✅혼자 공부하는 머신러닝+딥러닝
진도: Chapter 01 ~ 02
keyword : 지도학습 알고리즘 > 분류 > 이진 분류 binary classification > k-최근접 이웃 분류
(multi-class classification은 4장에서 실습!)
사용 sklearn 패키지 : neighbors, model_selection
실습파일 : BreamAndSmelt.ipynb, BreamAndSmelt-2.ipynb

(완료) 기본 미션 : 코랩 실습 화면 캡처하기
(완료) 선택 미션 : Ch.02(02-1) 확인 문제 풀고, 풀이 과정 정리하기
#Q1 풀이과정.
머신러닝 알고리즘의 종류로서, 학습 시키려면 샘플의 입력(데이터)과 타깃(정답)으로 이루어진 훈련데이터가 필요한 것은 '지도학습' 이다.
*비지도 학습은 정답값(타깃)이 없는 데이터에 적용한다.
#Q2 풀이과정.
훈련 세트와 테스트 세트가 골고루 섞이지 못하여 전체 데이터를 대표하지 못하게 된 현상은 '샘플링 편향' 이다.
#Q3 풀이과정.
사이킷런에서 입력 데이터(배열)은 행: 샘플, 열: 특성으로 구성되어 있다.
각각 특성 값 담긴 리스트가 하나의 샘플값이다.
각 샘플 리스트들이 하나의 리스트로 담겨있는 2차원 리스트 구조이다.컴퓨터 과학은 추상화의 학문이다.
인공지능의 추상화를 걷어내고 알고리즘을 풀어내자.
✅Chapter 01 머신러닝
01-3 마켓과 머신러닝) fish-market dataset을 이용해 실습한다.
Data출처 : https://www.kaggle.com/datasets/vipullrathod/fish-market
-Classification 분류 : class를 구별해내는 것.
ex) binary (이진분류), 다항분류
-Scatter plot 산점도 : x,y 축 좌표계에 두 변수(x,y)의 관계를 표현하는 방법
-
K-최근접 이웃 알고리즘을 이용한 머신러닝 프로그램 제작
K-Nearest Neighbors : 주위의 다른 데이터를 보고 다수를 차지하는 것을 정답으로 사용
=> from sklearn.neighbors import KNeighborsClassifier**KNeighborsClassifier() 클래스** _fit_X 속성 : 모든 x값을 저장한다. _y 속성 : 모든 target 값을 저장한다. (둘 다 ','로 구분 없이 값만 저장되어있다.) p 매개변수 : 1 - 맨해튼 거리, 2 - 유클리디안 거리 (기본 distance) n_jobs 매개변수 : 사용할 CPU 코어 지정 가능 (-1 은 모든 CPU코어 사용하여, 이웃 간의 거리 계산 속도를 높일 수 있다. 기본값은 1이다.)
근처에 있는 몇 개의 데이터를 참고할 것인가?
기본값은 5이며, 아래와 같이 매개변수 변경하여 지정 가능.
