
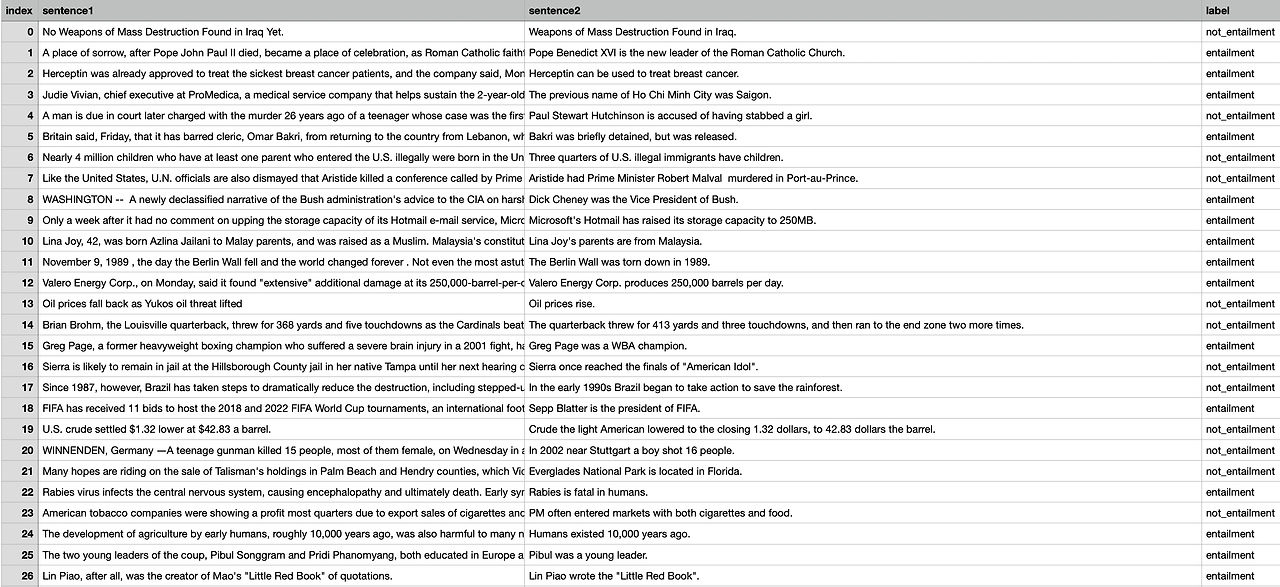
0. Abstract
자연어 이해(Natural Language Understanding)기술은 특정 기능,장르,데이터셋에 국한되지 않게 언어를 처리할수 있어야 합니다.
따라서 해당 논문은 다양한 자연어 이해 영역에서의 성능 지표를 위해서 탄생한 일반어 이해평가(GLUE)벤치마크를 소개하고 있습니다.
1. Introduction
인간이 언어를 일반적이며(general), 유연하고(flexible), 강건하게(robust) 이해하는 것과는 달리, 대부분의 NLU(Natural Language Understanding) model들은 특정 작업을 위해 설계되었으며, out-of-domain상태인 데이터에서의 성능하락이 존재합니다.
연구진들은 만약 단순히 입출력간의 단순한 관계를 감지하는것을 넘어서는, 언어적인(linguistic)이해를 가지는 model을 만들어야 한다면, 다른 domain에서 다양한 linguistic task를 실행하는 unified model을 만드는 것이 매우 중요하다고 주장합니다.
Unfied model를 설계하는 방향의 연구를 위해 연구진들은 일반어 이해평가인 GLUE벤치마크를 제시합니다.
GLUE는 질문 답변,감정 분석,텍스트 함의 등의 일반어 이해 작업 모음과 모델의 평가,비교, 분석을 위한 플랫폼입니다. 또한 모델 아키텍쳐에서 단일문장, 한쌍의 문장을 입력받아 대응되는 예측을 만들어내는 제약 이외에는 제약이 존재하지 않는 구조입니다.
따라서 Task마다 다양하고 복잡한 종류들로 구성되어 있어 Sample-efficient learning과 다양한 영역에서 지식전이(Knoledge-transfer)를 촉진하는 방식으로 linguistic한 지식을 학습하는 모델을 선호하게 합니다.
GLUE에 포함되어 있는 dataset들은 기존에 존재하던 dataset들로부터 기인하였으며, dataset중에서 4개는 benchmark가 공정하게 사용되는지 확인하는 데 사용되는 private-held test data를 제공합니다.
이에 더불어서 GLUE는 model이 학습한 유형을 이해하고, 언어적으로 의미 있는 해결전략을 추구하는것을 장려하기 위해 set of hand-crafted analysis example을 제공한다. 해당 dataset은 model이 robust하게 작업을 해결하려면 반드시 다뤄야 하는 common challenge에 초점을 맞추도록 설계된 데이터 셋 입니다.
해당 벤치마크를 활용하기 위해 연구진들은 unified multi-task trained models인 ELMo를 활용하였지만 여전히 절대적인 점수가 낮게 나오는 문제를 통해서 기존의 모델의 경우 strong lexical signals에는 강하지만 struggle with deeper logical structure에는 약한 모습을 보여준다고 설명합니다.
위의 내용을 요약하자면 다음과 같습니다.
