개요
- LableEncoder
- OneHotEncoder
인코딩(Encoding)
- 컴퓨터는 0과 1로이루어진 2진법을 사용함
- 문자, 숫자등을 그대로 컴퓨터에게 알려주면 컴퓨터는 이해 못함
- 머신러닝/딥러닝을 할 때 문자열, 숫자형 데이터들을 인코딩하는 전처리 단계가 필요
- LableEncoder, OneHotEncoder 방식이 있음
LableEncoder
- 각 카테고리를 특정한 정수값으로 매핑하여 변환하는 방식
- 고유한 범주를 0부터 정수로 변환
- 단일 컬럼 변환에 적용 가능
- 범주형 데이터 순서관계가 있을 때 적합
data = ['dag', '겨울','cat', 'mouse']
labelEncoder = LabelEncoder()
result = labelEncoder.fit_transform(data)
print('레이블전', data)
print('레이블후', result)
# 레이블인코더 -> 문자화
decoder = labelEncoder.inverse_transform(result)
print(decoder)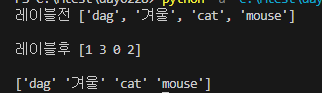
OneHotEncoder
- 각 범주를 독립적인 열로 변환하고 해당하는 범주에만 1을 표시하는 방식
- 하나의 컬럼을 여러 개의 컬럼으로 확장
- 범주 간 순위 관계가 없도록 처리
- 머신러닝 모델에서 많이 사용되는 인코딩 방식
data = ['dag','cat','apple', '여름', '123']
df = np.array(data).reshape(-1, 1) # reshape: 차원의 재정렬 역할
one_hot_encoder = OneHotEncoder()
encoder = one_hot_encoder.fit_transform(df).toarray()
print(encoder)
decoder = one_hot_encoder.inverse_transform(encoder).flatten() # flattem
print(decoder)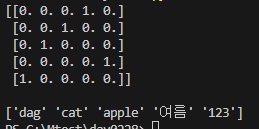
| 비교 항목 | LabelEncoder | OneHotEncoder |
|---|---|---|
| 출력 형태 | 1개의 컬럼(정수값) | 여러 개의 컬럼(One-Hot 벡터) |
| 데이터 타입 | 정수형 (0, 1, 2 ...) | 0과 1로 이루어진 벡터 |
| 범주 간 관계 | 숫자 크기 때문에 관계가 생길 위험 | 각 범주가 독립적으로 표현됨 |
| 적용 범위 | 단일 컬럼 변환 | 다중 컬럼 변환 가능 |
| 사용 예시 | 순서가 있는 데이터(예: 학년, 등급) | 범주 간 관계가 없는 데이터(예: 동물, 도시명) |
언제 어떤 인코더를 사용할까?
| 상황 | 추천 인코더 |
|---|---|
| 순서가 있는 범주형 데이터 | LabelEncoder |
| 순서가 없는 범주형 데이터 | OneHotEncoder |
| 머신러닝 모델에서 범주형 변수를 입력으로 사용할 때 | OneHotEncoder |
pd.get_dummies 와 OneHotEncoder
- pandas에서도 OneHotEncoding을 실행하는 함수를 지원함
- 각 범주를 독립적인 컬럼(열)으로 변환하고, 해당 범주에만 1을 넣음
- 판다스 버전에 따라 True, False로 값을 넣기도 함
data = ['dag','cat','mouse']
df = pd.DataFrame({'Animal' : data})
ohe = OneHotEncoder()
one_hot_encoder = pd.get_dummies(df, columns=['Animal'])
print(one_hot_encoder)
# 리스트 형식으로 전환 replace()로 Animal_제거 idxmax(), replace, tolist
rs2 = one_hot_encoder.idxmax(axis = 1).str.replace('Animal_', '').tolist()
print(rs2)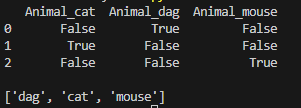
OneHotEncoder() vs pd.get_dummies() 차이점
| 비교 항목 | OneHotEncoder() (scikit-learn) | pd.get_dummies() (pandas) |
|---|---|---|
| 입력 데이터 형식 | 2D 배열 (reshape(-1,1)) | 1D Series 또는 DataFrame |
| 출력 데이터 형식 | 기본적으로 희소 행렬(sparse matrix) | 일반 Pandas DataFrame |
| 훈련 데이터와 테스트 데이터 일관성 유지 | ✅ 가능 (fit() 사용) | ❌ 새로운 데이터 추가 시 기존 인코딩과 다를 수 있음 |
| 새로운 카테고리 처리 | handle_unknown='ignore' 설정 가능 | 새로운 값이 있으면 오류 발생 |
| 머신러닝 모델 사용 | 💡 머신러닝용 (희소 행렬 지원) | 💡 데이터 분석 및 시각화용 (간단하고 직관적) |
언제 어떤 것을 사용해야 할까?
| 사용 목적 | 추천 방식 |
|---|---|
| 머신러닝 모델 훈련 | OneHotEncoder() (훈련 데이터와 일관성 유지) |
| 탐색적 데이터 분석 (EDA) | pd.get_dummies() (빠르고 직관적) |
| 새로운 범주가 발생할 가능성이 있는 경우 | OneHotEncoder(handle_unknown='ignore') |
| 원본 DataFrame을 유지하면서 변환할 경우 | pd.get_dummies(df, columns=['컬럼명']) |

안녕하세요. 도야입니다