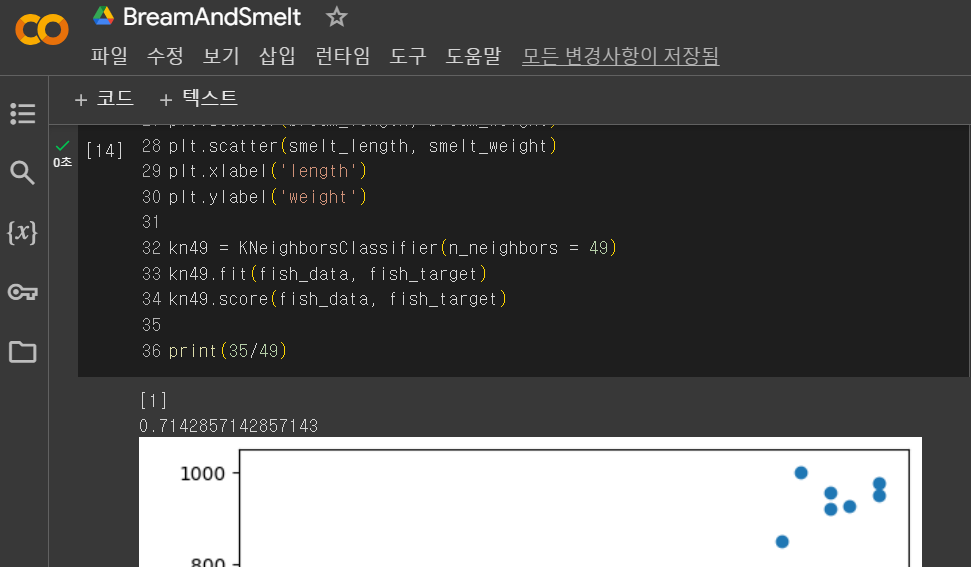
kn49 = KNeighborsClassifier(n_neighbors = 49)kn49.fit(x_data, t_data) kn49.score(x_data, t_data)=> 그러나 이렇게 많은 양의 매개변수는 좋지 않다.
현재의 x_data는 총 49개로, 그 중 대다수가 '도미' 값이다.
이 kn49 모델은, 근처 49개 값을 참조하여 다수 값을 정답으로 도출한다.
어떤 데이터를 넣더라도 x_data 중 이미 다수를 차지하는 '도미' 값으로 예측할 것이다.=> 따라서 적절한 수의 매개변수를 설정하는 것이 중요하다.
이미 기본 값으로도 accuracy = 1.0 (100%정답) 이 나왔으니 기존 kn모델을 사용하자.
추가적으로, for n in range(5, 데이터값) 구문을 사용하여 accuracy 가 1 이하로 떨어지는 매개변수 값을 구할 수도 있다.
-
모델생성 -> 모델학습(fit) -> 결과예측(predict) & 모델평가(score)
Scikit-learn 패키지는 2차원 리스트가 필요
=> zip() , list comprehension 내포구문 이용linear & binary classification 이라서 쉽게 x_data와 t_data를 구현 가능.
- Training : 객체.fit(x_data, t_data)
- Predict : 객체.predict([[ , ]]) / sklearn이라 값이 2차원리스트 데이터.
- 모델 평가 : 객체.score(x_data, t_data)
-> accuracy 출력 (맞힌 개수/전체 데이터 개수) : 사이킷런에서는 0~1사이의 값
✅Chapter 02-1 훈련 세트와 테스트 세트
Supervised Learning 지도학습
: Training Data (Input(2차원 features) + Target) 필요
훈련 세트와 테스트 세트
훈련 : 훈련 세트 (Train set)
평가 : 테스트 세트 (Test set) - 전체 데이터에서 20~30% 내외
Train_input / Train_target / Test_input / Test_target
# 모델 만들기 (훈련)
kn.fit(train_input, train_target)
# 모델 평가하기 (테스트)
kn.score(test_input, test_target)Slicing 연산자
콜론':'을 가운데 두고 인덱스의 범위를 지정하여 여러 개의 원소를 선택할 수 있다. [시작 : 끝]
마지막 인덱스의 원소는 포함되지 않는다.
[0 : 5] => 0,1,2,3,4
Numpy
파이썬의 대표 array 배열 라이브러리. 고차원 배열 조작 시 유리
1,2,3차원 배열은 각각 선,면,3차원 공간
# 파이썬 리스트 -> 넘파이 배열 변환
arr = np.array(list)
# (샘플 수, 특성 수) 출력
np.shape
# 배열 인덱싱 - 여러 개의 인덱스를 지정, 여러 개의 원소를 한 번에 선택
print(arr[[1,3]])
> 2, 4번째 샘플 출력
[ [2번째 샘플]
[4번째 샘플] ]
Sampling Bias 샘플링 편향
sample이 골고루 섞이지 않은 것을 말함.
