
HTTP 프로토콜의 구조에 대해 알아볼 것이다.
HTTP는 클라이언트와 서버 간에 통신을 한다.
텍스트나 이미지 등과 같은 리소스가 필요하다고 요청을 할 수가 있다.
이때 요청을 하는 쪽이 클라이언트이고 요청을 받는 쪽이 서버쪽이다.
상황에 따라 한 컴퓨터가 클라이언트가 될 수도 있고 서버가 될 수도 있다.
Request와 Response
클라이언트로부터 요청(request)이 송신되고, 그 결과 서버로부터 응답이(response) 온다.
요청이 오지 않으면 서버 측에서 응답을 하는 일은 없다.
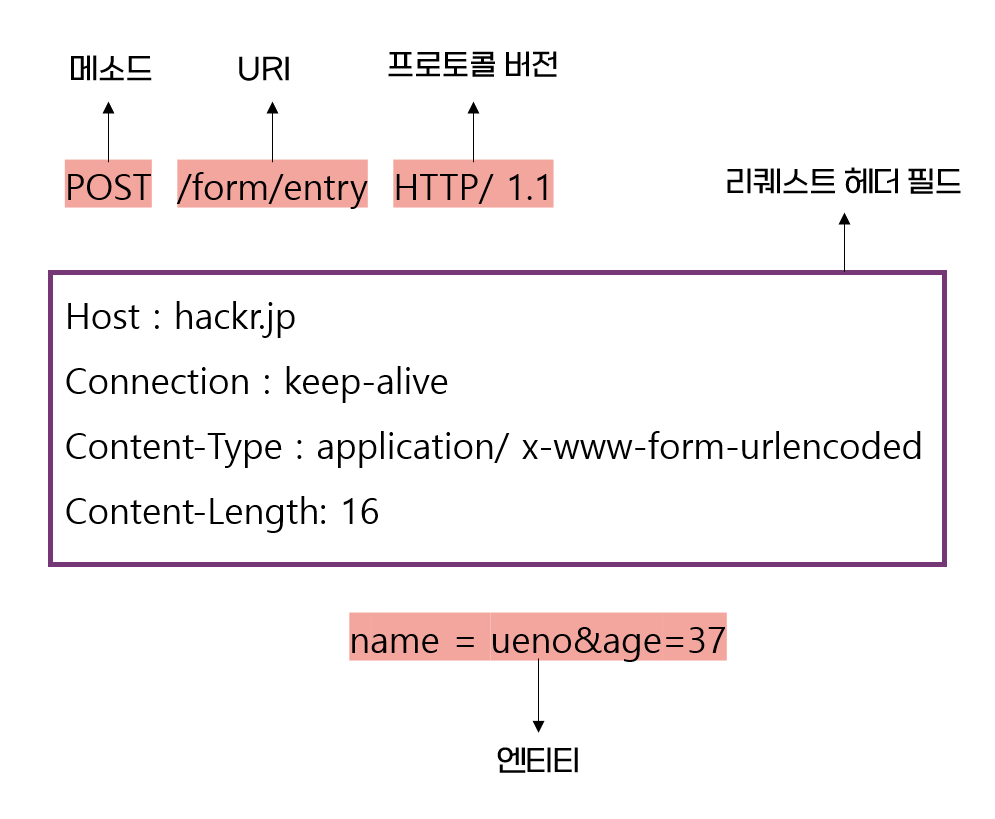
클라이언트 측으로부터 HTTP 서버에 송신되었던 요청 내용
GET /index.html HTTP /1.1
Host: www.hackr.jp
GET : 서버에 요구하는 종류를 나타내고 있고, 메소드라고 불린다.
/index.html : 요구 대상인 리소스를 나타내고 있는데 / 리퀘스트 URI라고 한다.
HTTP /1.1 : 클라이언트 기능을 식별하기 위한 HTTP 버전 번호이다.
즉, 요청 내용은 HTTP 서버상에 있는 "index.html"라는 리소스가 필요하다는 Request이다.
