1. Abstract

이 논문에서의 colorization의 목표는 Ground Truth와 같은 색을 에측하는 것보다는 '그럴듯한' 색으로 예측하는 것이다. 이 문제를 해결하기 위해서 Colorization문제를 분류 문제로 제기함으로써 불확실성을 수용하고 색상 다양성을 높였다.
2. Background
CIE Lab
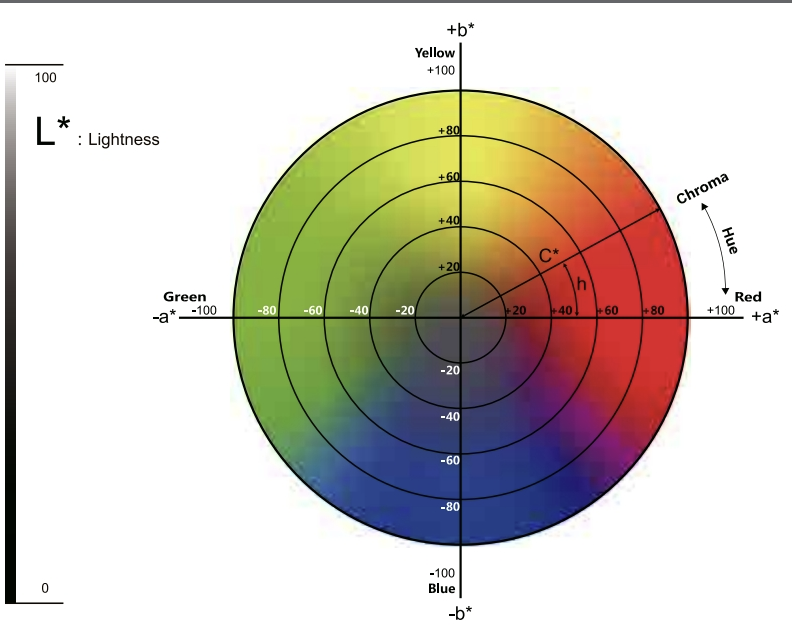
CIE Lab Color Space에서 L은 밝기를 나타낸다. 0~100 사이이며 값이 커질수록 검은색, 작아질수록 흰색에 가까워진다. a는 빨강과 초록 중 어느 쪽으로 치우쳤는지를 나타낸다. 값이 음수이면 초록에 가까운, 양수이면 보라/빨강에 가까운 색이다. b는 노랑과 파랑을 나타내며, 음수이면 파랑이고, 양수이면 노랑입니다.
이전 연구
Non-Parametric method
Input되는 grayscale image가 주어지면 먼저 소스 데이터로 사용할 하나 이상의 color image를 정의한다. 그러고는 특정 프레임워크에 따라 참조 이미지의 유사 영역에서 입력 이미지로 색상을 전송한다.
Parametric method
학습할 때 많은 양의 Color Image 데이터 셋으로부터 예측함수를 학습하여 문제를 연속적인 색 공간에 대한 regression문제 혹은 정량화된 색의 값에 대한 분류로 간주하였다.
문제점
이전의 연구에서 색을 예측하기 위해 CNN에서 학습하였다. 그러나 사실 색을 예측한다는 것은 Multimodal한 문제라고 할 수 있다. 예를 들어, 사과 라는 같은 물체도 초록색 일수도, 빨간색일수도 있기 때문이다.
따라서 이런 multimodal을 적절히 modeling하기 위해 각 픽셀의 가능한 색의 분포를 예측합니다. 또한 흔하지 않은 색들을 더 잘 표현하기 위해 학습할 때, loss를 re-weight합니다. 이를 통해 많은 양의 데이터에서 다양성을 이용할 수 있게 해주었고, 마지막으로 annealed-mean을 이용해 최종 colorization을 생성함으로써 더 '그럴듯한' color image를 만듭니다.