데이터 세트를 나누려면 sample이 골고루 섞이게 만들어야 함.
np.random.seed(42)
넘파이에서 난수를 생성할 seed를 지정해 주는 코드.
머신러닝 모델을 짜기 전에 항상 보이는데, 이걸 왜 쓰냐면?
난수를 생성 하게 될때 사실 진짜 현실세계의 랜덤이 아니라
seed에 따라 어떤 시퀀스가 있다고 한다. (pseudo random)
이러한 유사랜덤의 특성 때문에
같은 seed를 지정해 주면 같은 시퀀스 난수를 생성한다.
이 성질이 모델을 평가하고, 다른사람과 코드를 공유하고 테스트 할 때,
반복적으로 모델을 구동하여도 초기 가중치 같은 값들이 같은 시퀀스로 난수가 지정되니까,
평가 및 테스트에서 일관된 결과를 얻을 수 있게 해준다.
# random.seed() : 무작위 결과를 만드는 함수
np.random.seed(42)
# arange(정수N) : 0부터 N-1까지 1씩 증가하는 배열을 만든다
# 주요 인자 : np.arange(시작점(생략 시 0), 끝점(미포함), step size(생략 시 1))
index = np.arange(49)
# random.shuffle() : 주어진 배열을 무작위로 섞는 함수
np.random.shuffle(index)
> 결과 : 0~48이 랜덤으로 섞여있다.✅훈련 모델 평가해보기 by Python
1) [데이터 정제] 2차원 리스트로 데이터를 정제 : input/target
-> 각 리스트에 담겨 있는 length 데이터, weight 데이터를 순회하며 값을 하나씩 뽑아오고, 다시 하나의 리스트로 담은 2차원 리스트 생성
->각 특성들을 담은 리스트 값이 하나의 샘플이 된다. scatter에서 각 특성들은 xlabel / ylabel 값이 된다.
2) [데이터 정제] numpy 배열로 데이터를 정제 : input_arr/target_arr
-> np.array()로 상기 2차원 리스트 데이터를 넣어서 넘파이 배열(array)를 생성한다.
3) [데이터 정제] 샘플링 편향 방지 위해, 랜덤 인덱스 생성
랜덤난수 지정, arange로 순차 인덱스 생성, 랜덤셔플 돌리기
4) [데이터 정제] dataset을 train/test 용으로 각각 8:2 비율로 분리한다.
-> train(input, target) & test(input, target) 총 네가지의 변수를 만들어야 한다.
-> 랜덤 인덱스 배정하기. 슬라이싱으로 비율 분리
*) [시각화] matplotlib & scatter로 각 데이터가 비율에 맞게 정제가 완료 되었는지 체크!!
-> plt.scatter(행,열)
행 : [: , 0] -> 1번째 column(인덱스 0)을 x값으로
열 : [: , 1] -> 2번째 column(인덱스 1)을 y값으로
/ train&test 분리할 때 순서 지정되었으므로 슬라이싱 범위는 [:] 전체범위
5) [알고리즘] 사용할 알고리즘 선택, import
-> 지도학습 중, K-Nearest Neighbors 알고리즘을 이용한 머신러닝 프로그램 제작
K-Nearest Neighbors : 주위의 다른 데이터를 보고 다수를 차지하는 것을 정답으로 사용
from sklearn.neighbors import KNeighborsClassifier
6) [알고리즘] *train data 학습 kn.fit(train_input, train_target)
7) [알고리즘] test data 평가 kn.score(test_input, test_target) -> accuracy 출력
8) [알고리즘] test data 예측 kn.predict(test_input) / print(test_target)
test세트의 예측 결과 / 실제 타깃 -> 각각 출력 값 비교
✅Chapter 02-2 데이터 전처리
넘파이) 데이터 준비하기
np.column_stack() : 전달받은 리스트를 일렬로 세운 다음 차례대로 나란히 연결
np.column_stack(([1,2,3],[4,5,6]))
>array([[1, 4],
[2, 5],
[3, 6]])np.ones() / np.zeros() : 0, 1의 배열 만들기
np.zeros(5)
>array([0., 0., 0., 0., 0.])❤️사이킷런❤️) 훈련세트, 테스트세트 준비하기
from sklearn.model_selection import train_test_split
: 전달되는 리스트나 배열을 비율에 맞게 훈련 세트와 테스트 세트로 나누어 줌.
