개요
- 2월 19일 교육 내용 정리
- Pandas를 이용한 실습
- Matplolib 사용해보기
Pandas
- 데이터탐색및 데이터 전처리 담당
- DataFrame생성, Series 작업처리 편리
- 파일 데이터 로드, 저장 편리한 다양한 함수 제공
- 다양한 통계 분석 함수 제공
- 상관관계 분석에 numpy, pandas 많이 사용
- 결측값(null), 이상치데이터조절 가능
- 행병합, 열병합, 조건에 따른 병합 가능
실습 1
- csv의 열 추가
- 새로운 csv파일로 저장해보기
import pandas as pd
path='./data/score.csv'
score = pd.read_csv(path) #csv파일 열기
kor = score.kor
eng = score.eng
mat = score.mat
total = kor + eng + mat
avg = round(total/3 , 2)
# tot, avg 추가
score.insert(5,['tot'], total, True)
score.insert(6,['avg'], avg, True)
print(score)
# score_all.cvs
score_all = pd.DataFrame(score)
score_all.to_csv('./data/score_all.csv')
print('./data/score_all.csv 저장성공')실습 2
- 데이터 추출
- score_sample에서 7개의 데이터만 추출하기
print('데이터 추출')
score_sample = score.sample(7)
print(score_sample)
score_sample = pd.DataFrame(score_sample)
score_sample.to_csv('./data/score_sample.csv')loc()과 iloc()
- loc vs iloc 차이 정리
| 비교 항목 | loc (라벨 기반) | iloc (정수 기반) |
|---|---|---|
| 기반 | 행과 열의 라벨(이름) | 행과 열의 정수 인덱스 |
| 슬라이싱 | 끝 인덱스 포함 | 끝 인덱스 미포함 |
| 사용 예시 | df.loc['a', '이름'] | df.iloc[0, 0] |
| 적용 대상 | 인덱스 라벨이 있는 경우 유용 | 정수 인덱스가 필요한 경우 유용 |
loc: 행/열 이름(라벨)로 접근할 때 사용iloc: 행/열의 위치(정수 인덱스)로 접근할 때 사용
실습
# loc[시행: 끝, 시열: 끝열]
print()
print(score.loc[:, ['no', 'tot', 'avg']])
#iloc는 정수값을 받아야 함
# 만약 필드의 이름이 길때 사용하면 좋음
print(score.iloc[:, [0, 5, 6]])
데이터 삭제
drop()을 이용해서 삭제- pay가 400보다 크면 삭제