리퀘스트 메시지 구성
리스폰스 메시지 구성

기본적으로 리스폰스 메시지는 프로토콜 버전, 상태 코드(리퀘스트가 성공했는지 실패했는지 등을 나타내는 숫자 코드)와 그 상태 코드를 설명한 프레이즈, 옵션의 리스폰스 헤더 필드와 바디로 구성되어 있다.
HTTP는 상태를 유지하지 않는 프로토콜
HTTP는 상태를 계속 유지하지 않는 스테이트리스(stateless) 프로토콜이다.
Stateless : server side에 client와 server의 동작, 상태정보를 저장하지 않는 형태, server의 응답이 client와의 세션 상태와 독립적임
HTTP 프로토콜 독자적으로, 리퀘스트와 리스폰스를 교환하는 동안에 상태(status)를 관리하지 않는다.
결국, HTTP 프로토콜 레벨에서는 이전에 보냈던 리퀘스트나 이미 되돌려준 리스폰스에 대해서는 전혀 기억하지 않는다.
이는 많은 데이터를 매우 빠르고 확실하게 처리하는 범위성을 확보하기 위해서 이와 같이 간단하게 설계되어 있는 것이다.
하지만 웹이 진화함에 따라 스테이트리스 특성만으로는 처리하기 어려운 일이 증가하게 됐다.
예를 들어 쇼핑 사이트에 로그인 했을 때 다른 페이지로 이동하더라도 로그인 상태를 유지할 필요가 있었다.
HTTP/1.1은 상태를 유지하지 않는 프로토콜이다.
그래서 상태를 계속 유지하고 싶은 요구에 부응하기 위해서 쿠키(내가 만든 쿠키~)라는 기술이 도입되었다.
Request URI로 리소스를 식별
URI : Uniform Resource Identifier
인터넷 자원을 나타내는 고유 식별자이다.
인터넷에 있는 자료의 id이고 유일해야 한다.
클라이언트는 리퀘스트를 송신할 때에 리퀘스트 안에 URI를 리퀘스트 URI라고 불리는 형식으로 포함해야 할 필요가 있다.
리퀘스트 URI를 지정하는 방법에는 여러 종류가 있다.
(http://hackr.jp/index.htm을 리퀘스트 하는 경우)
모든 URI를 리퀘스트 URI에 포함한다.
GET http://hackr.jp/index.html HTTP/1.1
Host 헤더 필드에 네트워크 로케이션을 포함한다.
GET /index.htm HTTP/1.1
Host: hackr.jp
이것 외에도 특정 리소스가 아닌 서버 자신에게 리퀘스트를 송신하는 경우에는 리퀘스트 URI에 [*]을 지정할 수 있다. (흠.. 무슨말이지)
아래는 HTTP 서버가 지원하고 있는 메소드를 묻는 예이다.
OPTIONS* HTTP/1.1
서버에 임무를 부여하는 HTTP 메소드
GET: 리소스 획득
GET 메소드는 리퀘스트 URI로 식별된 리소스를 가져올 수 있도록 요구한다.
request
GET /index.html HTTP /1.1
Host: www.hackr.jp
if-Modified-Since: Thu. 12 Jul 2012 07:30:0 GMT
response
index.html 리소스가 2012년 7월 12일 7시 30분 이후에 갱신된 경우에만 리소스를 되돌려 준다. 그 이전이라면 상태 코드 304 Not Modified reponse를 되돌려준다.
POST: 엔티티 전송
Post 메소드는 엔티티를 전송하기 위해서 사용된다.
GET으로도 엔티티를 전송할 수 있지만, 자주 사용하지 않고 일반적으로 POST를 사용한다.
PUT : 파일 전송
PUT 메소드는 파일을 전송하기 위해서 사용된다.
FTP에 의한 파일 업로드와 같이, 리퀘스트 중에 포함된 엔티티를 리퀘스트 URI로 지정한 곳에 보존하도록 요구한다.
FTP(File Transfer Protocol) : 파일 전송 프로토콜
단지 HTTP/1.1 PUT 자체에는 인증 기능이 없어 누구든지 파일을 업로드 가능하다는 보안 상의 문제도 있어서 일반적인 웹 사이트에서는 사용되지 않고 있다.