- GLUE는 9개의 NLU task 모음이며, 각각의 task는 주석이 달려져 있는(annotated) dataset으로 구축되었으며 다양한 genre, dataset size, degrees of difficulty를 다루도록 선별되었다.
- privately-held test data를 기반으로 하는 online evaluation platform과 leaderboard가 존재하며, model-agnostic 하여 아키텍처의 제약을 두지 않는다.
- expert-constructed diagnostic evaluation dataset을 제공한다.
- 기존 모델의 벤치마크 결과 deeper logical structure에 취약한 모습을 보임
2. Related Work
Collobert의 경우 공유된 문장 이해 구성 요소를 가진 multi-task모델을 사용하여 품사 태깅, 청킹, 개체명 인식, 의미역 결정을 공동으로 학습했고 최근의 연구는 핵심 NLP Task의 레이블을 사용하여 DNN의 하위 수준을 지도학습하거나 multi-task학습을 위한 corss-task 공유 메커니즘을 이용하였습니다.
또한 multi-task학습을 넘어서 일반적인 자연어 이해 시스템 개벨에대한 연구는 sentence-to-vector encoder를 기반으로 해서 레이블의 유무 그리고 둘의 조합으로 이뤄진 데이터를 활용했습니다.
이를 기반으로 하여금 SentEval과 같은 표준 평가가 체계화 되었습니다.
SentEval은 GLUE와 동일하게 하나 또는 두 개의 문장을 입력으로 하는 기존 분류 작업 세트에 의존하지만GLUE와 달리, SentEval은 문장-벡터 인코더만 평가하므로 문장을 독립적으로 다루는 작업에 대한 모델 평가에 적합합니다. 그러나 문장 간 맥락화와 정렬은 기계 번역, 질문 답변, 자연어 추론과 같은 작업에서 필수적입니다.
따라서 GLUE는 이러한 방법의 개발을 촉진하도록 설계되었고 모델에 구애받지 않아 어떤 종류의 표현이나 맥락화도 가능하며, 문장에 대한 명시적인 벡터나 Symbolic한 표현을 전혀 사용하지 않는 모델도 포함합니다.
또한 GLUE는 또한 평가 모음에 포함된 평가 작업의 선택에서 SentEval과 차이가 있습니다. SentEval의 많은 작업들은 MR, SST, CR, SUBJ와 같이 감성 분석과 밀접하게 관련되어 있습니다.
GLUE에서는 다양하면서도 어려운 벤치마크를 구성하였다고 설명합니다.
decaNLP 역시 여러 데이터셋에 대한 성능을 기반으로 NLP 시스템을 평가합니다. 이 벤치마크는 요약 및 텍스트-SQL 의미 파싱과 같은 작업을 질문 답변의 형태로 변환합니다. 해당 방식은 GLUE의 것과는 유사하면서도 보상 체계에서의 차이점을 지니고 있습니다.
3. Tasks
GLUE는 9개의 영어 문장 이해 task를 중심으로 구성되어 있으며, 이는 다양한 도메인, 데이터 양, 난이도를 포괄합니다. GLUE의 목표는 일반화 가능한 NLU 시스템의 개발을 촉진하는 것이기에 모든 task에 걸쳐 상당한 지식(예: 훈련된 매개변수)을 공유하면서도 task별 특성을 유지해야 좋은 성능을 낼 수 있도록 설계되었습니다.
각 작업에 대해 사전학습를 하지 않거나외부를 사용해 개별 모델을 훈련시킨다음 평가하는것도 가능하지만 연구진들은 데이터가 부족한 작업들이 포함되어 있어 이러한 접근 방식은 결국 경쟁력이 떨어질 것으로 예상했습니다
GLUE에서 제동하는 task들은 다음과같이 구분되어 있으며 크게 3종류로 나뉘어지게 됩니다.
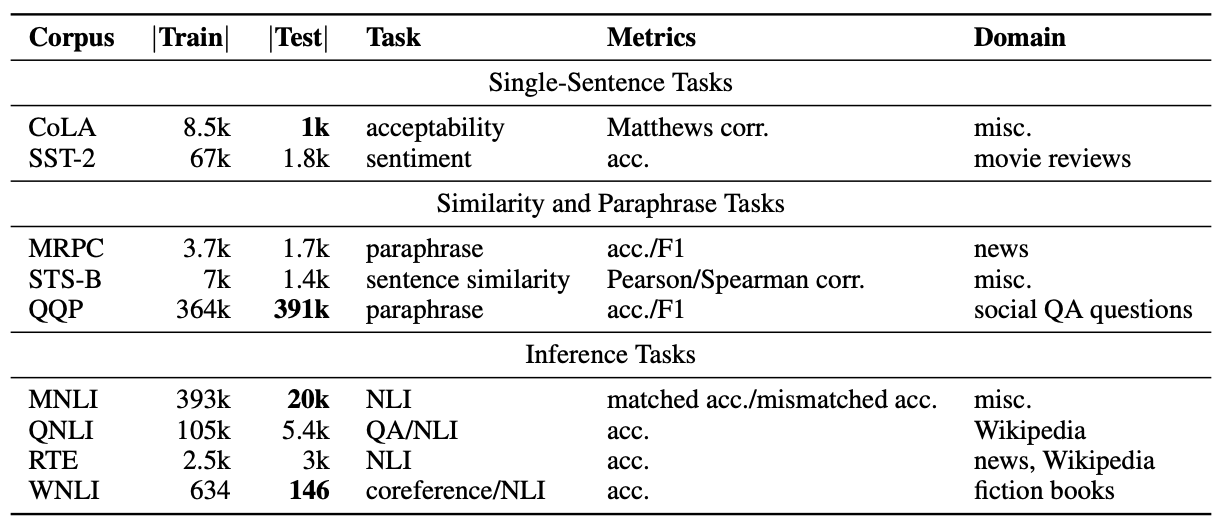
Single-Sentence Tasks
Similarity and Paraphrase Tasks
Inference Task
3.1 Single-Sentence Tasks
CoLA

Corpus of Linguistic Acceptability(CoLA)는 언어 이론과 관련된 책과 저널 기사에서 추출된 문법적으로 적합한지에 대한 판단으로 이루어진 dataset입니다.