import pandas as pd
fname = './data/emp.csv' # encoding='euc-kr',encoding='cp949' 둘중 하나 사용(한글이 들어간 파일 사용시 )
emp = pd.read_csv(fname, encoding='euc-kr')
empCopy = emp
data = empCopy[emp['Pay'] >= 400].index
print(f'data = {data}')
time.sleep(1)
remove = empCopy.drop(data)
print(remove)
print()
fname = './data/empCopy.csv'
remove.to_csv(fname)
print('./data/empCopy.csv 저장 완료')
print(fname)Matplotlib
- python에서 가장 널리 사용되는 가상화 라이브러리
- 막대 그래프, 상자 그림, 선 그래프, 산점도, 히스토그램 등 기본적인 통계 그래프 기능
- 각종 서식을 커스터마이즈하는 기능도 제공
Matplotlib같은 경우 앞으로도 많이 사용될 라이브러리로 좀 더 학습하고 자세히 정리 예정
이번 정리에선는 어떤 형식으로 사용하는지 알아보는 체험판 느낌
matplotlib 사용해보기
plot(): 2D 그래프를 그릴 때 가장 기본적으로 사용하는 함수plt.show()가 있어야 그래프 화면을 보여주지만, colab이나 jupyter같은 경우 생략해도 됨
import matplotlib.pyplot as plt
import numpy as np
x = np.linspace(0, 2 * np.pi, 200)
y = np.sin(x)
plt.title('plot line')
fig, ax = plt.subplots()
ax.plot(x, y)
plt.show()
marker 사용해보기
mrker: 그래프에서 데이터를 표시할 도형 종류를 입력할 수 있음- 종류
| 마커 모양 | 코드 (marker='') | 설명 |
|:--------:|:-----------------:|:---------------------------:|
| ● |'o'| 원 (circle) |
| ▲ |'^'| 위쪽 삼각형 (triangle up) |
| ▼ |'v'| 아래쪽 삼각형 (triangle down) |
| ◀ |'<'| 왼쪽 삼각형 (triangle left) |
| ▶ |'>'| 오른쪽 삼각형 (triangle right) |
| ■ |'s'| 정사각형 (square) |
| ♦ |'D'| 다이아몬드 (diamond) |
| ⬟ |'p'| 오각형 (pentagon) |
| ⬢ |'h'| 육각형 (hexagon1) |
| ★ |'*'| 별 (star) |
| ➕ |'+'| 더하기 (plus) |
