📌 연구 배경
대규모 언어 모델(LLM)은 자연어 처리(NLP) 분야에서 혁신적인 성과를 보여주고 있지만, 환각(hallucination) 문제로 인해 신뢰할 수 없는 결과를 생성하는 경우가 많습니다. 이러한 문제는 특히 의료나 법률과 같은 고위험 분야에서 큰 장애 요인이 됩니다. 기존 연구들은 외부 지식을 활용하거나 추가 학습을 통해 이 문제를 해결하려 했지만, 본 연구에서는 새로운 접근 방식을 제안하고 있습니다.
🎯 연구 목표
LLM에서 환각 문제를 줄이고 사실 기반(factual) 정보를 더욱 효과적으로 생성할 수 있는 새로운 디코딩 전략인 DOLA(Decoding by Contrasting Layers)를 제안하였습니다. 이 방법은:
- 외부 지식 없이,
- 추가 파인튜닝 없이,
- 모델 내부의 계층 구조를 활용하여 사실성을 향상시킵니다.
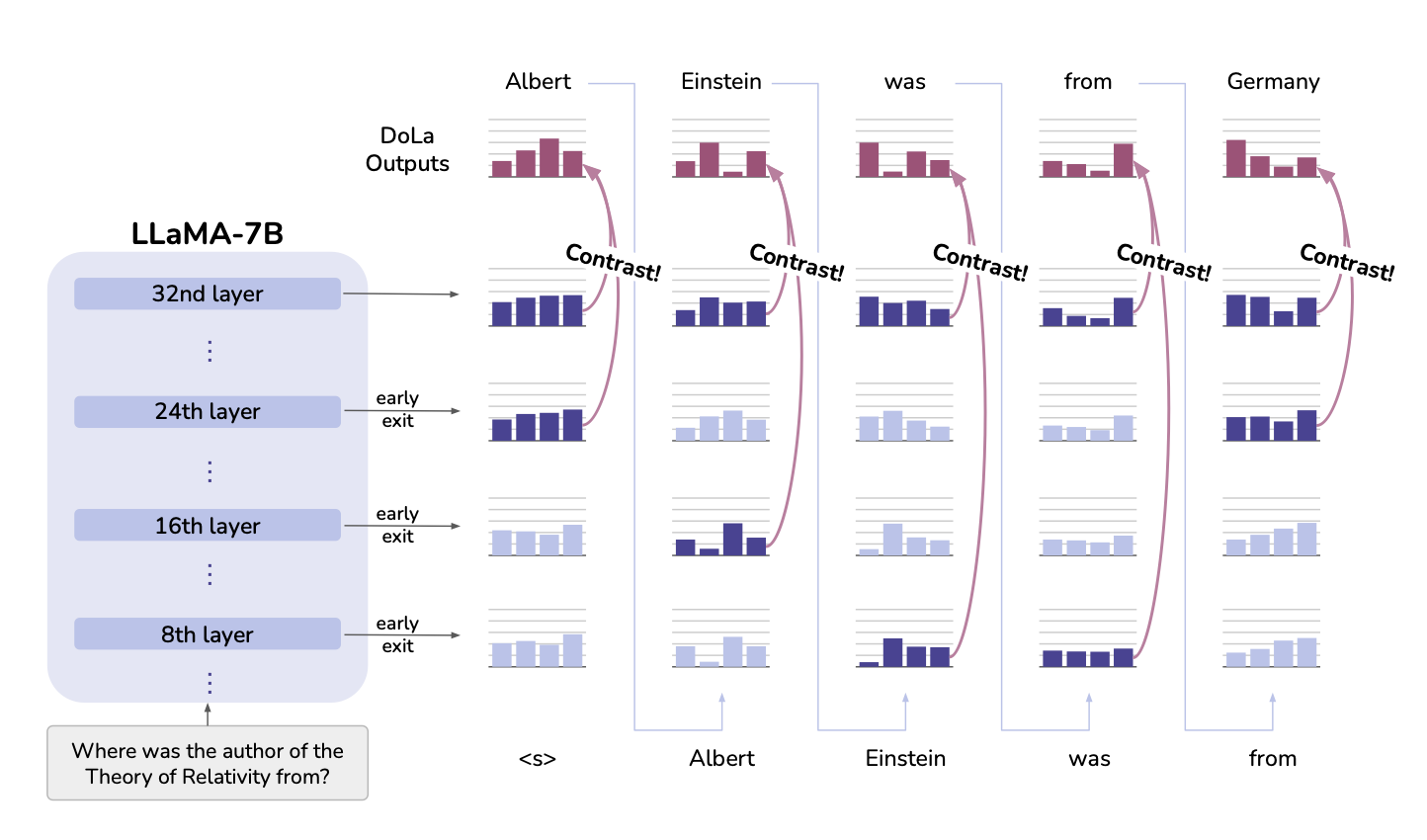
🛠️ 제안 방법: DOLA
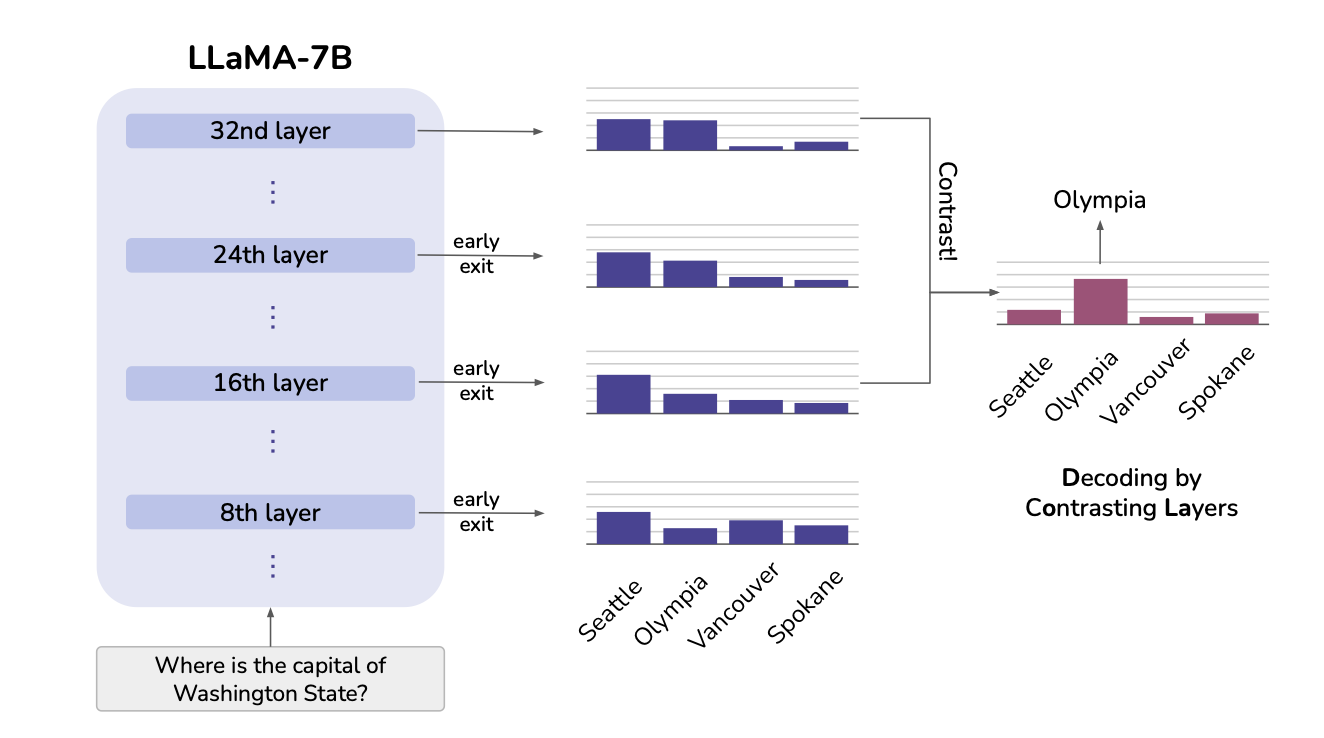
- 계층 간 대조
LLM 내부에서 낮은 계층은 주로 문법적/구문적 정보를 처리하고, 높은 계층은 의미적/사실적 정보를 처리합니다.
DOLA는 낮은 계층과 높은 계층의 출력 확률(logit)을 비교하여, 더 사실에 가까운 높은 계층의 정보를 강조합니다.
