개요
- pandas shift
- sklearn 개요
pandas shift()
- 데이터프레임의 행을 위, 아래로 옮기고 싶을때 사용
- 데이터의 변화량을 표현할 때 사용
실습
path ='./data/남북한발전전력량.xlsx'
df = pd.read_excel(path ,engine='openpyxl')
# print(df) #[9 rows x 29 columns]
# print()
# 해결1] north의 5:8까지의 모든데이터 가져오기 loc[5:8]
df = df.loc[5:8]
print(df)
print()
# 해결2] 전력량 (억㎾h) 열컬럼 삭제 drop
# NaN값을 drop하기
df.drop('전력량 (억㎾h)', axis='columns', inplace=True)
print(df)
print()
# 해결3] "발전 전력별" 필드 숫자 index 대체
df.set_index('발전 전력별', inplace=True)
print(df)
print()
# 해결4] 년도를 행으로 합계, 수력, 화력을 열컬럼 대체
df = df.T
print(df)
print()
ax1 = df[['수력','화력']].plot(kind='bar', figsize=(16, 8), width=0.7, stacked = True) #, stacked=True
plt.title('북한 전력 발전량 (1990 ~ 2016)', size=20)
ax1.legend(loc='upper right')
ax1.set_xlabel('year년도')
ax1.set_ylabel('발전량(KWh)')
ax1.set_ylim(0, 300) # y축의 제한
# 해결5] shift(1)를 이용하여 합계 한 칸 아래로 이동
df['합계-1년'] = df['합계'].shift(1)
# 증감률 = ((이번년도합계 / 전년도합계) -1) * 100
df['증감률'] = ((df['합계'] / df['합계-1년'])-1 )* 100
print(df)
ax2 = ax1.twinx()
ax2.plot(df.index,df['증감률'], ls = '--', marker = 'o', markersize = 20, color = 'g' )
ax2.legend(loc='upper left')
ax2.set_xlabel('year')
ax2.set_ylabel('전년도 대비 증감률(%)') #y축 레이블
ax2.set_ylim(-55, 55)
plt.show()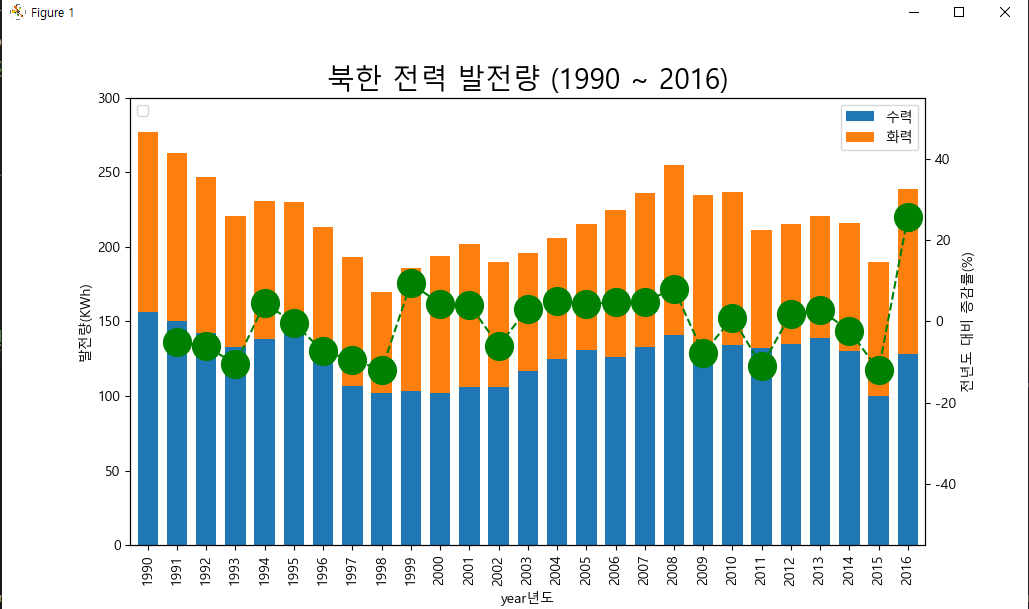
사이킷런(Sklearn)
- 파이썬을 대표하는 머신러닝 분석을 할때 유용하게 사용할 수 있는 라이브러리
- 오픈 소스로 공개 되어 있음
공식 사이트 소개문
- 예측 데이터 분석을 위한 간단하고 효율적인 도구
- 누구나 접근할 수 있으며 다양한 상황에서 재사용 가능
- NumPy, SciPy, 매트플롯립 기반
- 오픈 소스, 상업적으로 사용 가능 - BSD 라이선스
Simplelmputer를 이용한 결측값 바꾸기
결측값
- 알려지지 않고, 수집되지 않거나 잘못 입력된 데이터 세트의 값
data = [
[1, 2, np.nan, 4, 5],
[4, np.nan, 6, 9, 10],
[7, 8, 9, 14, 15]
]
data = np.array(data)
print('결측치 처리 전\n', data)
df = pd.DataFrame(data)
df = df.fillna(df.median())
print(df)train_test_split()
머신 러닝 모델을 만들 때, 훈련과 테스트로 나누어 학습의 성능 평가를 수행함
- Train Data
- 모델이 학습하는 데 사용하는 데이터
- Test Data
- 모델의 성능을 평가하는 데 사용
train_test_split() 은 랜덤으로 Train Data 와 Test Data로 분배
보통 8:2, 7:3으로 나뉨
X = [
[1, 2, 3 ],
[3, 4, 5 ],
[5, 6, 7 ],
[7, 8, 9 ]
]
y = [0, 1, 0, 1 ] #
X_train , X_test , y_train, y_test = train_test_split(X, y, test_size = 0.3) # 7/3, 8/2, 7/2/1
# 데이터가 랜덤으로 출력됨
print('train 데이터 X', X_train)
print('train 데이터 y', y_train)
print('='*35)
print('test 데이터 X', X_test)
print('test 데이터 y', y_test)

안녕하세요. 도야입니다