사용 데이터 셋
- Seaborn의 dataset중 타이타닉 데이터 이용
- 결칙치 해결 및 roc 곡선 그래프 그리기
데이터 로드 및 정보 보기
df = sns.load_dataset('titanic')
print(df.info())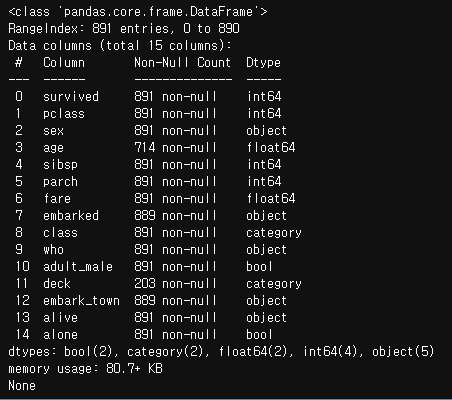
필요없는 데이터 제거
- 이번에는 nan값이 들어있는 행을 drop할 예정
df_new = df.drop( ['deck', 'embark_town'] , axis=1)
df_new = df_new.dropna(subset=['age', 'embarked'],how='any', axis=0) age, embrak의 데이터 숫자화
sex_dummy = pd.get_dummies(df_new['sex'])
df_new = pd.concat([df_new , sex_dummy] , axis=1)
embarked_dummy = pd.get_dummies(df_new['embarked'], prefix='town')
df_new = pd.concat([df_new , embarked_dummy] , axis=1)train,test 데이터 분리 및 데이터 스케일링
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
standard = StandardScaler()
standard.fit(X_train)
X_train_scaler = standard.transform(X_train)
X_test_scaler = standard.transform(X_test)다양한 모델 학습 및 평가
- svc, lr, dt로 학습
- svc와 lr은 스케일러 전후의 모델 학습도 진행함
# SVC - 스케일러 적용 데이터
model_svc = SVC(kernel='rbf', probability=True)
model_svc.fit(X_train_scaler, y_train)
pred_svc = model_svc.predict(X_test_scaler)
# SVC - 스케일러 적용 전 데이터
model_svc1 = SVC(kernel='rbf', probability=True)
model_svc1.fit(X_train, y_train)
y_pred_svc1 = model_svc1.predict(X_test)
# lr - 스케일러 적용 데이터
model_lr = LogisticRegression(max_iter=1000) # 1000번 반복 학습
model_lr.fit(X_train_scaler, y_train)
y_pred_lr = model_lr.predict(X_test_scaler)
# lr - 스케일러 적용 전 데이터
model_lr1 = LogisticRegression(max_iter=1000) # 1000번 반복 학습
model_lr1.fit(X_train_scaler, y_train)
y_pred_lr1 = model_lr.predict(X_test)
# dt
model_dt = DecisionTreeClassifier()
model_dt.fit(X_train_scaler, y_train)
y_pred_dt = model_dt.predict(X_test_scaler)accuracy_score 비교
models = ['SVC', 'SVC1','LR', 'LR1', 'DT']
accuracies = [accuracysvc, accuracysvc1, accuracylr,accuracylr1, accuracydt]
plt.figure(figsize=(8, 5))
plt.bar(models, accuracies, color=['blue', 'red', 'green', 'orange', 'purple'])
# 각 막대 위에 정확도 값 추가
for i, acc in enumerate(accuracies):
plt.text(i, acc + 0.02, f"{acc:.2f}", ha='center', fontsize=12)
# 그래프 설정
plt.ylim(0, 1) # 정확도는 0~1 사이
plt.xlabel("Model")
plt.ylabel("Accuracy")