각각의 예시들은 해당 영어 문장이 문법적인지 아닌지에 대해 주석처리(annotated)된 sequence들입니다.
CoLA에서는 evaluation metric으로 불균형한 이진분류에 대해 -1과 1 사이의 값(0은 uninformed guessing에 대한 성능을 나타냄)으로 evaluate 하는 매튜 상관 계수(Matthews correlation coefficient)를 사용

GLUE에서는 CoLA의 저자로부터 private label을 얻은 standard data set을 사용하며, test set에서 in-of-domain section과 out-of-domain section의 조합에서의 단일 성능 수치를 report
SST-2

Stanford Sentiment Treebank(SST-2)는 영화 리뷰 sentence와 해당 sentence에 대한 sentiment의 human annotation으로 이루어진 dataset입니다.
SST-2로 수행하는 task는 주어지는 문장에 대해 심리(sentiment)를 예측하는 것입니다. GLUE에서는 positive와 negative의 두 가지 class만 사용하며, 문장단위의 레이블(sentence-level label)만 사용
3.2 Similarity and Paraphrase Tasks
MRPC
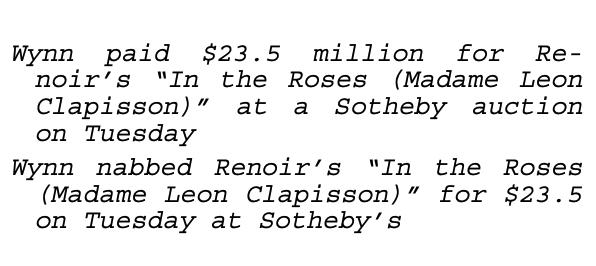
Microsoft Research Paraphrase Corpus(MRPC)는 온라인 뉴스로부터 추출된 sentence pair와, 해당 sentence pair를 구성하는 sentence가 의미상으로 같은 sentence인지에 대한 human annotation으로 이루어져 있는 데이터셋 입니다.
MRPC는 불균형한(imbalanced)데이터이기 때문에(68% positive), accuracy와 f1 score 둘 다 사용하여 report
QQP

Quora Question Pairs(QQP)는 질문 답변 웹사이트인 Quora에서 추출한 질문 pair의 모음들로 구성된 dataset입니다.
MRPC의 경우처럼, sentence가 의미상으로 같은 sentence인지에 대한 human annotation으로 이루어져 있고 불균형한(imbalanced)데이터이기 때문에 (63% negative) accuracy와 f1 score 모두 사용하여 report
STS-B
