✅혼자 공부하는 머신러닝+딥러닝
진도: Chapter 05
실습파일 : Wine.ipynb

(완료) 기본미션 : 교차 검증을 그림으로 설명하기
(완료) 선택미션 : Ch.05(05-3) 앙상블 모델 손코딩 코랩 화면 인증하기
✅05-1 : 결정 트리
결정 트리 - 리프 노드에서 가장 많은 클래스가 예측 클래스가 된다.
로지스틱 회귀와 달리, 트리 모델은 표준화 전처리를 할 필요 없는 것이 장점.
- 루트 노드 정보 :
테스트 조건(column) / 불순도(gini) / 총 샘플 수(samples) / 클래스별 샘플 수(value)
- 왼쪽 가지 - 조건 만족(yes), 오른쪽 가지 - 조건 불만족(no)
value = [음성 클래스 수, 양성 클래스 수]
filled = True 일 때)
음성 클래스(0) 수가 많으면 주황색, 양성 클래스(1) 수가 많으면 파란색
- 지니 불순도 Gini impurity
노드의 클래스 비율을 제곱한다.
= 1 - (음성클래스비율^2 + 양성클래스비율^2)
노드에 하나의 클래스만 있다면 지니 불순도는 0. 순수 노드.
- 엔트로피 불순도 : DecisionTreeClassifier(criterion='entropy')
노드의 클래스 비율을 밑이 2인 log를 사용하여 곱한다.
= -음성클래스비율 x log2(음성클래스비율) -양성클래스비율 x log2(양성클래스비율)
- 정보 이득 Information gain : 부모 노드(parent node)와 자식 노드(child node)의 불순도 차이.
DecisionTree는 정보 이득이 최대가 되도록 데이터를 다루는 알고리즘이다.부모의 불순도 - (왼쪽 노드 샘플 수 / 부모의 샘플 수)x왼쪽 노드 불순도 - (오른쪽 노드 샘플 수 / 부모의 샘플 수)x오른쪽 노드 불순도 = 정보이득
- 가지치기 - 자라날 수 있는 트리의 최대 깊이 지정 (max_depth= )
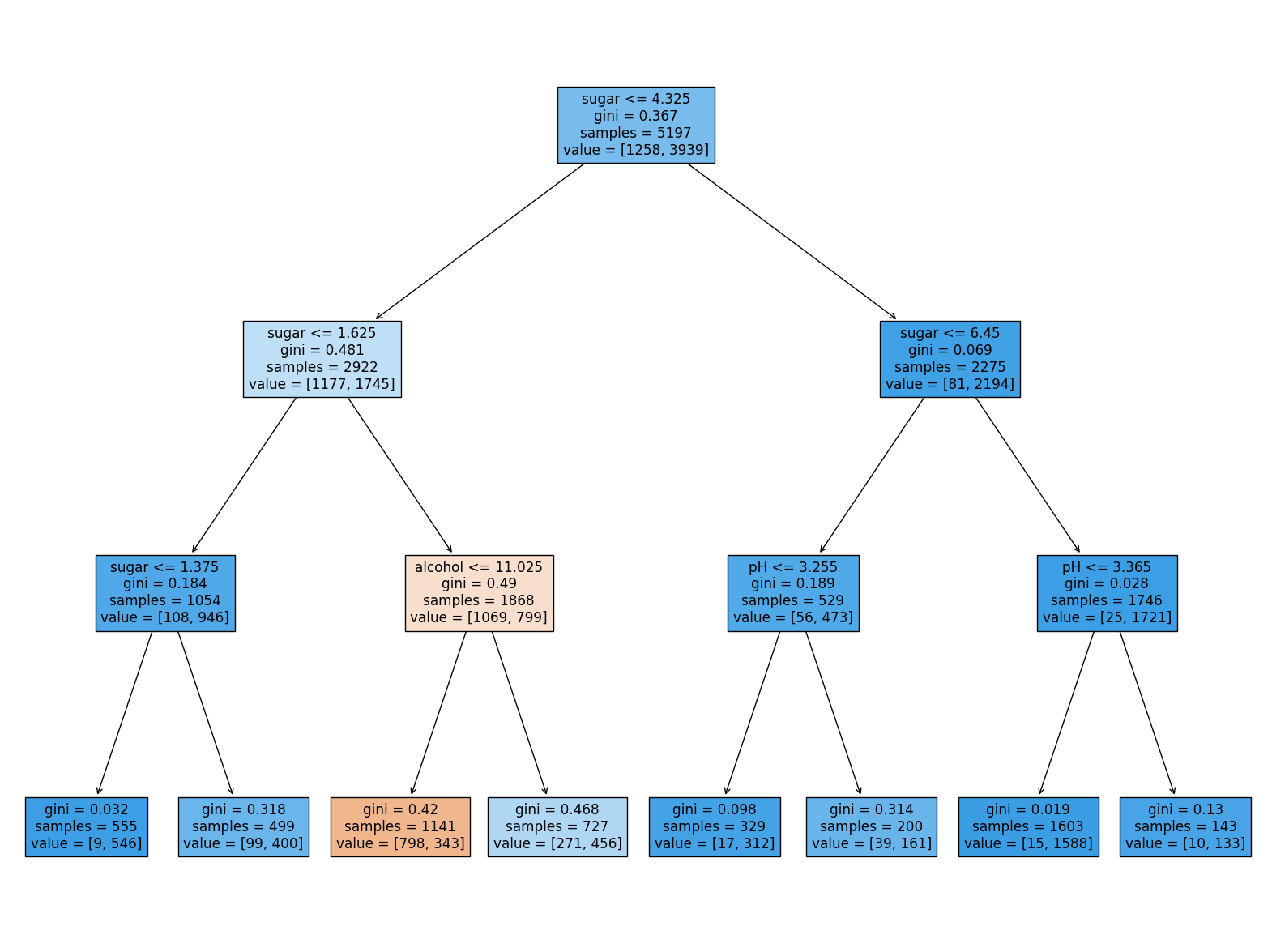