웹 애플리케이션 등에 의한 인증 기능과 짝을 이루는 경우나 REST와 같이 웹끼리 연계하는 설계 양식을 사용할 때 이용하는 경우가 있다.
HEAD : 메시지 헤더 취득
HEAD 메소드는 GET과 같은 기능이지만 메시지 바디는 돌려주지 않는다.
URI 유효성과 리소스 갱신 시간을 확인하는 목적 등으로 사용한다.
DELETE : 파일 삭제
DELETE 메소드는 파일을 삭제하기 위해 사용된다.
PUT 메소드와는 반대로 동작하며 리퀘스트 URI로 지정된 리소스의 삭제를 요구한다.
HTTP/1.1 DELETE 자체에는 PUT 메소드와 같이 인증 기능이 없기 때문에 일반적인 웹 사이트에서는 사용되지 않고 있다.
웹 애플리케이션 등에 의한 인증 기능과 짝을 이루는 경우나 REST와 같이 웹끼리 연계하는 설계 양식을 사용할 때 이용하는 경우가 있다.
OPTIONS : 제공하고 있는 메소드의 문의
OPTIONS 메소드는 리퀘스트 URI로 지정한 리소스가 제공하고 있는 메소드를 조사하기 위해 사용한다.
request
OPTIONS * HTTP /1.1
Host: www.hackr/jp
response
HTTP /1.1 200 OK
Allow: GET, POST, HEAD, OPTIONS
(서버가 제공하고 있는 메소드를 되돌려준다.)
TRACE : 경로 조사
TRACE 메소드는 Web 서버에 접속해서 자신에게 통신을 되돌려 받는 루프백(loop-back)을 발생시킨다.
TRACE를 사용함으로써 리퀘스트를 보낸 곳에 어떤 리퀘스트가 가공되어 있는지 등을 조사할 수 있다.
다만, 이 메소드는 거의 사용되지 않는데다 크로스 사이트 트레이싱(XST)과 같은 공격을 일으키는 보안 상의 문제도 있기 때문에 보통은 사용되고 있지 않다.
CONNECT : 프록시에 터널링 요구
CONNECT 메소드는 프록시에 터널 접속 확립을 요함으로써, TCP 통신을 터널링 시키기 위해서 사용된다.
주로 SSL이랑 TLS등의 프로토콜로 암호화된 것을 터널링 시키기 위해서 사용되고 있다.
양식은
CONNECT 프록시 서버 : 포트 HTTP 버전
이렇게 이루어져 있다.
메소드를 사용해서 지시를 내리다.
리퀘스트 URI로 지정한 리소스에 리퀘스트를 보내는 경우에는 메소드라고 불리는 명령이 있다. (뭔 솔 이 지)
메소드는 리소스엥 어떠한 행동을 하기 원하는지를 지시하기 위해 존재한다.
메소드에는 GET, POST, HEAD등이 있다.
| 메소드 | 설명 | 제공하고 있는 HTTP 버전 |
|---|---|---|
| GET | 리소스 취득 | 1.0 1.1 |
| POST | 엔티티 바디 전송 | 1.0 1.1 |
| PUT | 파일 전송 | 1.0 1.1 |
| HEAD | 메시지 헤더 취득 | 1.0 1.1 |
| DELETE | 파일 삭제 | 1.0 1.1 |
| OPTIONS | 서포트하고 있는 메소드 문의 | 1.1 |
| TRACE | 경로 조사 | 1.1 |
| CONNECT | 프록시에 터널링 요구 | 1.1 |
| LINK | 리소스 간에 링크 관계를 확립 | 1.0 |
| UNLINK | 링크 관계 삭제 | 1.0 |
여기서 LINK와 UNLINK는 HTTP /1.1에서 폐기되어 제공하고 있지 않다.
지속 연결로 접속량을 절약
초기에는 간단한 텍스트만 보내서 HTTP 통신을 한 번 할 때마다 TCP에 의해 연결과 종료를 했다.
