개요
- sklean에서 제공하는 Iris 데이터 셋을 이용한 실습
실습
사용 데이터 셋
python의 라이브러리중 하나인 sklean의 기본 데이터셋 중 하나인 붓꽃(Iris) 사용
실습 순서
1. 훈련, 테스트 데이터 분리 8:2 , 7:3
2. 모델의 학습 LogisticRegression(), fit(), 예측 predict(X_test) 평가
2-1. DecissionTree()
3. 모델학습과정을 사용자정의화
1. 훈련, 테스트 데이터 분리
iris = load_iris()
X = iris.data
y = iris.target
feature_names = iris.feature_names
target_names = iris.target_names
# print(feature_names)
# print(target_names)
# 1. 훈련, 테스트 데이터 분리 8:2 , 7:3
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size= 0.2)X = iris.data ,y = iris.target의 데이터 형태
LogisticRegression()
- 영국의 통계학자인 D.R.Cox가 1957년에 제안한 확률 모델
- 독립변수의 선형 결합을 이용하여 사건의 발생 가능성을 예측하는 데 사용되는 통계 기법
- 결과값이 0과 1 사이의 확률로 나타남
# 3. 모델의 학습 LogisticRegression(), fit(), 예측 predict(X_test) 평가
lr = LogisticRegression(max_iter = 150) # max_iter => 반복횟수
lr.fit(X_train, y_train) # iris데이터의 훈련데이터 (X_train컬럼명, y_train품종)
print('LogisticRegression() 모델 학습 fit 종료')
print()
# pred 예측
y_pred = lr.predict(X_test) # 무언의 약속으로 y_pred
print('lr,predict(X_test) 학습후 예측 ')
print(y_pred)
# 모델 평가
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy}")
DecisionTree()
- 데이터 기반으로 의사 결정을 수행하는 트리 구조의 머신러닝 알고리즘
- 분류및 회귀 문제 모두 해결 가능하며, 쉬운 규칙 기반 모델
dt = DecisionTreeClassifier()
dt.fit(X_train, y_train) # iris데이터의 훈련데이터 (X_train컬럼명, y_train품종)
print('DecisionTreeClassifier() 모델 학습 fit 종료')
print()
# pred 예측
y_pred = dt.predict(X_test) # 무언의 약속으로 y_pred
print('lr,predict(X_test) 학습후 예측 ')
print(y_pred)
# 모델 평가
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy}")
3. 모델학습과정을 사용자정의화
def lr_def(X_train, X_test, y_train, y_test):
lr = LogisticRegression() # max_iter => 반복횟수
lr.fit(X_train, y_train) # iris데이터의 훈련데이터 (X_train컬럼명, y_train품종)
print('LogisticRegression() 모델 학습 fit 종료')
print()
# pred 예측
y_pred = lr.predict(X_test) # 무언의 약속으로 y_pred
print('lr,predict(X_test) 학습후 예측 ')
print(y_pred)
# 모델 평가
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy}")
return y_pred, accuracy
def dt_def(X_train, X_test, y_train, y_test):
# DecisionTree를 이용한 학습 모델 만들기
dt = DecisionTreeClassifier()
dt.fit(X_train, y_train) # iris데이터의 훈련데이터 (X_train컬럼명, y_train품종)
print('DecisionTreeClassifier() 모델 학습 fit 종료')
print()
# pred 예측
y_pred = dt.predict(X_test) # 무언의 약속으로 y_pred
print('lr,predict(X_test) 학습후 예측 ')
print(y_pred)
# 모델 평가
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy}")
return y_pred, accuracy시각화
def compare_viewer(y_test, y_pred_lr, accuracy_lr, y_pred_dt, accuracy_dt):
fig, axes = plt.subplots(1, 2, figsize=(12, 6)) # 1행 2열 서브플롯
models = ["Logistic Regression", "Decision Tree"]
predictions = [y_pred_lr, y_pred_dt]
accuracies = [accuracy_lr, accuracy_dt]
colors = ['blue', 'green', 'red']
for idx, ax in enumerate(axes):
# 2. y = x 대각선 (완벽한 예측 기준선)
ax.plot([0, 2], [0, 2], linestyle='-', color='black', label="y = x (Perfect Prediction)")
# 3. 산점도 (예측 vs 실제) - 각 클래스별로 색상 다르게 적용
for i, class_name in enumerate(target_names):
mask = y_test == i
jitter_x = y_test[mask] + np.random.uniform(-0.05, 0.05, size=sum(mask))
jitter_y = predictions[idx][mask] + np.random.uniform(-0.05, 0.05, size=sum(mask))
ax.scatter(jitter_x, jitter_y, color=colors[i], alpha=0.7, label=class_name, s=70)
# 4. 그래프 설정
ax.set_xlabel("Actual Label (y_test)")
ax.set_ylabel("Predicted Label (y_pred)")
ax.set_title(f"{models[idx]} (Accuracy: {accuracies[idx]:.2f})")
ax.set_xticks([0, 1, 2])
ax.set_yticks([0, 1, 2])
ax.set_xticklabels(target_names)
ax.set_yticklabels(target_names)
plt.tight_layout()
plt.show()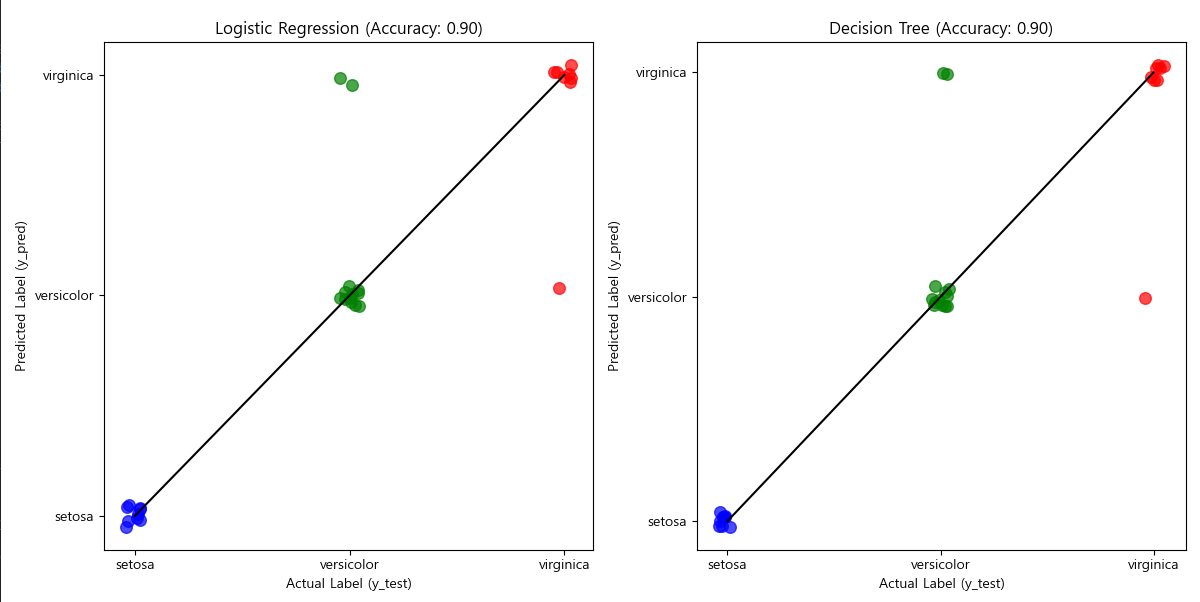

안녕하세요. 도야입니다