✅혼자 공부하는 머신러닝+딥러닝
진도: Chapter 04
keyword : 지도학습 알고리즘 > 분류 > 다중 분류 multi-class classification > 로지스틱 회귀 Logistic Regression (이진분류,다중분류) > 확률 예측
실습파일 : Lucky_Bag.ipynb

(완료) 기본 미션 : Ch.04(04-1) 2번 문제 풀고, 풀이 과정 설명하기
- 풀이 : 로지스틱 회귀가 이진분류에서 확률을 출력하기 위해서는 시그모이드 함수를 사용한다.
시그모이드 함수는 선형 방정식의 결과를 0과 1사이의 값으로 압축하여 확률로 해석해준다.
phi = 1 / (1 + np.exp(-z))

(완료) 선택 미션 : Ch.04(04-2) 과대적합/과소적합 손코딩 코랩 화면 캡처하기
✅04-1 : 로지스틱 회귀
-
다중 분류 : 타깃 데이터에 2개 이상의 클래스가 포함된 문제
타깃 값을 사이킷런 모델에 전달하면 순서가 자동으로 알파벳 순으로 매겨진다.
정렬된 타깃값은 클래스명.classes_ 속성에 저장되어 있다.
클래스명.predict() -> 예측
클래스명.predict_proba() -> 클래스별 확률값을 반환 -
k-최근접 이웃 분류기의 확률 예측 :
이웃이 3일경우, 확률은 0/3, 1/3, 2/3, 3/3 으로 표현가능
데이터 준비하기.
1) 데이터프레임 준비 : Pandas
2) 데이터셋 준비 : Input/Target
Target ) unique로 fish['Species'] 특성 갯수 알기.
Input ) 나머지 column을 Input값으로 넣는다.
fish_input, fish_target
3) 데이터 분할 : Train/Test
from sklearn.model_selection import train_test_split
train_input, test_input, train_target, test_target = train_test_split(
fish_input, fish_target, random_state=42)
4) 데이터 정규화 : Train_scaled/Test_scaled
from sklearn.preprocessing import StandardScaler
ss = StandardScaler()
ss.fit(train_input)
train_scaled = ss.transform(train_input)
test_scaled = ss.transform(test_input)k-최근접 이웃 분류기의 확률 예측.
from sklearn.neighbors import KNeighborsClassifier
kn = KNeighborsClassifier(n_neighbors=3)
kn.fit(train_scaled, train_target)
print(kn.score(train_scaled, train_target))
print(kn.score(test_scaled, test_target))
#0.8907563025210085
#0.85
print(kn.predict(test_scaled[:5]))
#['Perch' 'Smelt' 'Pike' 'Perch' 'Perch']
import numpy as np
proba = kn.predict_proba(test_scaled[:5])
print(np.round(proba, decimals=4))
#[[0. 0. 1. 0. 0. 0. 0. ]
[0. 0. 0. 0. 0. 1. 0. ]
[0. 0. 0. 1. 0. 0. 0. ]
[0. 0. 0.6667 0. 0.3333 0. 0. ]
[0. 0. 0.6667 0. 0.3333 0. 0. ]]- 로지스틱 회귀 : 이름은 회귀지만 분류모델.
이 알고리즘은 선형 회귀와 동일하게 선형 방정식을 학습한다.
z = aw1 + bw2 + cw3 + dw4 + ew5 + bias
-> 확률이 되려면 z가 0~1 값이 되어야 함.
시그모이드 함수 : 1 / 1 + 자연상수e^-z
z가 아주 큰 음수일 때 0이 되고, 아주 큰 양수일 때 1이 된다.