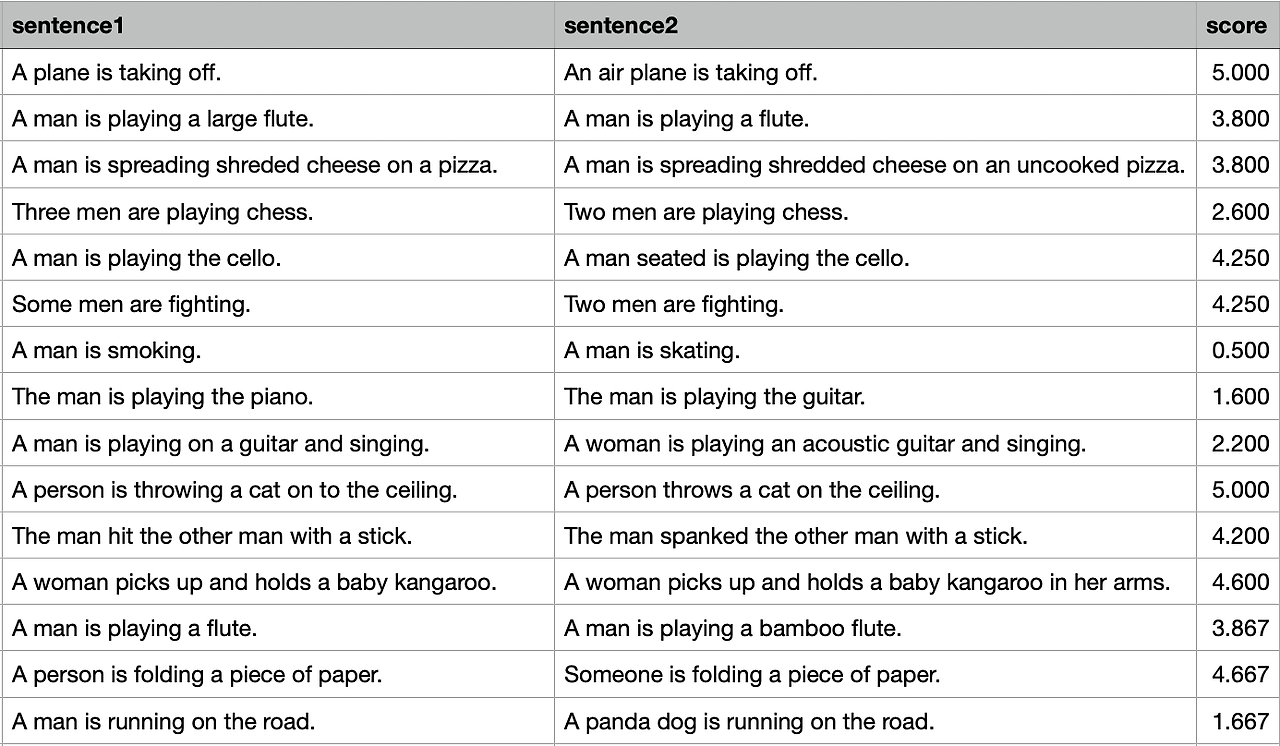
Semantic Textual Similarity Benchmark(STS-B)는 뉴스 헤드라인, 동영상/이미지 캡션, 자연어 추론 데이터셋에서 추출한 sentence pair의 모음입니다.
각각의 pair에 대해서 1부터 5까지의 유사도 점수를 매긴 human-annotated label이 대응되며, STS-B를 통해 진행하는 task는 해당 유사도 점수를 예측하는 것이다. 또한 이를 Pearson and Spearman correlation coefficients로 평가를 하게 됩니다.
####피어슨,스피어만 상관계수
피어슨 상관계수는 두 변수 X, Y 간의 선형 상관 관계를 계량화한 수치로 공분산을 표준편차의 곱으로 나눈 값이다.(-1 ~ 1)
+-1은 선형 상관관계 있음 0은 선형 상관관계 없음을 의미한다. 대체적으로 0.3 이상이면 상관관계가 존재라고 평가
스피어만 상관계수는 두 변수의 순위 사이의 통계적 의존성을 측정하는 비모수적 척도이다. 원시데이터가 아닌, 각 변수에 대해 순위를 매긴 값을 기반으로 상관관계를 측정한다. 순위를 이용하기 때문에 연속형 변수가 아닌 순서형 변수인 경우에도 용 가능하다.
피어슨 상관계수와 마찬가지로 -1 ~ 1사이의 값을 가지며 단순 관계만 측정한다. 순위로 변환해서 상관관계를 측정하기 때문에 선형 외에 비선형 관계도 나타낼 수 있다.
3.3Inference Task
MNLI

Muti-Genre Natural Language Inference Corpus(MNLI)는 crowd-sourcing으로 구축된 textual entailment annotation이 있는 sentence of pair로 이루어진 dataset입니다.
MNLI로 수행하는 task인 textual entailment는, premise(전제)와 hypothesis(가설)가 주어지며, premise(전제)가 hypothesis(가설)를 수반(entail)하는지 예측하는 task
premise(전제)가 hypothesis(가설)를 수반하면 entailment, 모순(contradict)되면 contradiction, 둘 다 아니면 neutral의 label로 예측
Premise sentence들은 transcribed speech, fiction, government report를 포함한 10개의 다른 경로로부터 수집되었습니다.