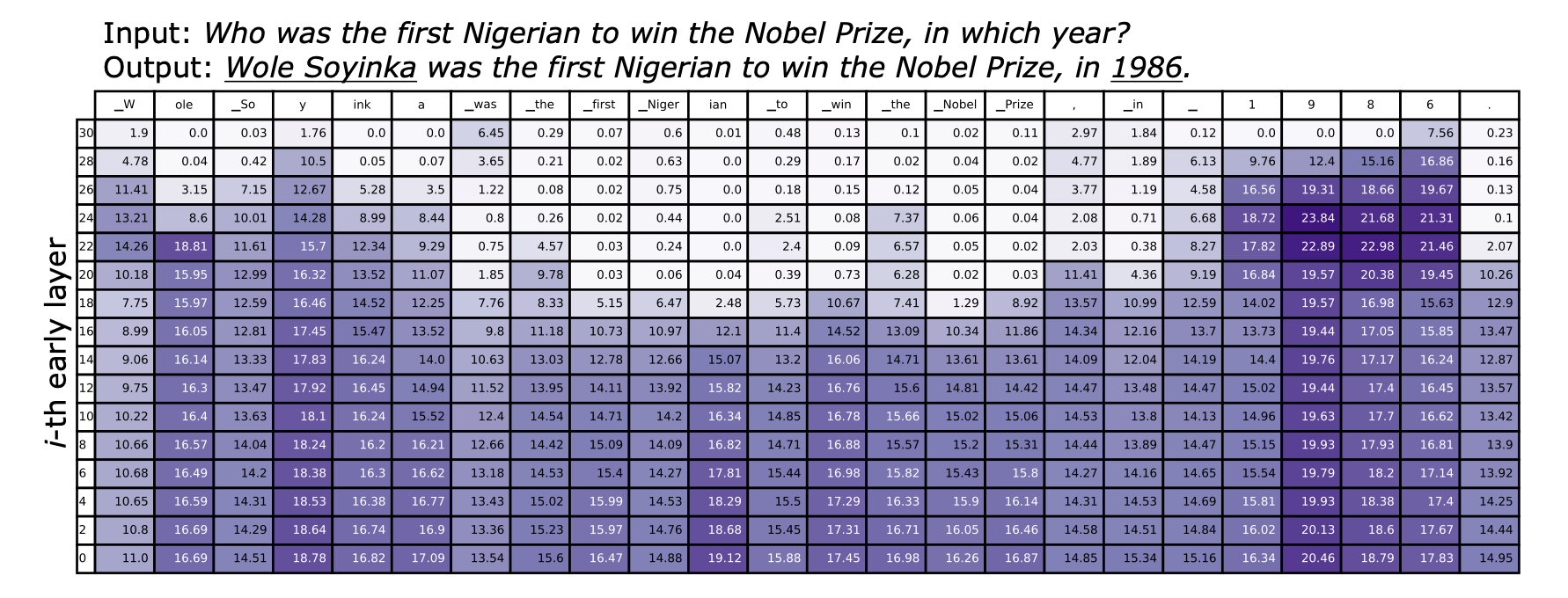
- 동적 계층 선택
각 디코딩 단계에서, 최종 계층과 가장 큰 차이를 보이는 "최적의 낮은 계층"을 자동으로 선택합니다.
이를 통해 사실성을 극대화하면서도 불필요한 계산을 줄일 수 있습니다.
- 적응형 확률 제한
예측 확률이 일정 기준 이하인 경우, 해당 토큰을 제외하여 오류를 줄이는 전략을 사용합니다.
📊 실험 결과
- 데이터셋
TruthfulQA, FACTOR 등 다양한 사실성 평가 데이터셋과 개방형 생성 평가(Task: StrategyQA, GSM8K 등)를 사용하였습니다. - 성능 비교
TruthfulQA에서 LLaMA 모델(7B, 13B, 33B, 65B)에 DOLA를 적용한 결과, 사실성 점수가 12~17% 증가하였습니다.
FACTOR, GSM8K와 같은 데이터셋에서도 기존 디코딩 방법 대비 안정적인 성능 향상을 보였습니다. - 효율성
DOLA는 기존 디코딩 시간 대비 1.01~1.08배의 소폭 지연만 발생하며, GPU 메모리 오버헤드는 약 10% 미만으로 유지되었습니다.
🔍 주요 기여
환각 감소: LLM 내부 계층 간 차이를 활용하여, 외부 지식 없이도 사실성을 높였습니다.
범용성: 추가 학습이나 모델 수정 없이 다양한 LLM에 적용 가능합니다.
효율성: 최소한의 계산 증가로 실용성을 확보하였습니다.
🚀 한계 및 향후 연구 과제
- 외부 지식 활용의 부재
DOLA는 모델 내부에 저장된 지식에 의존하기 때문에, 학습 과정에서 잘못 학습된 정보에 대한 수정이 어렵습니다. 외부 지식과 결합하거나 추가적인 검증 단계를 통합하는 연구가 필요합니다.
다양한 응용 사례에 대한 검증 부족
DOLA는 사실성을 개선하는 데 초점을 맞추고 있어, 창의성, 문법성, 맥락 이해 등의 다른 평가 기준에서의 효과는 충분히 검증되지 않았습니다. 이러한 다양한 영역에 대한 적용 가능성을 검토하는 추가 연구가 요구됩니다.

GDG Gachon Ai 스터디입니다.