수업 내용
- Numpy
- Pandas
Numpy
- Python에서 과학 연산을 위한 가장 기본적인 라이브러리
- 행렬, 백터 연산을 위한 라이브러리로 처리속도가 빠름
- 다차원 배열과 행렬 객체가 포함
Python의 list와의 차이점
| 비교 항목 | list | numpy (numpy.ndarray) |
|---|---|---|
| 자료형 | 서로 다른 자료형 저장 가능 | 동일한 자료형만 저장 |
| 연산 속도 | 느림 (for문 사용 시 비효율적) | 빠름 (벡터화 연산 지원) |
| 메모리 사용 | 상대적으로 큼 | 상대적으로 적음 |
| 연산 방식 | 요소별 연산 (루프 필요) | 배열 단위 연산 (벡터 연산 가능) |
| 기능 | 기본적인 리스트 조작 | 수학 및 과학 연산 최적화 지원 |
Numpy 사용하기
- $ pip install numpy 명령어를 이용해서 설치 필요
- 단 아나콘다, 미니콘다 패키지를 설치하면 자동으로 설치가 됨
- Google에서 제공하는 colab의 경우 따로 설치할 필요 없음
Numpy를 사용하는 이유
- 빠른 연산 속도
- Python의 List보다 훨씬 빠른 연산이 가능
- 백터화 연산 지원으로 반복문 없이도 수학 연산을 효율적으로 처리 가능
- 메모리 효율성
- 동일한 자료형만 저장하므로 일반 python list보다 메모리를 적게 사용
- 대량의 데이터를 다룰 때 더욱 효율적
- 다양한 수학 및 선형대수 기능 제공
- 행렬 연산, 미분, 통계, 난수 생성등 다양한 기능이 내장되어 있음
- 머신러닝에서 행렬 연산이 핵심 -> 빠르고 효율적으로 처리 가능
numpy와 list 연산 속도 비교
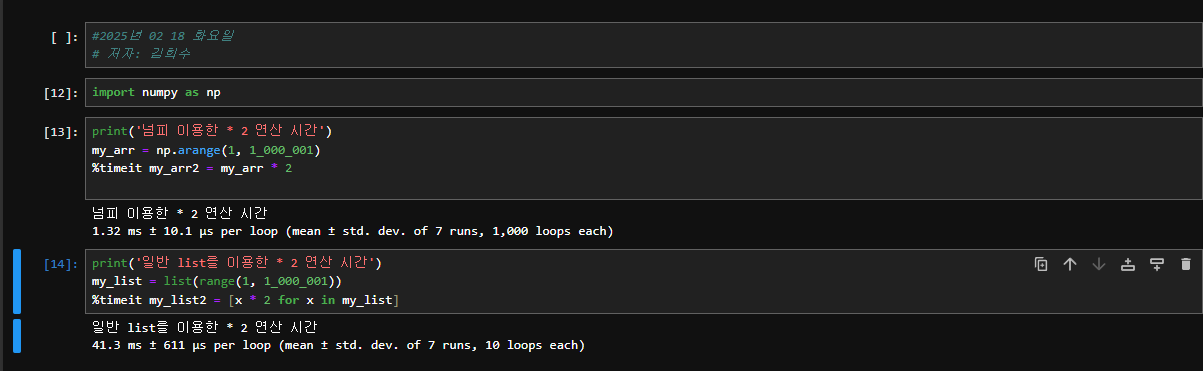
Numpy를 이용한 간단한 예제
1. shape, ndim, size 사용해보기
import numpy as np
rng = np.random.default_rng(seed = 1234) #시드값 -> 난수 발생시 같은 데이터 유지
myarray = rng.standard_normal((5)) # 열만 지정
print(myarray)
print()
print('myarray정보 shape', myarray.shape) # myarray정보 shape (5,)
print('myarray정보 ndim', myarray.ndim) # 1차원
print('myarray정보 size', myarray.size) # 5
print('myarray정보 len', len(myarray)) # 비권장
print()
print('평균', myarray.mean())
print('평균', np.mean(myarray))
print('열총점', sum(myarray)) # 열단위로
print('전체총점', np.sum(myarray))
print()
print('열평균', myarray.mean(axis=0)) # 세로 각 열의 평균shape 사용시 주의점
만약 1차원 배열로 선언되면 shape의 결과값은 (4,)이 나옴
배열의 구조가 2 * 3이면 shape의 결과 값은 (2, 3)이라 나옴
2. numpy를 이용한 최대값과 최소값, 중앙값, 총점, 평균, 분산, 표준편차 구하기
- 아래 코드는 2월 17일에 진행한 실습
# 최대값과 최소값, 중앙값, 총점, 평균
# 최종목표: 학습 분산, 표준편차
"""
분산: 데이터의 평균에서 퍼진 정도 -> 편차 평균의 제곱
표준편차: 분산의 제곱근(데이터의 단위와 같음)
"""
import math
import numpy as np
my = [175, 177, 179, 181, 183] # 숫자 리스트항목 int 숫자데이터 = 변량
data = np.array(my)
my_median = np.median(data) # 중앙값 구하기
tot = 0
avg = 0
tot = sum(data)
avg = np.mean(data) #평균 구하기
my_var = np.var(data) # 분산 구하기
my_std = np.std(data)# 표준편차 구하기
print(f'최대값 = {max(data)}')
print(f'최소값 = {min(data)}')
print(f'중앙값 = {my_median}')
print(f'총점 = {tot}')
print(f'평균 = {avg}')
print(f'분산 = {my_var}')
print(f'표준편차 = {my_std}')3. Numpy의 난수 생성
import numpy as np
a = np.random.randint(1,46,1) # 1부터 45까지 1개만 발생
print(a)
print()
b = np.random.randint(1,46,6) # 1부터 45까지 6개만 발생
print(b)
print()
c = np.random.uniform(1,46,6) # 1부터 45까지 6개만 발생 실수 형태
print(c)
print()
d = np.random.rand(15).shape(5,3) # 실수형태 5,3
print(d)
print()Pandas
- Python에서 데이터 분석 라이브러리 중 하나
- 데이터 조작, 정제, 분석, 시각화등을 위한 기능 제공
- 시리즈(Serise)와 데이터프레임(DataFrame)이라는 자료형을 이용하여 데이터를 처리
시리즈(Serise)와 데이터프레임(DataFrame)
Pandas에서 시리즈와 데이터프레임을 따로 만들어사 사용하는 이유는 데이터 분석을 좀 더 쉽고 효율적으로 하기 위해서 사용
시리즈(Serise)
- 1차원 배열 형태로 구성
- index와 value로 이루어져 있음
- 리스트나 딕셔너리를 변환해서 만들 수 있음
데이터프레임(DataFrame)
- 여러개의 시리즈가 모여서 만든 테이블 형태의 데이터
- 행과 열로 구성되어 있음
loc를 이용한 간단한 실습
import pandas as pd
path = './data/score.csv'
score = pd.read_csv(path) # 한글이 아니면 인코딩 안해도 됨
#1
print(score.loc[5:10])
print()
#2
print(score.loc[: , 'kor' : 'mat'])
print()
#3
print(max(score.loc[: , 'kor']))
print(score['kor'].max())
#4
kor = score.kor # score에 kor 필드
eng = score['eng']
mat = score.mat
total = kor + eng + mat
avg = round(total/3 , 2)
score.insert(5,['total'], total, True)
score.insert(6,['avg'], avg, True)
print(score)
#5
score2 = score.loc[:, ['no','total', 'avg']]
print(score2)
안녕하세요. 도야입니다