개요
- 타이타닉 데이터
- 결측값 없애기
1. 타이타닉 데이터 정보 확인
pfile_train = './titanic/train.csv'
pfile_test = './titanic/test.csv'
train = pd.read_csv (pfile_train)
test = pd.read_csv(pfile_test)
print(train.info())
print()
print(test.info())
print()
print(train.columns)
print()
print(test.columns)
print()
print(train.dtypes)
print()
print(test.dtypes)
print()
print(train.shape, ' ',test.shape, ) - info를 통해 정보확인
- columns를 통해 컬럼명 확인
- dtypes를 통해 datatype 확인
- Shape를 통해 행렬의 크기 확인
2. 생존자와 사망자의 분포를 확인하기 위한 그래프 사용자 함수 정의
def bar_chart(feature):
survived = train[train['Survived'] == 1][feature].value_counts()
dead = train[train['Survived'] == 0][feature].value_counts()
df = pd.DataFrame( [survived,dead])
df.index = ['survived', 'dead']
df.plot(kind='bar', figsize=(3,3))
plt.xticks(rotation = 0)
plt.show()성별, Pclass에 따른 생존자 사망자 분포 시각화
bar_chart('Sex')
bar_chart('Pclass')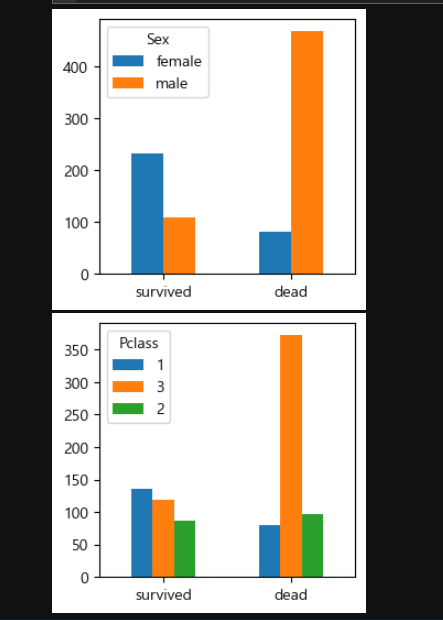
3. 결측치 해결
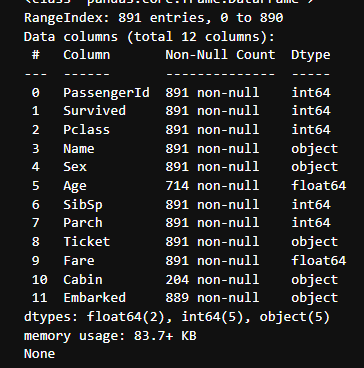
train.info()를 통해 결측치 확인
Age, Cabin, Embarked의 칼럼에서 결측치를 해결해야 함
동일 방법으로 test의 데이터도 확인및 해결
1. Age의 결측치 해결
- NaN값은 나이의 평균값으로 대체
train_test_data = [train, test]
for dt in train_test_data:
age_mean = dt['Age'].mean().round(2)
dt['Age'] = dt['Age'].fillna(age_mean)- Age 연령대 분류
bins = [0, 10, 16, 26, 40, 56, 65, 100] # 연령 구간
labels = [1, 2, 3, 4, 5, 6, 7] # 매핑할 숫자
for dt in train_test_data:
dt['Age'] = pd.cut(dt['Age'], bins=bins, labels=labels).astype(int)2. Cabin의 결측치 해결
Pclass1 = train[ train['Pclass'] == 1 ]['Cabin'].value_counts()
Pclass2 = train[ train['Pclass'] == 2 ]['Cabin'].value_counts()
Pclass3 = train[ train['Pclass'] == 3 ]['Cabin'].value_counts()
df = pd.DataFrame ([Pclass1, Pclass2, Pclass3] )
df.index = ['1st class', '2st class', '3st class']
cabin_mapping = {
'A':1, 'B':1.5, 'C':2, 'D':1.2, 'E':1.5, 'F': 2, 'G':2.5,'T':1.5,
}
for dt in train_test_data:
dt['Cabin'] = dt['Cabin'].map(cabin_mapping)
train['Cabin'].fillna(train.groupby('Pclass')['Cabin'].transform('median'), inplace = True)
test['Cabin'].fillna(test.groupby('Pclass')['Cabin'].transform('median'), inplace = True)3. Embarked의 결측치 해결
train['Embarked'] = train['Embarked'].fillna('S')
안녕하세요. 도야입니다