE, Making MSE more popular
- Shortcoming: metrics can be distorted
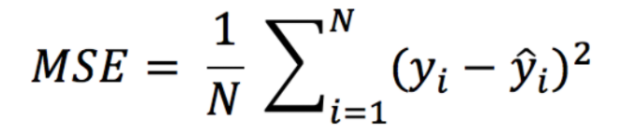
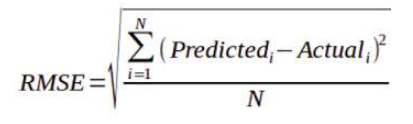
Root Mean Square Error (RMSE)
- This is the root of the mean of the squared errors
- Most Popular (has same units as y)
The Contents of this post belongs to Jose Portilla's Python for Data Science and Machine Learning Bootcamp