#결정 트리 Decision Tree - 클래스 생성 from sklearn.tree import DecisionTreeClassifier dt = DecisionTreeClassifier(random_state=42, max_depth=3) dt.fit(train_scaled, train_target) print(dt.score(train_scaled, train_target)) print(dt.score(test_scaled, test_target))#결정 트리 Decision Tree - 트리 시각화 import matplotlib.pyplot as plt from sklearn.tree import plot_tree plt.figure(figsize=(20,15)) plot_tree(dt, filled=True, feature_names=['alcohol', 'sugar', 'pH']) plt.show()ex) 0: 레드와인, 1: 화이트와인
하기 트리의 특성 중요도를 볼 때, 테스트 조건으로 'sugar'가 가장 유용한 특성이다.
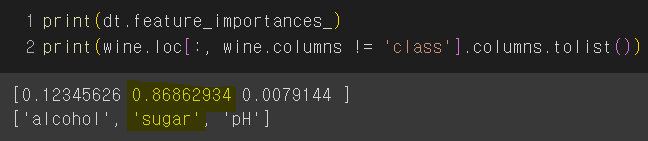
- scikit-learn
DecisionTreeClassifier
(min_samples_split = 2) 노드를 나누기 위한 최소 샘플 개수
(max_features = None) 최적의 분할을 위해 탐색할 특성의 개수를 지정, None은 모든 노드 사용
(splitter = 'best') 노드를 분할하는 전략을 선택. best는 정보이득이 최대가 되도록. random이면 임의로 노드를 분할.
(criterion = 'gini') 불순도를 지정. 지니 / 엔트로피(min_impurity_decrease = 0.0) 노드를 분할하기 위한 불순도 감소 최소량
이 매개변수는 트리 성장을 조기에 중지하기 위한 임계값을 지정합니다. 불순물 감소량이 이 값보다 작으면 노드가 더 이상 분할되지 않습니다. 지정하지 않으면 기본값은 0.0입니다. 즉, 모든 리프가 순수해질 때까지 또는 모든 리프에 필요한 최소 샘플보다 적은 양이 포함될 때까지 트리가 확장됩니다.
#while [정보 이득 x (노드의 샘플 수) / (전체 샘플 수) < min_impurity_decrease]성장을 early stopping 하여 좌우가 균일하지 않은 트리가 만들어진다.