QNLI
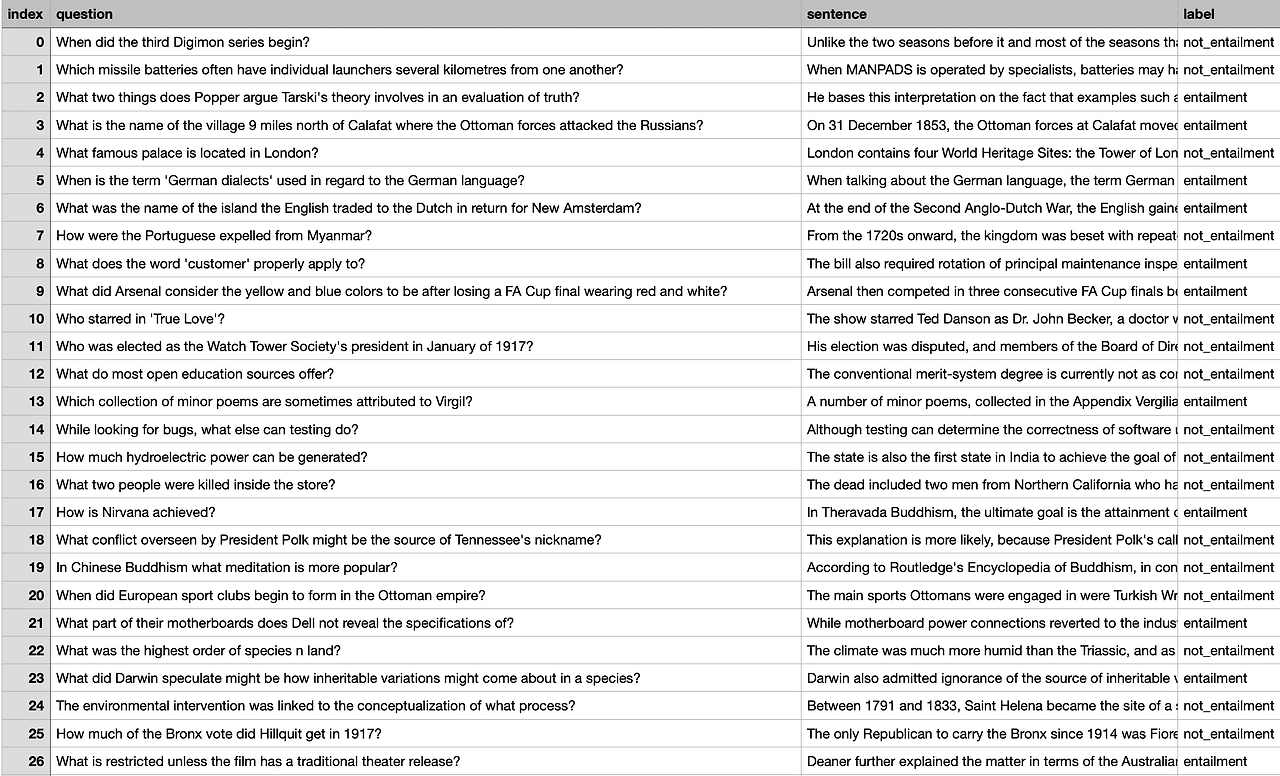
Question-answering NLI(QNLI)는 Stanford Question Answering Dataset(SQuAd)를 변형시킨 dataset입니다.
SQuAD는 question-paragraph의 pair로 구성된 question-answering dataset이다. paragraph는 자기 자신과 대응되는 질문에 대한 답변을 포함는 데이터셋 입니다.
SQuAD를 통해 수행하는 task는 질문 답변 task인데, QNLI는 SQuAD dataset을 변환하여 sentence pair classification으로 변환한다. 먼저, question과 이에 대응하는 paragraph를 이용하여 pair of sentence를 형성하고, 이렇게 형성된 문장 쌍들 중에서 어휘적 중복(lexical overlap)이 낮은 쌍을 필터링해 선별합니다.
연구진들은 이러한 수정을 통해 모델이 옳바른 답변를 선택할 필요를 없애지만 답변이 input속에 항상 있을 것이라는, 또한 lexical overlap(어휘적 중복)이 신뢰할 수 있는 단서일 것이라는 "단순화된 추정"도 제거해준다고 설명합니다.
이후, 수정된 QNLI dataset을 통해서 paragraph가 question에 대한 answer를 포함하고 있는지에 대한 classification task를 수행
RTE
Recognizing Texual Entailment(RTE) dataset은 annual textual entailment challenges로부터 추출되었다. 본 연구에서는 RTE1, RTE2, RTE3, RTE5를 혼합하여 사용했다고 설명합니다.
또한 원문 dataset인 RTE들은 위에서 소개한 MNLI와 같이 entailment, neural, contradiction의 3개 class로 구분되어있었는데, GLUE에서의 RTE는 neutral과 contradiction을 not_entailment로 묶어 entailment와 not_entailment의 2개의 class로 수정하였다.
WNLI
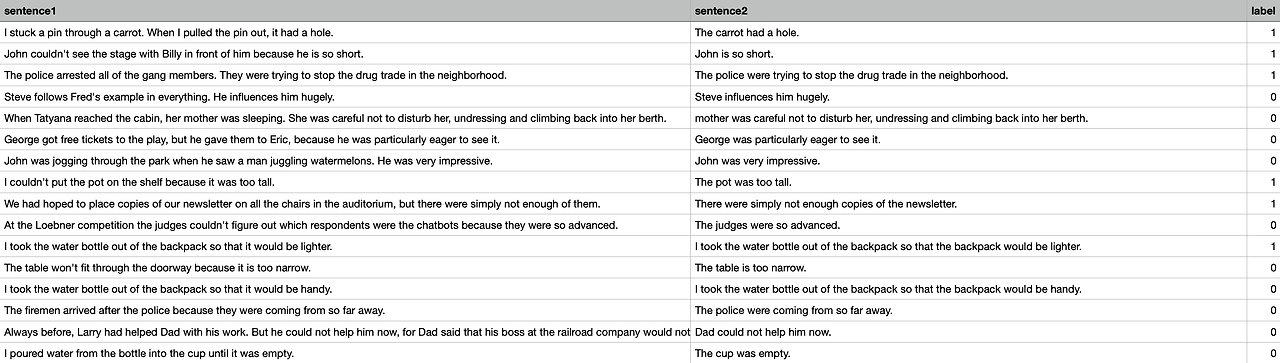
Winograd NLI(WNLI)는 QNLI와 비슷하게 기존의 존재하던 Winograd Schema Challenge의 변형으로Winograd Schema Challenge는 reading comprehension task입니다.
reading comprehension task란, model이 대명사(pronoun)가 있는 문장을 읽고 해당 대명사의 참조를 선택 목록 중에서 선택해야 하는 task입니다.
reading comprehension task를 sentence pair classification task로 변환해야하고 이를 위해 각 문장의 대명사를 가능한 각각의 참조로 바꾸고,sentence와 함께 쌍을 만들게 됩니다.