그렇게 해도 괜찮았다. 용량이 작았기 때문에!
그러나 시간이 갈 수록 이미지를 포함한 문서 등이 늘어났다.
예를 들어 사진을 여러장이 있는 것을 리퀘스트 하면 이 이미지를 획득하기 위해서 여러 리퀘스트를 송신한다.
그렇게 되면 리퀘스트를 보낼 때마다 매번 TCP 연결과 종료를 하게 되는 쓸모없는 일이 발생되어 통신량이 늘어나게 된다.
-> 서버가 힘들어 하게 된다.
지속 연결
HTTP/1.1와 일부 HTTP/1.0에서는 TCP 연결 문제를 해결하기 위해서 지속 연결(Persistent Connections)이라는 방법을 고안하였다.
특징
어느 한 쪽이 명시적으로 연결을 종료하지 않는 이상 TCP 연결을 계속 유지하는 것
그럼 뭐가 좋은데? (이점)
① TCP 커넥션의 연결과 종료를 반복되는 오버헤드를 줄여주기 때문에 서버에 대한 부하 경감
② 오버헤드를 줄인 만큼 HTTP 리퀘스트와 리스폰스가 빠르게 완료되기 때문에 웹 페이지를 빨리 표시할 수 있음
파이프라인화
지속 연결은 여러 리퀘스트를 보낼 수 있도록 파이프라인화(HTTP pipelining)를 가능하게 한다.
이전에는 리스폰스를 수신할 때까지 기다렸지만, 파이프라인화가 가능해지면서 리스폰스를 기다리지 않고 바로 다음 리퀘스트를 보낼 수 있게 되었다.
예를 들어 HTML 한 페이지에 10개의 이미지를 포함한 웹 페이지를 리퀘스트한 경우
개별 연결보다 지속 연결이 리퀘스트 완료가 빠르고,
지속 연결보다 파이프라인화가 더 빠르다.
쿠키를 사용한 상태 관리
아까 위에서 얘기가 나온 게 있다.
뭘까요~?
HTTP는 스테이트리스 프로토콜이라는 것 (stateless protocol)
그게 뭔데?
과거에 교환했었던 request와 response의 상태를 관리하지 않는 것이다.
스테이트리스 프로토콜에 장단점이 있다.
장점
상태를 유지하지 않음으로 서버의 CPU나 메모리 같은 리소스의 소비를 억제할 수 있다.
단순한 프로토콜이기에 HTTP가 다양한 곳에서 이용되는 측면이 있다.
단점
로그인(인증)이 필요한 웹페이지의 경우
새로운 페이지로 이동할 때마다 재차 로그인 정보를 보내든지,
리퀘스트마다 매개 변수나 추가 정보를 붙여서 로그인 상태를 관리해야하는 상황이 발생
이것을 해결하기 위하여 쿠키 등장 !
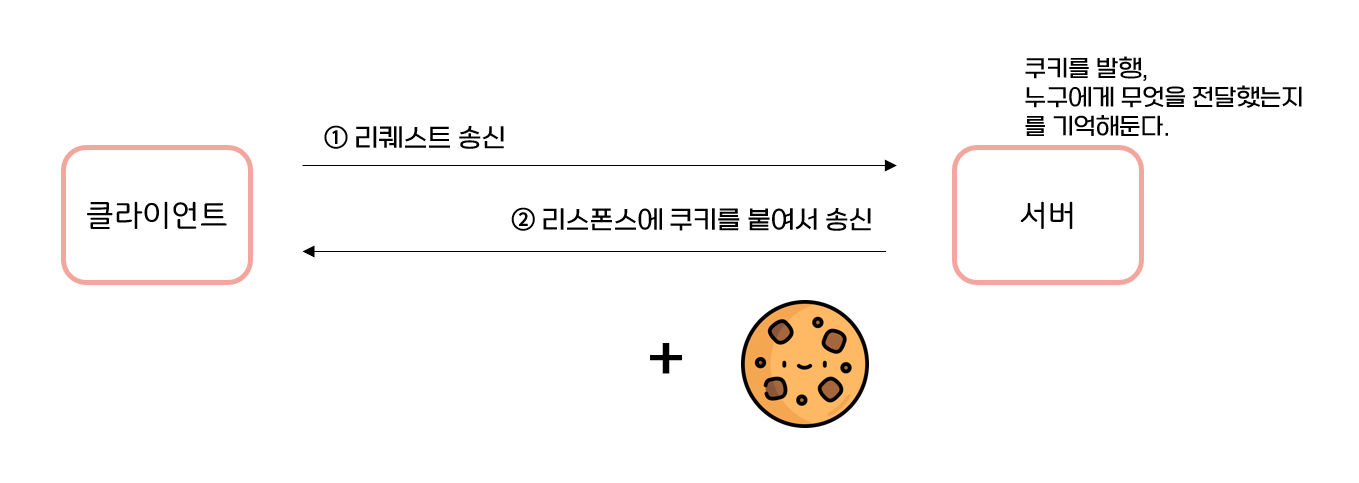
쿠키는 request와 response에 쿠키 정보를 추가해서 클라이언트의 상태를 파악하기 위한 시스템이다.