+섞어줌!!! (shuffle=True 기본값)
나누고 싶은 리스트나 배열을 원하는 만큼 전달
기본비율 75% : 25% (테스트)
- 비율 바꾸는 매개변수
'stratify = 타깃데이터'
-> 클래스 레이블이 담긴 배열을 전달하면, 클래스 비율에 맞게 데이터를 나눈다.
'test_size = 0.n'
-> n : 나머지 비율로 데이터를 나눈다. ex) test_size=0.3 이라면, 7:3 비율
train_input, test_input, train_target, test_target = train_test_split(fish_data, fish_target, stratify=fish_target, random_state=42)
print(train_input.shape, test_input.shape)
>(36, 2) (13, 2) #2차원 배열 - 36개,2열 & 13개,2열
print(train_target.shape, test_target.shape)
>(36,) (13,) #1차원 배열 - 36개 & 13개 / 튜플에 원소가 하나면 뒤에 콤마를 추가한다.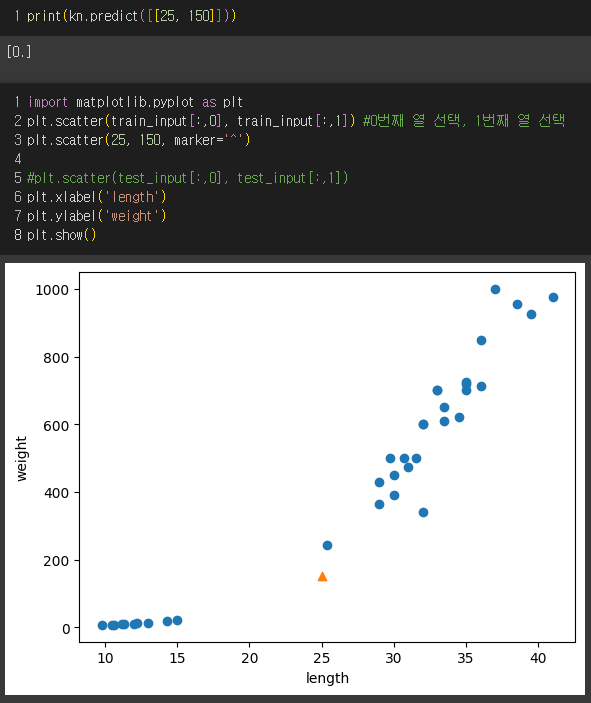
1로 예측했지만, 결과는 0이 출력되었다.
예측 결과가 다르게 출력되는 이유는, 실제로 0과 더 근접하기 때문이다.
가시적으로는 1값에 가깝지만, 실제 거리는 0과의 거리가 가깝다.
이유는, x축과 y축의 스케일이 다르기 때문이다.
🛎스케일이 다른 특성 처리하기🛎
KNeighborsClassifier(n_neighbors의 기본값은 5) 클래스의 이웃을 출력하고,
이웃값의 변화를 시각화로 비교하며 올바른 모델인지 평가할 수 있다.