plt.text(0.1, 0.9, "SVC1, lr1: 스케일러 미적용", fontsize=12, color="black", bbox=dict(facecolor='white', edgecolor='black', boxstyle='round,pad=0.5'))
plt.title("Model Accuracy Comparison")
plt.grid(axis='y', linestyle='--', alpha=0.7)
plt.show()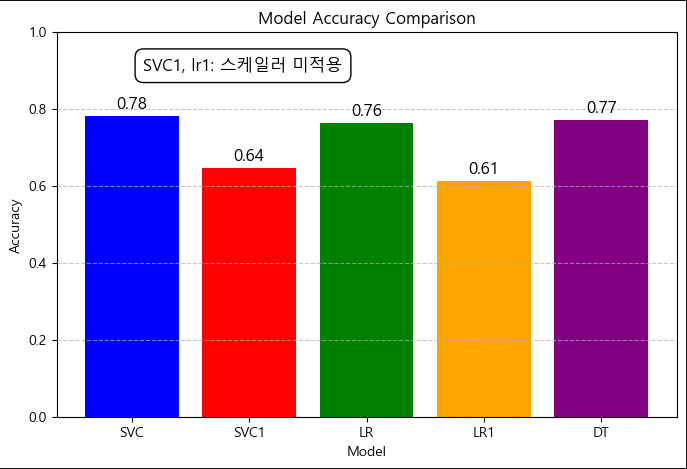
Roc 곡선 그래프 그리기
y_pred_proba_lr = model_lr.predict_proba(X_test_scaler)[:, 1]
y_pred_proba_lr1 = model_lr1.predict_proba(X_test)[:, 1]
y_pred_proba_svc = model_svc.predict_proba(X_test_scaler)[:, 1]
y_pred_proba_svc1 = model_svc.predict_proba(X_test)[:, 1]
y_pred_proba_dt = model_dt.predict_proba(X_test_scaler)[:, 1]
# ROC Curve 계산
fpr, tpr, thresholds = roc_curve(y_test, y_pred_proba_lr)
fpra, tpra, thresholds = roc_curve(y_test, y_pred_proba_lr1)
fpr1, tpr1, z = roc_curve(y_test, y_pred_proba_svc)
fpr2, tpr2, z = roc_curve(y_test, y_pred_proba_dt)
fpr3, tpr3, z = roc_curve(y_test, y_pred_proba_svc1)
# AUC Score 계산
auc_score_lr = roc_auc_score(y_test, y_pred_proba_lr)
auc_score_lr1 = roc_auc_score(y_test, y_pred_proba_lr1)
auc_score_svc = roc_auc_score(y_test, y_pred_proba_svc)
auc_score_svc1 = roc_auc_score(y_test, y_pred_proba_svc1)
auc_score_dt = roc_auc_score(y_test, y_pred_proba_dt)
plt.figure(figsize=(10, 7))
sns.lineplot(x=fpr, y=tpr, label=f"LR (AUC = {auc_score_lr:.3f})", linewidth=2)
sns.lineplot(x=fpra, y=tpra, color='black' ,label=f"LR1 (AUC = {auc_score_lr1:.3f})", linewidth=2)
sns.lineplot(x=fpr1, y=tpr1, color='r', label=f"SVC (AUC = {auc_score_svc:.3f})", linewidth=2)
sns.lineplot(x=fpr2, y=tpr2, color='g', label=f"DT (AUC = {auc_score_dt:.3f})", linewidth=2)
sns.lineplot(x=fpr3, y=tpr3, color='y', label=f"SVC1 (AUC = {auc_score_svc1:.3f})", linewidth=2)
# 랜덤 분류 기준선
plt.plot([0,1], [0,1], linestyle="--", color="gray")
# SVC1에 대한 설명 추가
plt.text(0.6, 0.3, "SVC1, lr1: 스케일러 미적용", fontsize=12, color="black", bbox=dict(facecolor='white', edgecolor='black', boxstyle='round,pad=0.5'))
# 그래프 설정
plt.xlabel("False Positive Rate")
plt.ylabel("True Positive Rate")
plt.title("Titanic Roc Curve 그래프")
plt.legend()
plt.grid(True)
plt.show()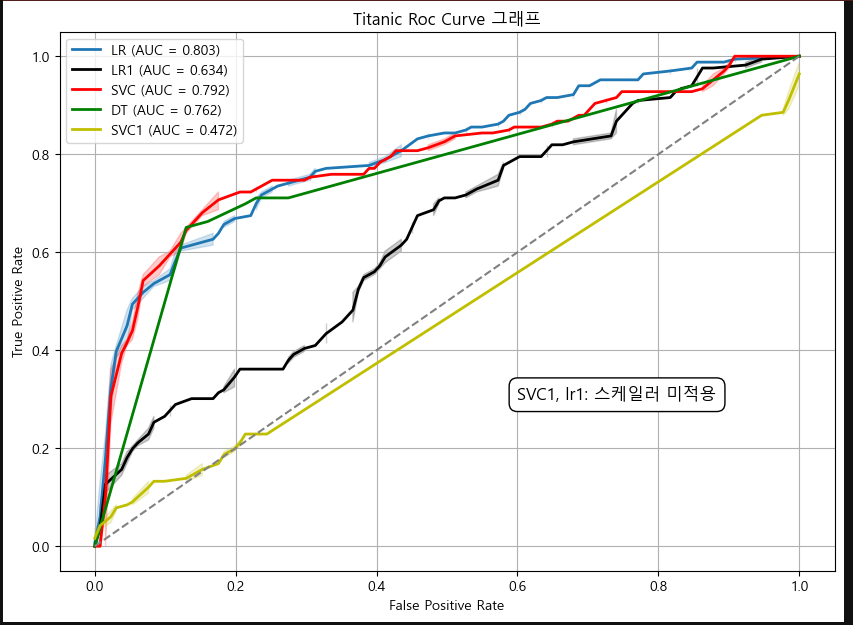

안녕하세요. 도야입니다