1) 로지스틱 회귀 - 시그모이드 함수 출력해보기
import numpy as np
import matplotlib.pyplot as plt
z = np.arange(-5, 5, 0.1)
phi = 1 / (1 + np.exp(-z))
plt.plot(z, phi)
plt.xlabel('z')
plt.ylabel('phi')
plt.show()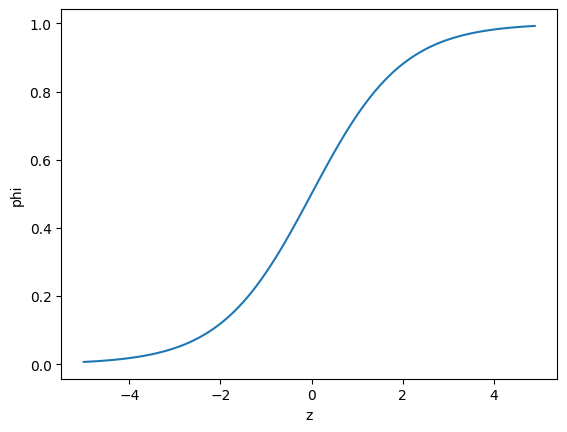
2) 로지스틱 회귀로 이진 분류 수행하기
char_arr = np.array(['A', 'B', 'C', 'D', 'E'])
print(char_arr[[True, False, True, False, False]])
#[A , C]
bream_smelt_indexes = (train_target == 'Bream') | (train_target == 'Smelt')
train_bream_smelt = train_scaled[bream_smelt_indexes]
target_bream_smelt = train_target[bream_smelt_indexes]
from sklearn.linear_model import LogisticRegression
lr = LogisticRegression()
lr.fit(train_bream_smelt, target_bream_smelt)
print(lr.predict(train_bream_smelt[:5]))
#['Bream' 'Smelt' 'Bream' 'Bream' 'Bream']
print(lr.predict_proba(train_bream_smelt[:5]))
#[[0.99759855 0.00240145]
[0.02735183 0.97264817]
[0.99486072 0.00513928]
[0.98584202 0.01415798]
[0.99767269 0.00232731]]
print(lr.classes_)
#['Bream' 'Smelt']
print(lr.coef_, lr.intercept_)
#[[-0.4037798 -0.57620209 -0.66280298 -1.01290277 -0.73168947]] [-2.16155132]
decisions = lr.decision_function(train_bream_smelt[:5])
print(decisions)
# z값 결과 : [-6.02927744 3.57123907 -5.26568906 -4.24321775 -6.0607117 ]
# decision_function()은 양성 클래스의 z값을 반환
from scipy.special import expit
print(expit(decisions))
#expit()은 시그모이드 함수를 구해줌
[0.00240145 0.97264817 0.00513928 0.01415798 0.00232731]3) 로지스틱 회귀로 다중 분류 수행하기
lr = LogisticRegression(C=20, max_iter=1000)
lr.fit(train_scaled, train_target)
print(lr.score(train_scaled, train_target))
print(lr.score(test_scaled, test_target))
print(lr.predict(test_scaled[:5]))
#로지스틱 회귀로 다중분류 예측결과
#['Perch' 'Smelt' 'Pike' 'Roach' 'Perch']
---
#검증 - 로지스틱 회귀 분류모델의 확률 구해보기
#z값
decision = lr.decision_function(test_scaled[:5])
print(np.round(decision, decimals=2))
#[[ -6.5 1.03 5.16 -2.73 3.34 0.33 -0.63]
[-10.86 1.93 4.77 -2.4 2.98 7.84 -4.26]
[ -4.34 -6.23 3.17 6.49 2.36 2.42 -3.87]
[ -0.68 0.45 2.65 -1.19 3.26 -5.75 1.26]
[ -6.4 -1.99 5.82 -0.11 3.5 -0.11 -0.71]]
#소프트맥스로 지수함수 계산
from scipy.special import softmax
proba = softmax(decision, axis=1)
print(np.round(proba, decimals=3))
#[[0. 0.014 0.841 0. 0.136 0.007 0.003]
[0. 0.003 0.044 0. 0.007 0.946 0. ]
[0. 0. 0.034 0.935 0.015 0.016 0. ]
[0.011 0.034 0.306 0.007 0.567 0. 0.076]
[0. 0. 0.904 0.002 0.089 0.002 0.001]]
LogisticRegression : 선형 분류 알고리즘인 로지스틱 회귀를 위한 클래스
***매개변수
1)solver = 사용알고리즘 선택, 기본값 'lbfgs'
'sag'('saga'가 최신 버전)은 확률적 평균 경사 하강법 알고리즘. 특성과 샘플 수가 많을 때.