매개변수 값이 클 수록 조기에 성장을 멈춘다. (리프가 덜 순수해도)
ex) 변수값 0.0005인 경우, 변수값 0.05인 경우
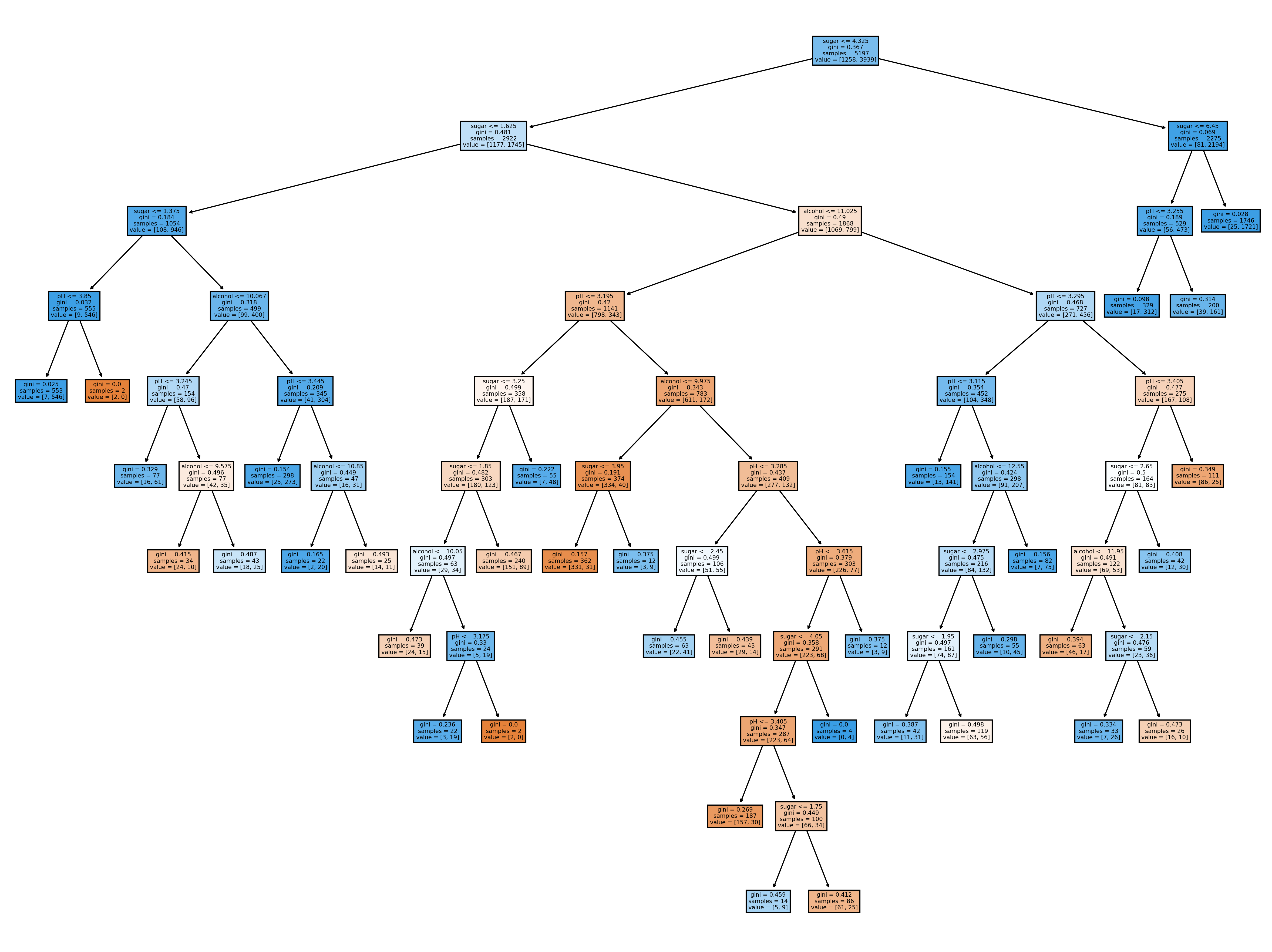

>plt.figure(dpi=100)
dpi는 인치당 도트 해상도(dot per inch)를 나타내는 매개변수입니다.
dpi가 높을수록 이미지의 해상도가 더 높아집니다.✅05-2 : 교차 검증과 그리드 서치
#테스트 세트로 일반화 성능을 올바르게 예측하려면, 가능한 한 테스트 세트를 사용하지 말아야 한다. 모델을 다 만들고 마지막에 딱 한번만 사용하는 것이 좋다.
-> 매개변수를 어떻게 테스트 해야할까?
-> 훈련 세트를 또다시 [훈련세트 : 검증세트]로 나눈다.