| ✖ |'x'| X자 (cross) |
| │ |'|'| 수직선 (vline) |
| ─ |'_'| 수평선 (hline) |
import matplotlib.pyplot as plt
import numpy as np
year =[1950, 1960, 1970, 1980, 1990, 2000, 2010]
gdp = [300.2, 543.3, 1075.9 , 2862.5, 3979.6, 10299.7,14989.3]
plt.plot(year, gdp, color = 'green', marker = 'o', linestyle = 'solid' )
plt.title('Nominal GDP')
plt.ylabel('Billions of $')
plt.show()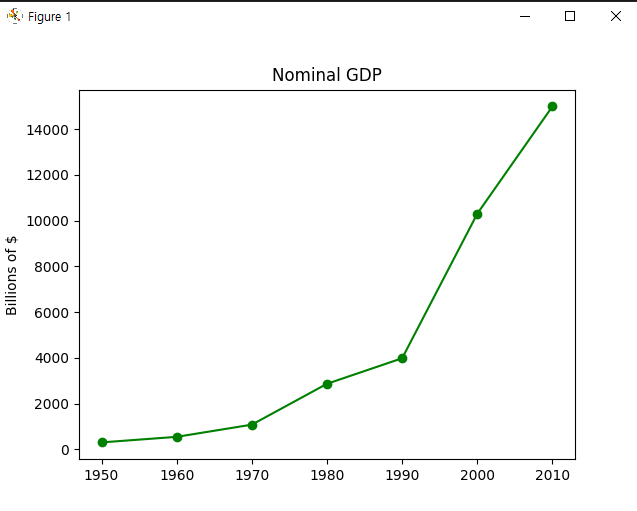
subplots를 이용하기
- Matplotlib에서 여러 개의 그래프를 한번에 그릴 때 사용하는 함수
# subplots
import matplotlib
import matplotlib.pyplot as plt
import numpy as np
from matplotlib import font_manager
from matplotlib import rc
font_name = font_manager.FontProperties(fname='c:/windows/Fonts/malgun.ttf').get_name()
matplotlib.rc('font', family=font_name)
x = np.linspace(0, 2 * np.pi, 200)
y = np.sin(x)
# subplots 사용해보기
y1 = [20,50,74,30] #y축값
y2 = [90,60,70] #y축값
y3 = np.random.randint(5,35,5) #y축값
y4 = [30,90,10,60,80]
fig, ax = plt.subplots(2,2, figsize = (15,10)) # shary는 공유한다는 뜻
ax[0,0].bar(['노래', '게임', '드라마', '영화'],y1)
ax[0,0].set_title('좋아하는 취미 장르')
ax[0,1].scatter(['python', 'c#', 'cpp'],y2)
ax[0,1].set_title('코드 선호')
ax[1,0].plot(['빨강', '파랑', '초록', '자주', '하늘'],y3)
ax[1,0].set_title('색깔별 구입 현황')
ax[1,1].bar(['찰리', '리제', '존','리사', '톰'],y4)
ax[1,1].set_title('사원 점수')
fig.suptitle('2025년 ESTSoft 고객 동향')
plt.show()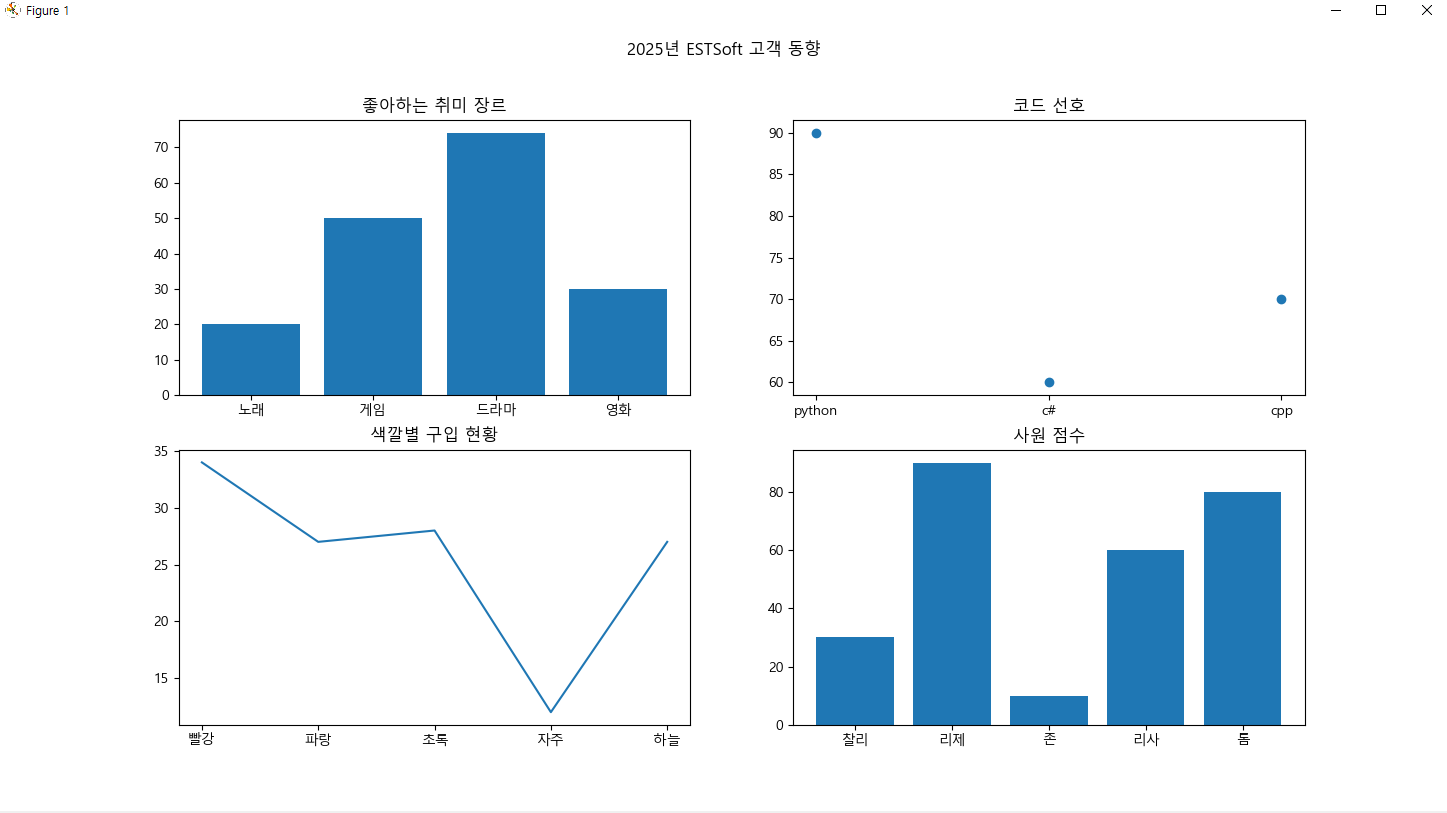

안녕하세요. 도야입니다