이후, 원본 sentence가 대명사가 대체된 문장을 수반하는지 예측하는 이진 분류 task를 수행
WNLI의 training set이 balanced data인 것에 비해, test set은 imbalanced data이다. 또한,
training set에 overfitting 되어있으면 development set에서는 성능이 크게 하락할 수 있습니다.
3.4 Evaluation
모델을 평가하기 위해서는 제공되는 task에 대한 test data에 대한 모델 수행결과를 GLUE 웹사이트에 업로드하여 점수를 책정받아야 합니다.
GLUE benchmark 웹사이트는 task별 score와 해당 task들의 macro-average score를 보여주고, 리더보드 상에서의 순위를 결정한다. accuarcy와 f1 score를 같이 사용하는 task의 경우, 전체 task의 macro-average score를 구할 때에는 task에 대한 두 metric의 unweighted average를 해당 task의 score로 계산한다.
4. DIAGNOSTIC DATASET
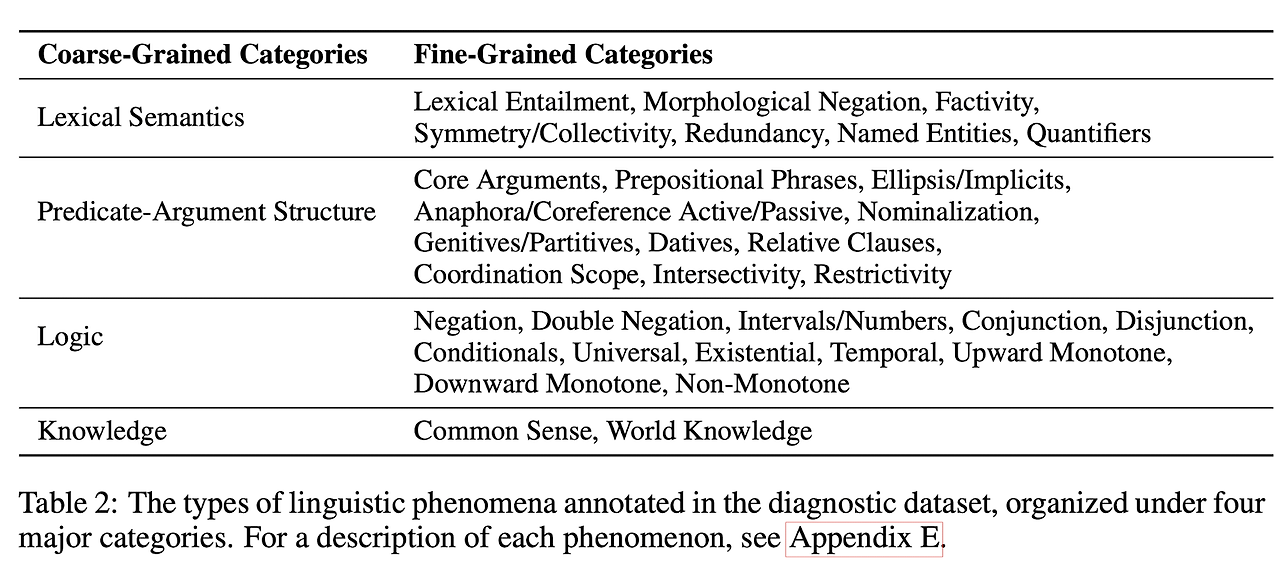
GLUE에서는 model의 성능 분석을 위해 수동으로 선별된 small testset을 제공한다. 벤치마크가 application 중심의 distribution을 반영하는 것과는 달리, diagnostic dataset은 저자들이 model이 capture하기에 중요하고 흥미롭다고 생각하는 pre-defined set of phenomena에 중점을 둔다.
각각의 예시들은 자연어 추론을 위한 문장쌍과 phenomena로 구성되어 있습니다.
또한 연구진들은 이러한 데이터셋이 다양한 언어학적 현상에 대한 예제를 지니고 있고 다양한 도메인에서 발생하는 문장들을 기반으로 하였기에 합리성을 지니고 있다고 주장합니다. 그 예제는 다음과 같습니다.