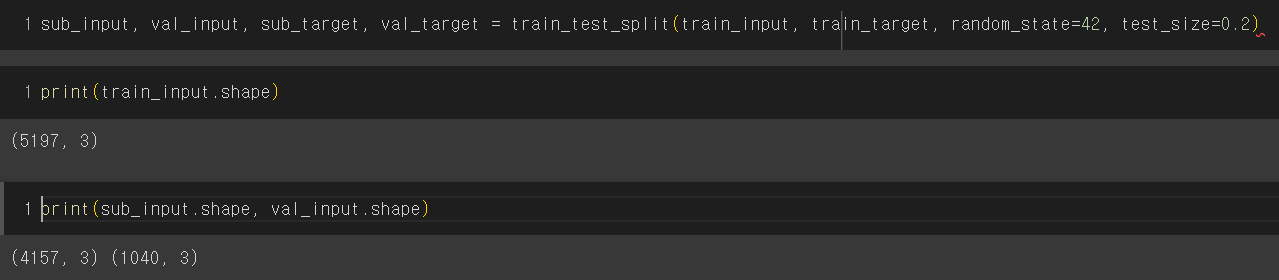
sub_input, val_input, sub_target, val_target = train_test_split(
train_input, train_target, random_state=42, test_size=0.2)
print(train_input.shape) #(5197, 3)
print(sub_input.shape, val_input.shape) #(4157, 3) (1040, 3)
- 검증 세트
보통 20~30%.
훈련 데이터가 아주 많다면 몇%로도 전체 데이터를 대표 가능.
train [sub 훈련세트 60% + val 검증세트 20%] + test 테스트세트 20%
1) 매개변수(hp) 튜닝 : 훈련세트로 훈련 & 검증세트로 모델평가 -> 최적의 모델을 찾기
2) 모델 훈련 : 훈련+검증세트로 훈련
3) 모델 평가 : 테스트세트로 평가
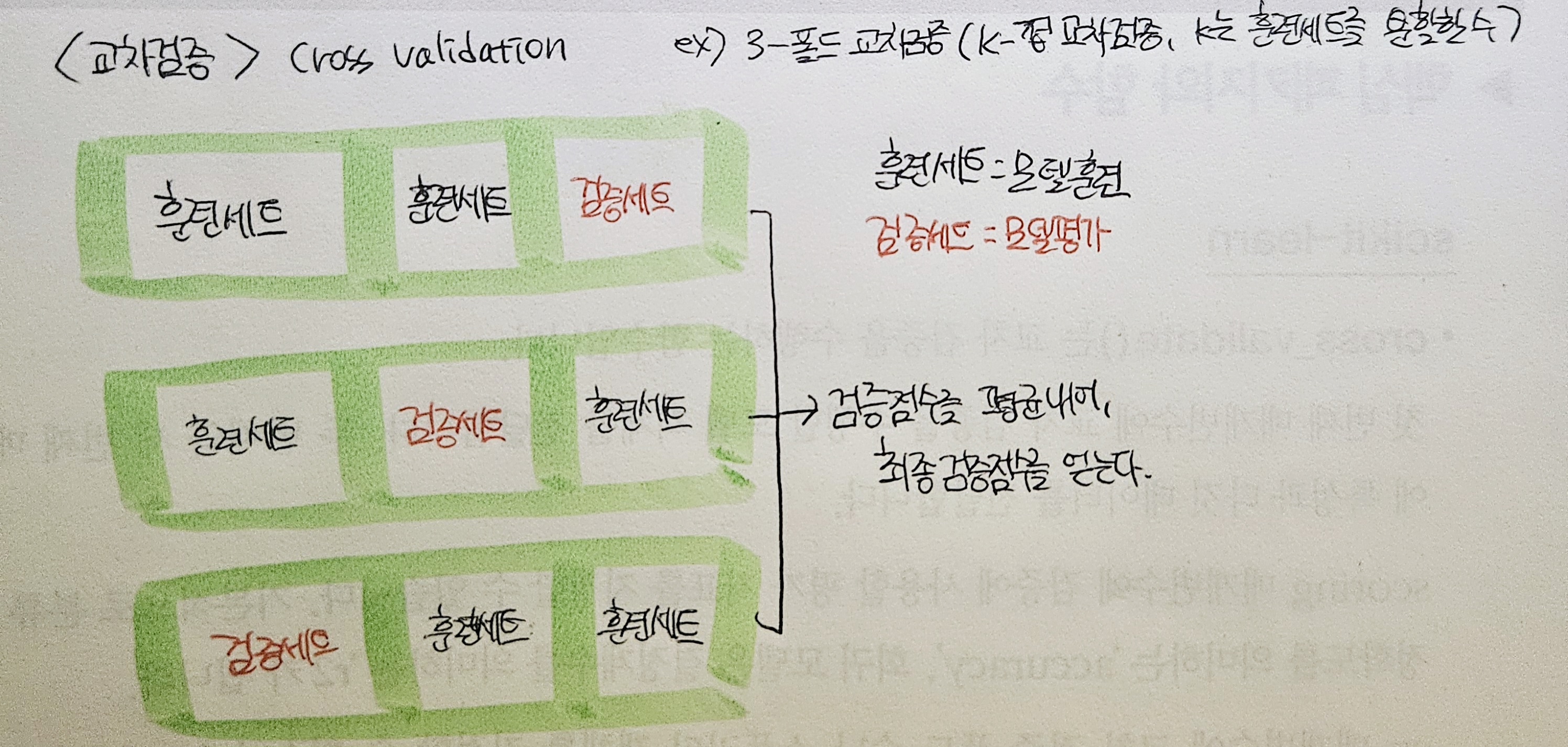
교차 검증
- 훈련 세트를 안섞는 경우 - 교차 검증 함수 사용
cross_validate() : k-폴드 교차검증. 기본값은 5-폴드. (fit_time, score_time, test_score 출력)
cross_val_score() : (test_score 값만 반환)
from sklearn.model_selection import cross_validate
scores = cross_validate(dt, train_input, train_target) #평가할모델객체,훈련세트전체
print(scores)
#{'fit_time': array([0.01641798, 0.01090574, 0.01131606, 0.01067281, 0.01104331]),
'score_time': array([0.00216198, 0.00213552, 0.00190568, 0.00208831, 0.00204754]), '
test_score': array([0.86923077, 0.84615385, 0.87680462, 0.84889317, 0.83541867])}
#fit time = 모델을 훈련하는 시간
#score time = 모델을 검증하는 시간
#test score = 검증 폴드의 점수(키에 담긴 value가 5개로 출력되기 때문에, np.mean으로 얻은 평균값이 최종 점수.)
import numpy as np
np.mean(scores['test_score'])
- 훈련 세트를 섞는 경우 - 분할기splitter를 추가로 import하고, 객체 값을 지정
n_splits= : 몇(k) 폴드 교차검증을 할지 정하는 매개변수.