쿠키를 가지지 않는 상태에서의 리퀘스트
2회째 이후의 리퀘스트 -> 쿠키를 가지고 있는 상테
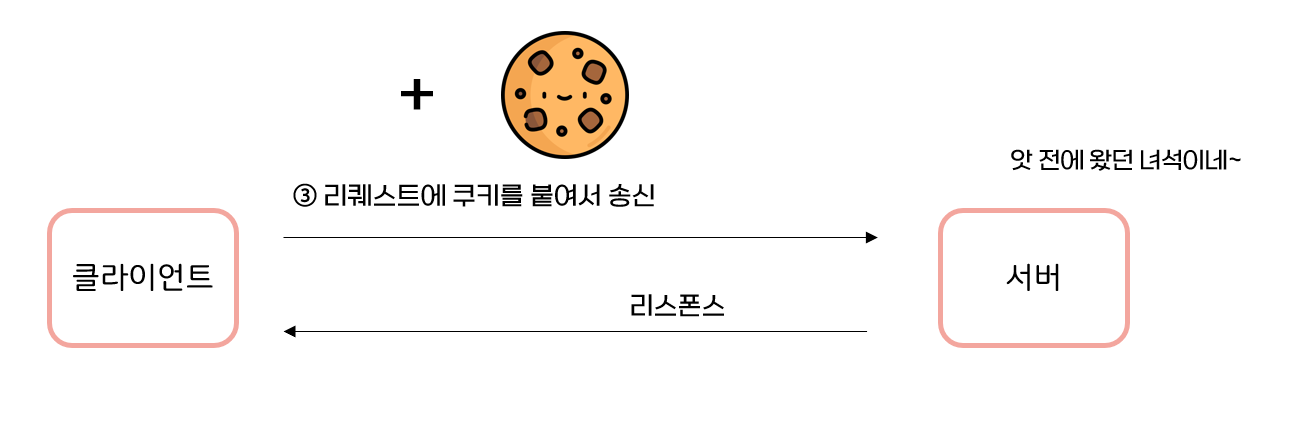
쿠키를 교환할 때 HTTP 리퀘스트와 리스폰스의 내용은 다음과 같다.
① 리퀘스트 (쿠키를 가지고 있지 않은 상태)
GET /reader/ HTTP /1.1
Host: www.youngjin.com
*헤더 필드에 쿠키는 없다.
② 리스폰스 (서버가 쿠키를 발행)
HTTP /1.1 200 OK
Date: Thu, 12 Jul 2012 07:12:20 GMT
Server: Apache
<Set-Cookie: sid=1342077140226724; path=/;expires=Wed, => 10-Oct-12 07:12:200 GMT
Content-Type: text/plain; charset=UTF-8
③ 리퀘스트(보관하고 있던 쿠키를 자동 송신)
GET /image/ HTTP /1.1
Host: www.youngjin.com
Cookie: sid=1342077140226724