3. Architecture
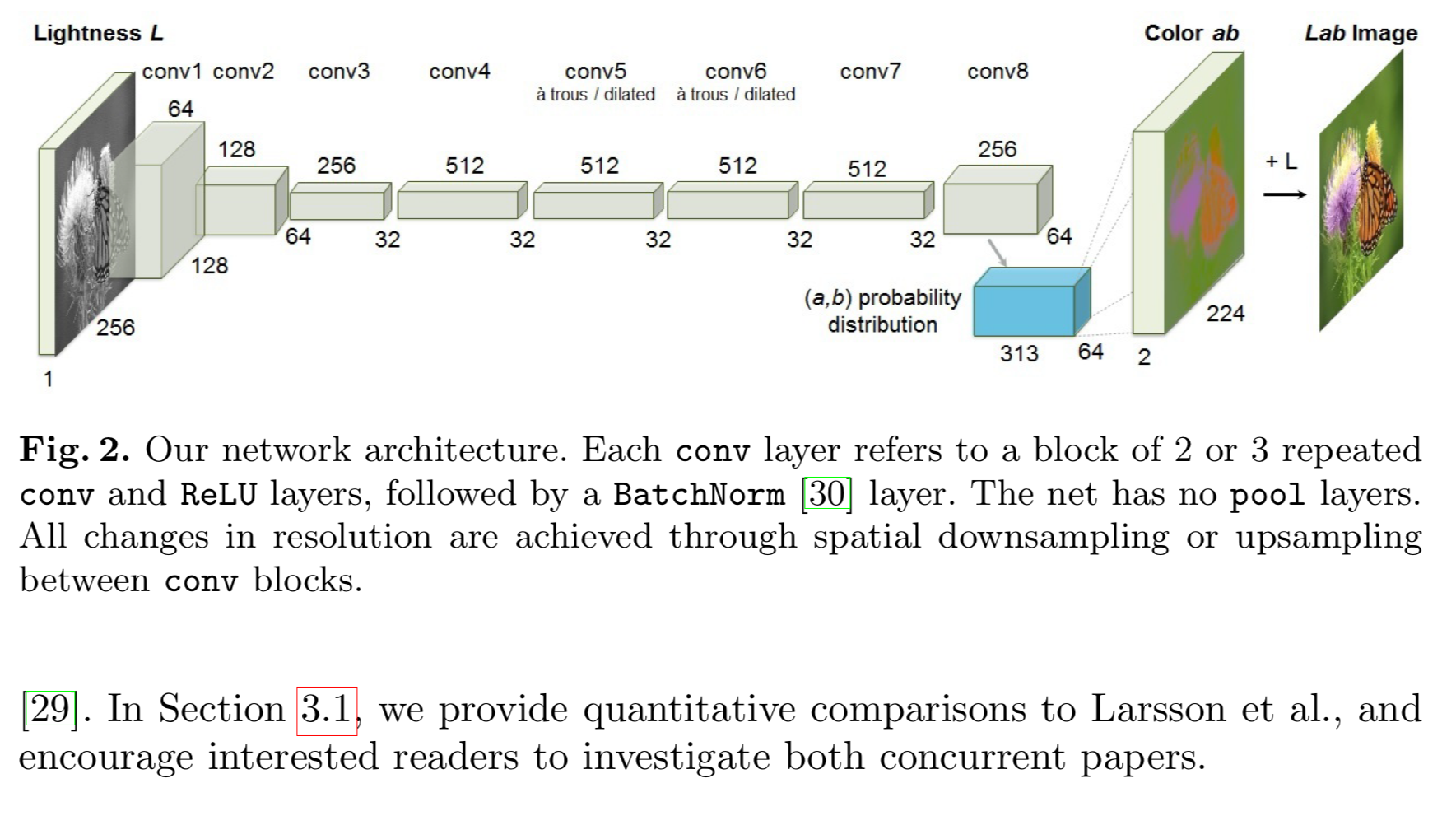
Grayscale Image에서 정량화된 색상 값(CIE Lab의 a,b) 출력에 대한 분포를 매핑하도록 CNN을 훈련한다
pooling이 없는 형태이며 resolution을 downsampling, upsampling하는 모든 경우에 conv연산으로 수행하였다. conv Relu batchnorm의 형태로 layer가 반복되는 블록으로 되어 있으며 conv8에서는 a,b의 색상을 예측한다. a,b를 예측하고 처음 input된 grayscale image의 L채널을 가져와서 더하여 최종 이미지를 만들어낸다.