- distances, indexes = kn.kneighbors([[이웃을 지정할 샘플값]])
최근접 이웃을 찾아, 거리 & 이웃 샘플의 인덱스를 반환한다. distances, indexes = kn.kneighbors([[25, 150]])
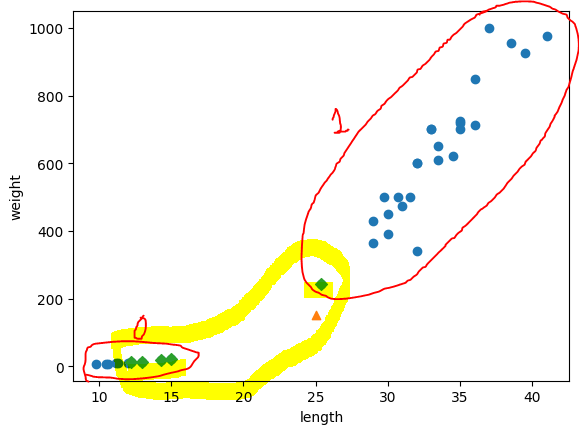
- 이웃을 표기한 결과
0인 이웃이 넷, 1인 이웃이 하나
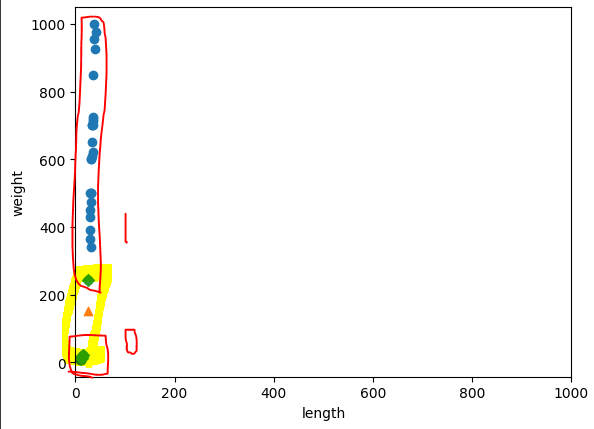
- x축과 y축의 스케일 맞추기
xlim((시작값,끝값)) : x축의 범위를 조정한다.
ylim((시작값,끝값)) : y축의 범위를 조정한다.
=> 해당 그림을 보니, x축(length)의 영향력이 너무 적다. y축(weight)만 고려대상이 된다.
이렇게 두 특성의 값이 놓인 범위가 다른 것을 스케일이 다르다 라고 표현한다.
=> 알고리즘이 거리 기반이면, 샘플 간 거리에 영향을 많이 받으므로 특성값을 일정 기준으로 맞춰줘야 한다. (data preprocessing)
- [데이터 전처리] 표준점수 standard score(=z 점수)
: 각 특성값이 평균에서 표준편차의 몇 배만큼 떨어져 있는지를 나타냄
실제 특성값의 크기와 상관없이, 동일한 조건으로 비교 가능.
분산 : 편차제곱을 평균으로 나눈다.
#공식 : (데이터 - 평균)^2 / 평균표준점수 : 각 데이터가 원점에서 몇 표준편차만큼 떨어져 있는지를 나타내는 값.
편차제곱을 표준편차로 나눈다.
#공식 : (데이터 - 평균) / 표준편차
#python : (train_input - mean) / std표준편차 standard deviation : 분산의 양의 제곱근.
데이터가 평균을 중심으로 분산된 정도를 나타낸다.
#함수 : np.std()#특성마다 값의 스케일이 다르므로, 특성별로 계산해야 함. #행을 따라 각 열의 통계값을 계산하도록 axis=0 으로 지정. [평균, 표준편차 공식] mean = np.mean(train_input, axis=0) std = np.std(train_input, axis=0) ->[ 28.29428571 483.35714286] ->[ 9.54606704 323.47456715] -- [표준편차 메서드 차이] numpy array 의 std() 는 자유도의 디폴트값이 0인 모표준편차를 계산 pandas의 DataFrame.std() 는 자유도 1인 표본표준편차를 계산 ->두 메소드 모두 ddof= 파라미터가 있으니 그것을 필요에 따라 맞춰서 적용하면 됩니다. ex) np.std(df['f1'], ddof=1) df['f1'].std(ddof=0)
✅훈련 모델 평가해보기 by sklearn
sklearn에 내장된 module을 활용하여 훨씬 간소해진 모습을 볼 수 있다.