from sklearn.model_selection import StratifiedKFold
splitter = StratifiedKFold(n_splits=10, shuffle=True, random_state=42)
scores = cross_validate(dt, train_input, train_target, cv=splitter)
print(scores)
print(np.mean(scores['test_score']))하이퍼파라미터 튜닝
- 그리드 서치 GridSearchCV : 하이퍼파라미터탐색 + 교차검증 수행
1) 클래스 임포트
2) 딕셔너리 만들기 {탐색할 매개변수 : 탐색할 값}
3) 그리드 서치 객체 만들기
from sklearn.model_selection import GridSearchCV
params = {'min_impurity_decrease': [0.0001, 0.0002, 0.0003, 0.0004, 0.0005]}
gs = GridSearchCV(DecisionTreeClassifier(ramdom_state=42), params, n_jobs=-1)
gs.fit(train_input, train_target)
#매개변수 : 결정트리클래스의 객체, parameter, n_jobs=n
#n_jobs는 병렬 실행에 사용할 CPU 코어 수를 지정한다. 기본값은 1이며, -1인 경우 시스템의 모든 코어를 사용.
4) 그리드 서치의 cv 기본 값은 5이므로, 파라미터 하나당 5번씩 모델훈련.
-> 5폴드 * 파라미터 총 5개 = 25개의 모델을 훈련한다.
5) 검증점수가 가장 높았던 모델의 매개변수 조합으로 전체 훈련세트에서 자동으로 다시 모델을 훈련함.
->해당 베스트 모델은 gs객체의 'best_estimator' 속성에 저장되어 있음
->해당 베스트 매개변수는 gs객체의 'best_params' 속성에 저장되어 있음
#베스트 모델을 결정트리처럼 사용하여 평가하기
dt = gs.best_estimator_
print(dt.score(train_input, train_target))
#0.9615162593804117
print(gs.best_params_)
#{'min_impurity_decrease': 0.0001}
- 랜덤 서치 RandomizedSearchCV
✅05-3 : 트리의 앙상블
앙상블 학습(미션
랜덤 포레스트
엑스트라 트리
그레이디언트 부스팅
히스토그램 기반-그레이디언트 부스팅
- scikit-learn
RandomForestClassifier
ExtraTreesClassifier
GradientBoostingClassifier
HistGradientBoostingClassifier