4. Objective function
함수 형태

입력 밝기 채널이 X ∈ RH×W×1일 때, 목표는 두 개의 연결된 색상 채널 Y ∈ RH×W×2에 대한 Y^=F(X)를 학습하는 것이다. 그리고 이 때의 Loss function은 (1)과 같다.
그러나 (1)식은 colorization 문제의 모호성과 multimodal이라는 특성에 적합하지 않다. 위 loss function을 사용할 경우 이미지 전체적으로 회색빛이 돌거나 채도가 낮은 desaturated한 이미지를 결과로 나타낸다.
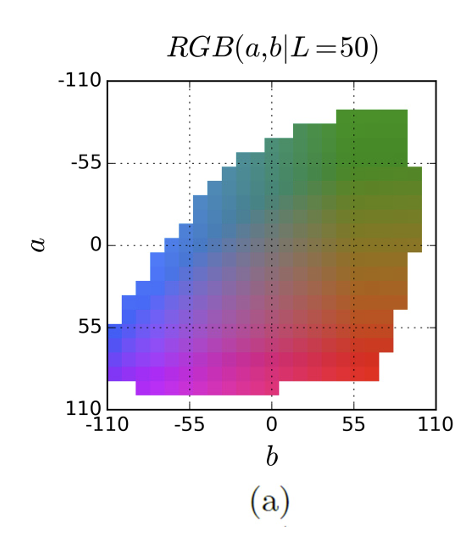
따라서 위 그림과 같이 출력 공간을 그리드 크기 10으로 정량화하고 Q=313개의 값으로 만들어 multimodal classification 문제로 다루도록 한다. 또한 정답값 Y도 벡터 Z로 변경한다.
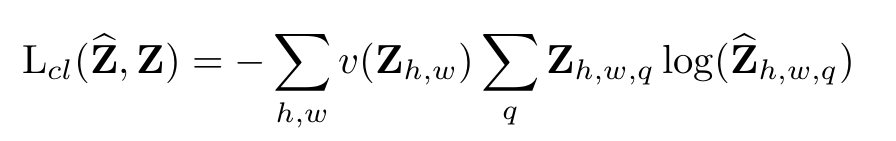
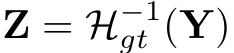
따라서 Loss function을 위와 같이 수정하고 Ground Truth도 예측값과 비교하려면 비슷한 형태가 되어야 하므로 같은 분포를 띄는 벡터르 바꿔준다.
loss function에서 v()는 색의 rare함에 따른 weighting term으로 rare한 색의 class를 rebalance할 수 있다.
Class Rebalancing
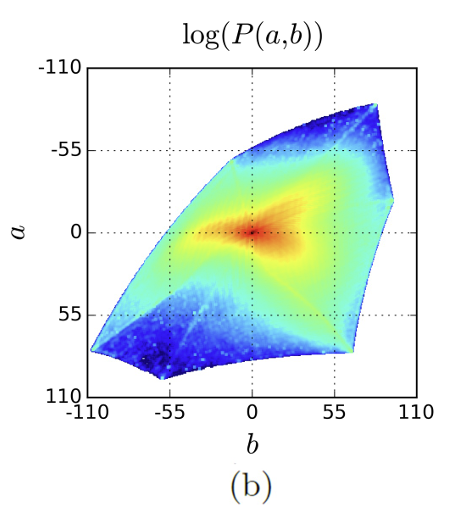
natural한 이미지의 ab값 분포는 구름, 흙, 벽과 같은 배경으로 인해 낮은 ab값을 가지도록 크게 편향되어 있다.
위 그림은 ImageNet의 Training image에서 수집한 픽셀의 ab분포를 나타낸다. 낮은 ab값을 가지는 픽셀의 분포가 많기 때문에 이를 고려하지 않으면 Loss function은 desaturated ab 값에 너무 큰 영향을 끼치게 되어 그럴듯한 색상 이미지를 만들지 못한다.