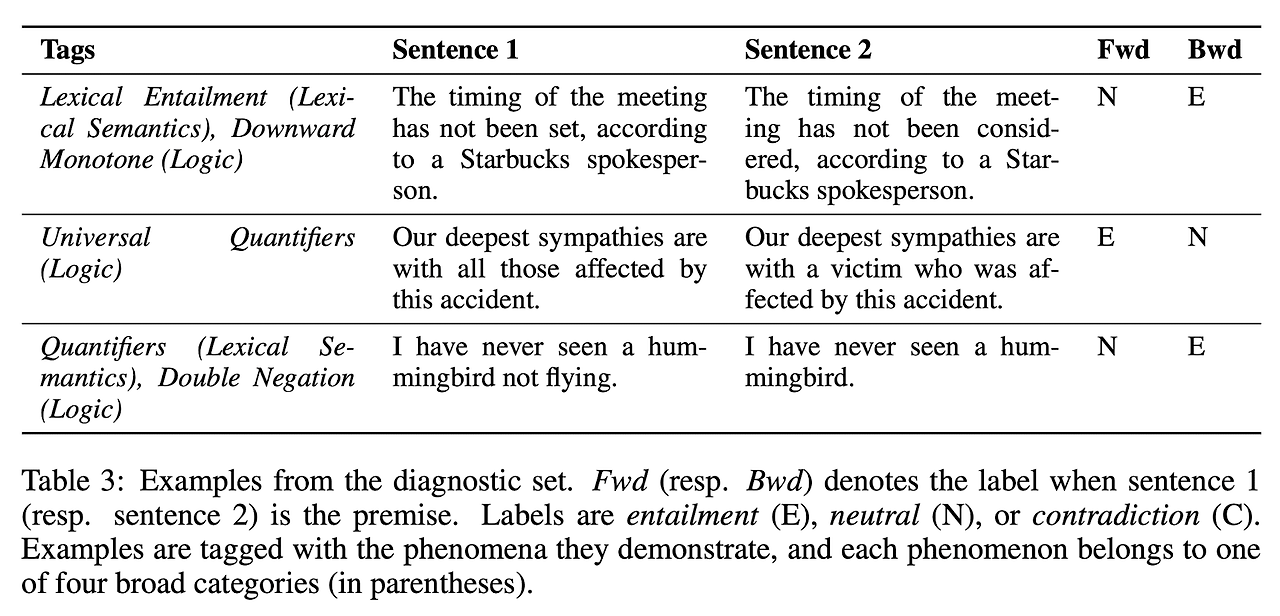
5. Baselines
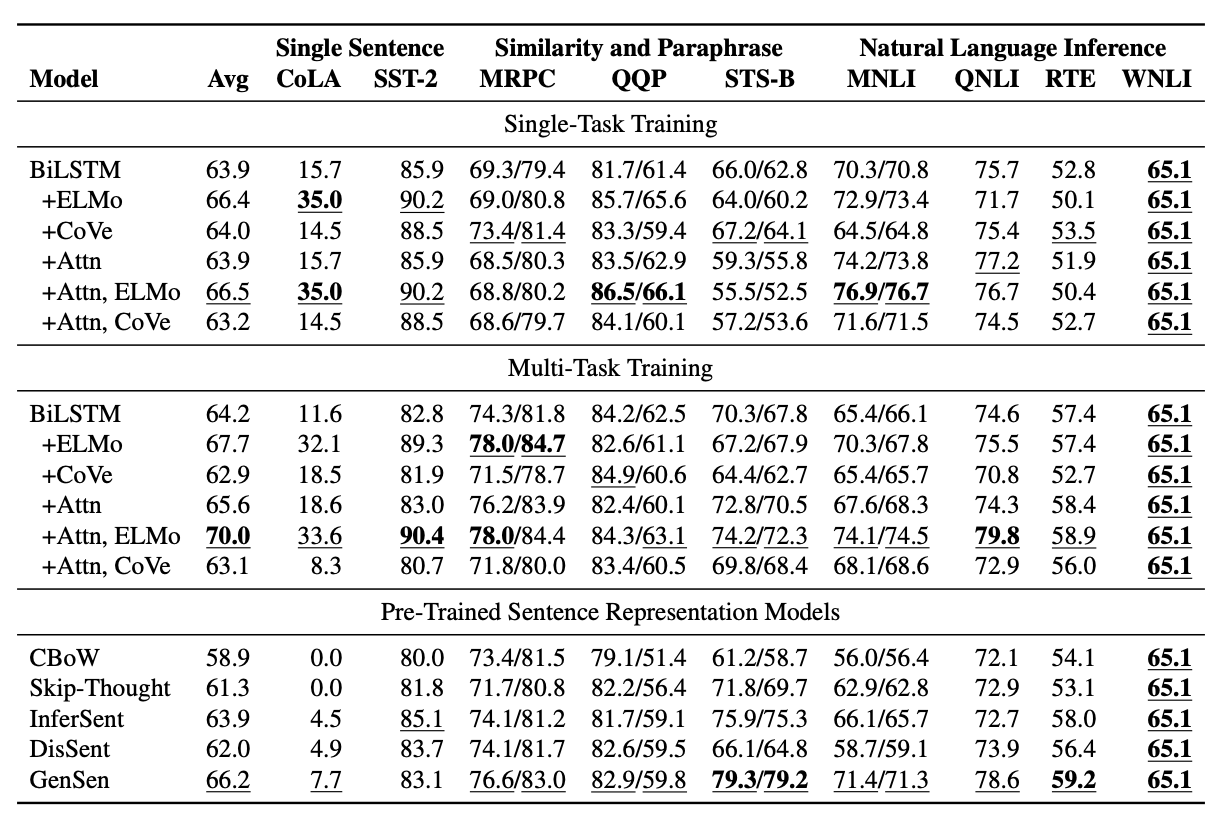
연구진들은 기준선으로 GLUE수행에 대해서 훈련된 multi-task과 사전학습 기법을 기반으로하여 여러가지 경우에 대해서 평가를 진행했다고 설명합니다.