2)max_iter = 반복횟수 지정, 기본값 100
3)C = 규제횟수, 기본값 1.0, 클수록 규제 완화(릿지의 알파와 반대)
4)penalty = 규제방식, 기본값 'l2'
L1 규제 : 라쏘 방식 (alpha=0.0001)
L2 규제 : 릿지 방식
predict_proba() : 예측 확률을 반환하는 메서드
이진분류 : 샘플마다 음성/양성 클래스 확률값
다중분류 : 샘플마다 모든 클래스에 대한 확률값
decision_function() : 모델이 학습한 선형 방정식의 출력을 반환
이진분류 : 함수값이 0보다 크면 양성, 나머지 음성. (=z값이 0.5 이상이면 양성)
다중분류 : 가장 큰 값의 클래스가 예측 클래스.
* 로지스틱 회귀 분류모델 훈련법
선형 방정식 사용, 출력값 0~1 사이로 압축(확률값으로 사용가능)
1) 이진분류 > 하나의 선형 방정식을 훈련 > 시그모이드 함수
(양성 클래스에 대한 0~1값 출력)
2) 다중분류 > 클래스 개수만큼 방정식을 훈련 > 소프트맥스 함수
(전체 클래스에 대한 합이 항상 1이 되도록 각각의 0~1값 출력 = 정규화)
✅04-2 : 확률적 경사 하강법
*점진적인 학습 : 앞서 훈련한 모델을 유지하되, 새로운 데이터에 대해서만 조금씩 더 훈련.
1)확률적 경사 하강법 Stochastic Gradient Descent, SGD
: 훈련 세트에서 랜덤하게 하나의 샘플을 선택, 가파른 경사를 조금 내려감 >> 이를 반복. (전체 샘플을 다 쓸 때까지 = 1 에포크 epoch)
2)미니배치 경사 하강법 Minibatch Gradient Descent, MGD
: 여러 개의 샘플을 사용하여 경사 하강법
3)배치 경사 하강법 Batch Gradient Descent, BGD
: 전체 샘플 사용하여 한번에 경사 하강법. 그러나 컴퓨터 자원을 많이 사용하게 됨
*손실 함수 Loss Function (t-y)^2 오차제곱
: 얼마나 오차가 큰지 측정하는 기준. 미분이 가능해야 함.
- 이진분류 - 로지스틱 손실 함수
(=이진 크로스엔트로피 손실함수)
: 분류일 때 사용. 정확도로 모델의 '성능 평가'. 로지스틱손실함수로 '최적화 평가'. 2가지 해야함.
(회귀에서는 평균 절댓값 오차, 평균 제곱 오차를 많이 사용, 손실함수=측정지표)
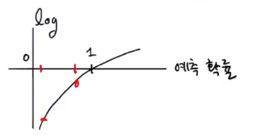
ex)
예측 0.9, 정답(타깃) 1 일때 : 예측이 정답에 근접함. = 낮은 손실.
-> -(예측*정답) 음수 값으로 손실 함수 나타내기.
예측 0.2, 정답(타깃) 0 일때 : 정답이 음성 클래스라 0인 경우
-> 예측값과 타깃을 각각 양성 클래스처럼 바꾼다.
양성예측값 = 1 - 음성예측값
타깃 = 1
***
타깃=1일 때, -log(예측확률)
타깃=0일 때, -log(1-예측확률)- 다중분류 - 크로스엔트로피 손실함수
SGDClassifier : 확률적 경사 하강법을 사용한 '분류 모델' 만듦.
(SGDRegressor : 확률적 경사 하강법을 사용한 '회귀 모델' 만듦.)
from sklearn.linear_model import SGDClassifier
#loss는 손실함수 종류(기본값='hinge')
#다중분류 + 로지스틱손실함수 경우 클래스마다 이진분류모델 만듦. OvR(One versus Rest)
sc = SGDClassifier(loss='log', max_iter=10, random_state=42)
sc.fit(train_scaled, train_target)
print(sc.score(train_scaled, train_target))
print(sc.score(test_scaled, test_target))
#모델 추가 훈련 .partial_fit() 를 이용하면, 기존에 학습한 w와 b를 그대로 유지하며 훈련만 추가로.
