개요
- 4일차 내용정리
- 5일차 내용정리
4일차(5월22일)
- CodeTalker 모델 테스트
비고: stage1_vocaset.py 의 학습모델 파일의 부재로 CodeTalker Test 학습 모델로 진행함
해당 코드는 안 맞는 모델 파일을 사용하여 그에따른 조정이 들어감
이후 정확한 모델 파일 사용시 코드 수정 필요
모델 불러오기
import torch
from models.stage2 import CodeTalker
from models.stage1_vocaset import VQAutoEncoder
from models.utils import init_biased_mask, enc_dec_mask, PeriodicPositionalEncoding
from models.lib.wav2vec import Wav2Vec2Model
import torchaudio
import yaml
from easydict import EasyDict as edict
from types import SimpleNamespace
yaml_path = '모델 경로'
def flatten_dict(d, parent_key='', sep='_'):
items = {}
for k, v in d.items():
new_key = f"{parent_key}{sep}{k}" if parent_key else k
if isinstance(v, dict):
items.update(flatten_dict(v, new_key, sep=sep))
else:
items[new_key] = v
return items
with open(yaml_path, 'r') as f:
yaml_data = yaml.safe_load(f)
flat = flatten_dict(yaml_data)
모델 시각화 결과
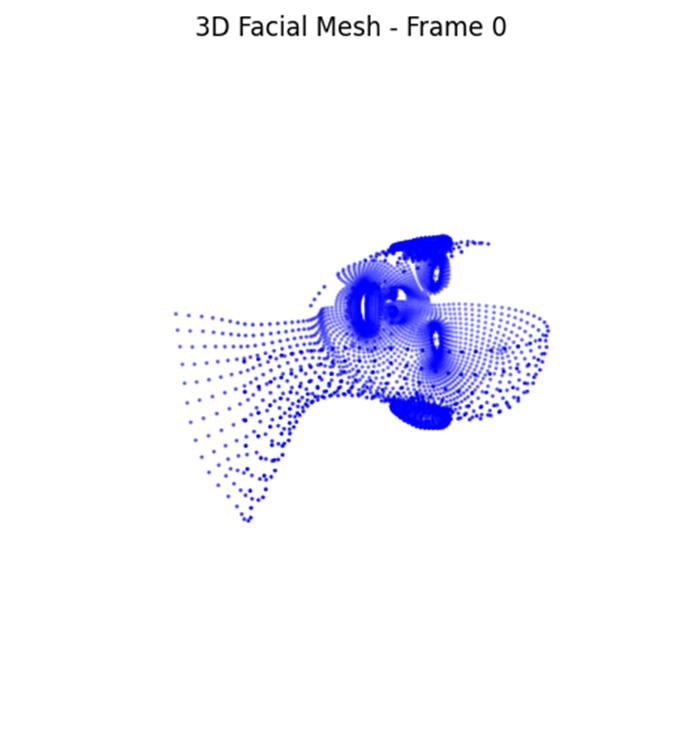
문제점:
모델이 제대로 동작하는지 확인 불가
현재 MP4 파일 확인시 입이 움직임을 보이고 있지 않음
5일차(5월23일)
개요
- 🇰🇷 한국인 피부상태 측정 데이터 분석
- 모델 확인
5일차
- 🇰🇷 한국인 피부상태 측정 데이터 분석
github 주소
https://github.com/leejeongho3214/NIA
목표
- 5월 30일까지 해당 모델 파악 및 엔드포인트 제작
정리
- ResNet-50 기반 모델
- CheckPoint는 각 부분(눈, 입, 이마, 턱 등)의 모델 파일들로 분류되어 있음
- 눈과 볼 같은 경우 하나의 모델이 양쪽의 데이터를 분석하는데 쓰임
해결해야 하는 점
-
해당 데이터에는 bbox의 데이터도 같이 들어가 있어서 프로젝트 적용시 bbox의 처리를 어떻게 할 것인가
-
엔드 포인트를 어떻게 구현 할 것인가

안녕하세요. 도야입니다