1) [데이터 정제] numpy 배열로 데이터를 정제 : input_arr/target_arr
-> input_arr = np.column_stack((data_list_1, data_list_2))
-> target_arr = np.concatenate((np.ones(35),np.zeros(14)))
2) [데이터 정제] sklearn model import, 훈련세트/테스트세트 나누기
: train_input, test_input, train_target, test_target
자동 모델 사용!😆😆😆 랜덤으로 타겟값 섞어주기까지 함!
비율은 매개변수로 지정 가능!
from sklearn.model_selection import train_test_split
train_input, test_input, train_target, test_target = train_test_split(fish_data, fish_target, stratify=fish_target, random_state=42)3) [데이터 정제] Scale 조정하기
mean = np.mean(train_input, axis=0)
std = np.std(train_input, axis=0)
#브로드캐스팅 broadcasting
train_scaled = (train_input - mean) / std
test_scaled = (test_input - mean) / std4) [알고리즘] 사용할 알고리즘 선택, import
-> 지도학습 중, K-Nearest Neighbors 알고리즘을 이용한 머신러닝 프로그램 제작
*) [시각화] matplotlib & scatter로 각 데이터가 비율에 맞게 정제가 완료 되었는지 체크!!
/ 거리 기반 알고리즘이므로 스케일 조정이 제대로 되었는지 체크!!!!! : train_scaled, test_scaled
-> plt.scatter(행,열)
행 : [: , 0] -> 1번째 column(인덱스 0)을 x값으로
열 : [: , 1] -> 2번째 column(인덱스 1)을 y값으로
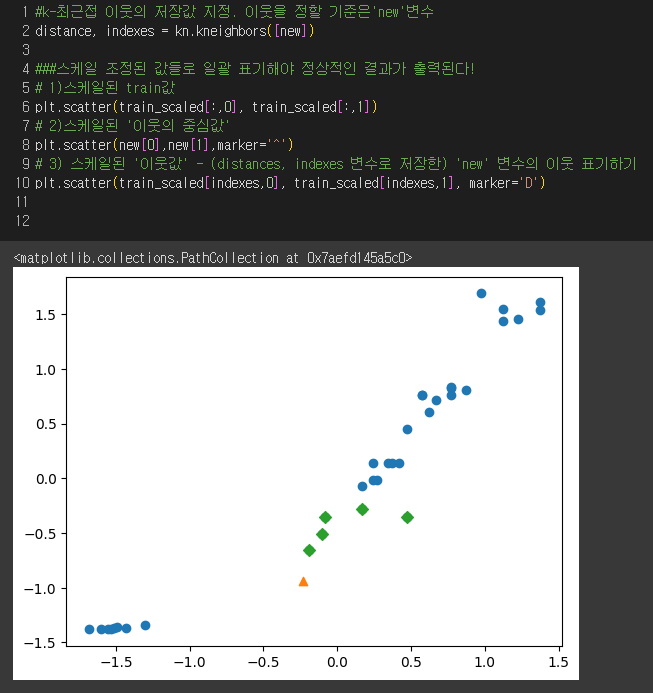
-> 시각화로 n_neighbors 값이 잘 조정된 것 확인 :)
KNeighborsClassifier(n_neighbors = 5)
5) [알고리즘] *train data 학습 kn.fit(train_trained, train_target)
6) [알고리즘] test data 평가 kn.score(test_trained, test_target) -> accuracy 출력
7) [알고리즘] test data 예측 kn.predict(test_trained) / print(test_target)
test세트의 예측 결과 / 실제 타깃 -> 각각 출력 값 비교
+) 샘플 값으로 예측해보기
kn.predict([new]) / print(new)
new = ([25,150]-mean)/std
#표준점수 : [-0.23012627 -0.94060693]