이러한 색의 불균형 문제를 해결하기 위해 학습 시에 각 픽셀이 가지는 색의 rarity를 기반으로 loss를 reweighting하는 방법을 사용한다. 각 픽셀은 가장 가까운 픽셀의 ab의 weight를 기반으로 reweight한다.
Class Probabilities to Point Estimates
예측한 분포벡터 Z^을 ab공간에 있는 한 점인 Y^으로 mapping하는 함수인 H를 구하는 방법은 2가지가 있다. 각 픽셀에 대한 예측된 분포의 mode를 취하는 방법과 mean을 취하는 방법이다.
mode를 취하는 방법은 선명하지만 중간중간에 상관없는 색이 채워질 수 있는 반면, mean을 취하는 방법은 상관없는 색이 채워지진 않지만, desaturated한 결과가 생긴다.
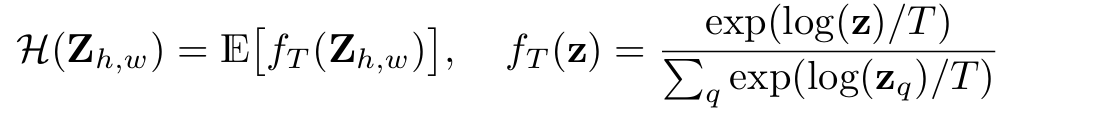
따라서 두 방법을 종합하기 위해 softmax분포의 T를 조정하고 결과의 평균을 구해 interpolate한다.

T를 1로 설정하면 분포가 변하지 않고 Mean에서의 분포가 나오고, T를 낮출수록 더 강한(desaturated하지 않은)분포가 형성된다. 그리고 T가 0이면 Mode에서의 분포가 된다. 위 그림에서는 T=0.38일때 가장 최적의 분포가 나왔다고 한다.
5. Experiment

Ground Truth와는 조금 다르지만 꽤나 그럴듯한 색상의 이미지가 나온 것을 볼 수 있고, 이 논문의 목표인 '그럴듯한 이미지'를 잘 나타냈다는 것을 볼 수 있다.
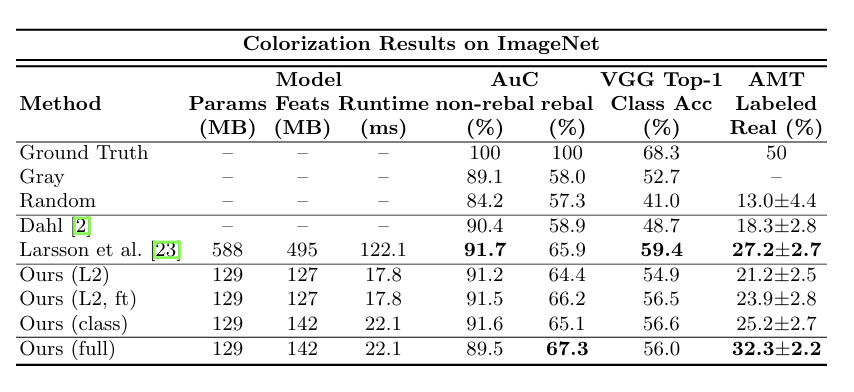
평가 방법은 앞서 말했다시피 그럴듯한 이미지를 만드는 것이 목적이기에 사람에게 직접 평가를 하게 하는 AMT방법이 조금 더 적절하고 정확한 평가라고 할 수 있다. 따라서 AMT를 기준으로 보았을 때 위 논문에 대한 성능이 제일 좋게 나오는 것을 볼 수 있다.
6. Conclusion
Image Colorization은 생각보다 어려운 task이지만, 이 논문에서는 이전보다 깊은 CNN과 적절한 Objective function을 사용한 Colorization으로 실제 컬러 사진과도 구별하기 어려운 결과를 생성하는 데 더 가까워졌다.
위 논문의 방법은 Colorization task도 좋은 성능으로 수행하였지만 기존에 있던 Object Detection, Segmentation과 같은 다른 task에서도 더 좋은 성능을 나타내었다. 이는 기존의 방법보다 위 논문의 방법이 더 특징을 잘 잡아낸다는 것을 알 수 있다.