sc.partial_fit(train_scaled, train_target)
print(sc.score(train_scaled, train_target))
print(sc.score(test_scaled, test_target))*에포크 Epoch
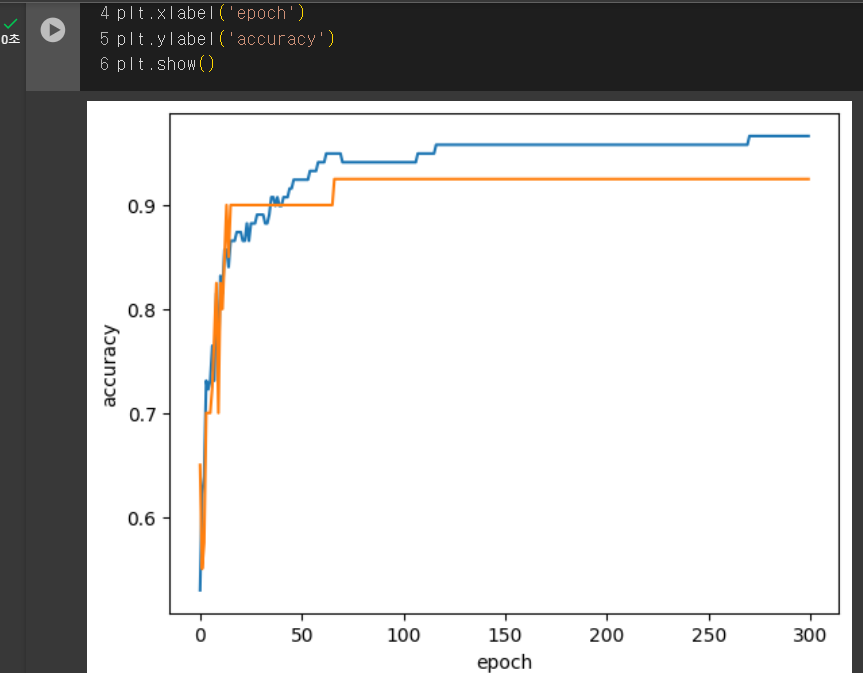
적으면 과소적합, 많으면 과대적합.
과대적합 시작 전 훈련 멈추는 것을 조기 종료 early stopping 이라고 함.
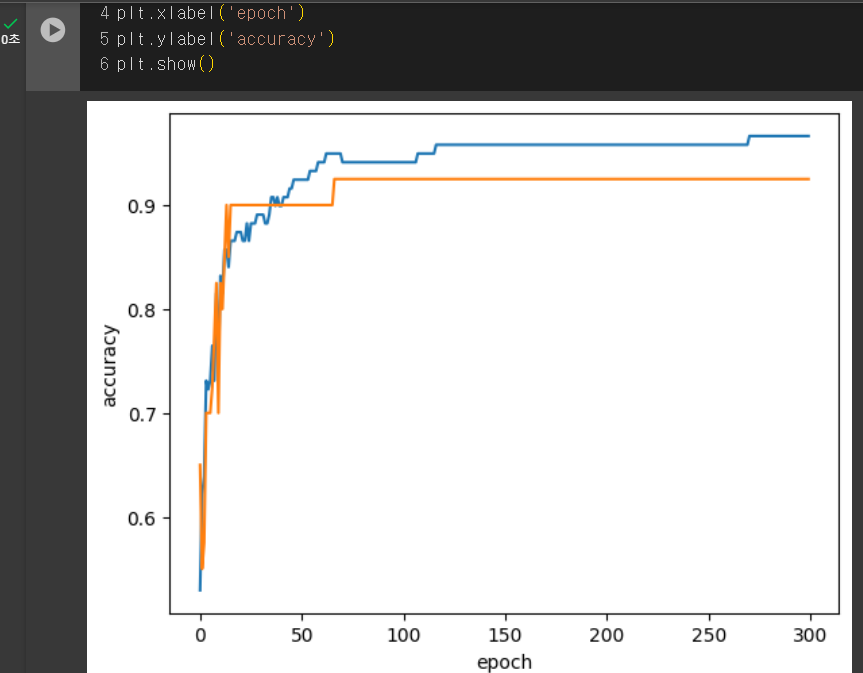
ex) 해당 모델의 경우 100번째 에포크가 가장 적절한 반복 횟수.
-> 적절한 에포크 횟수를 알았으니 max_iter 매개변수에 넣어 돌려보기.
-> tol=None 으로 지정. 일정 에포크 동안 성능이 향상되지 않아도 계속 반복.
n_iter_no_change=5 : 기본값인 5에포크 동안 손실이 tol만큼 줄어들지 않으면(=성능이 향상되지 않으면) 알고리즘 중단.
tol=0.001 : 지정 에포크 동안 기본값인 0.001만큼 손실이 줄어들면 알고리즘 계속 돌아감.