아키텍쳐: 가장 기본적인 아케텍처의 경우 sentence-vector 인코더를 기반으로 해서 맥스풀링,GLOVE, BiLSTM등을 활용하였습니다.
사전 학습: ELMo,CoVe 두가지 방식을 사용
ELMo는 Billion Word Benchmark에서 훈련된 두 개의 2층 신경 언어 모델을 사용합니다. 각 단어는 두 모델의 각 층의 corresponding hidden state의 선형 결합을 취함으로써 생성된 contextual 임베딩으로 표현됩니다.
CoVe는 원래 영어-독일어 번역을 위해 훈련된 2층 BiLSTM 인코더를 사용합니다. 단어의 CoVe 벡터는 최상위 층 LSTM의 corresponding hidden state입니다.
train:BiLTSM을 기반으로 해서 ADAM 옵티마이저등을 사용해 학습을 진행하였고 학습률이 10^-5미만이거나 5번의 validation이후 성능상의 개선이 없으면 학습을 중단하는 방식을 사용했습니다.
6. BENCHMARK RESULTS
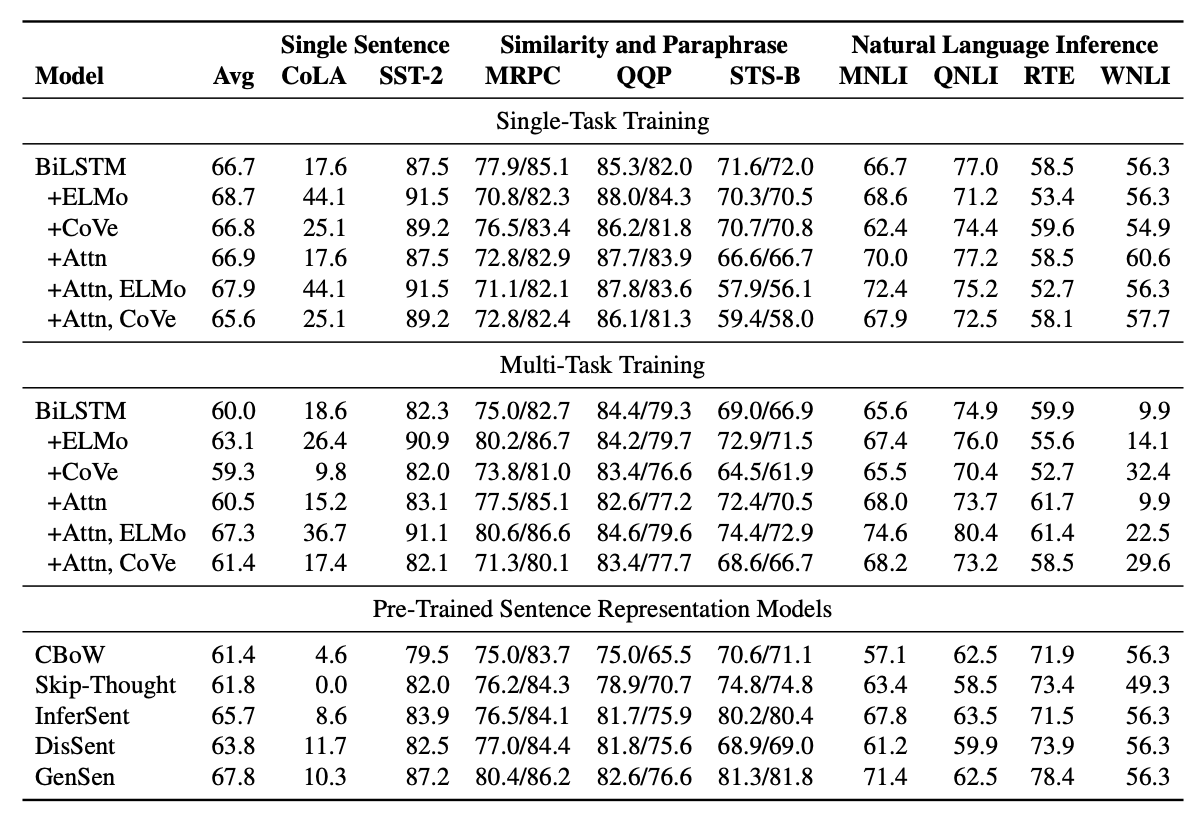
연구진들은 attention매커니즘이나 ELMo를 사용하는 모델들중 multi-task가 single-task보다 전반적으로 좋은 점수를 기록하는 것을 발견했고 특히 attention매커니즘이 단일 작업에서는 무시할만한 성능이지만 multi-task에서 유의미한 개선이 있다는것을 발견했습니다.
사전 훈련된 문장 표현 모델들 중에서는 CBoW에서 Skip-Thought로, 그리고 InferSent와 GenSen으로 이동하면서 꽤 일관된 향상을 보여주고 있습니다.
작업별 결과에서는 sentence representation models이 CoLA에서 해당 작업에 직접 훈련된 모델들에 비해 상당히 성능이 떨어진다는 것을 발견합니다. 반면에 STS-B의 경우, 작업에 직접 훈련된 모델들이 최고의 문장 표현 모델의 성능에 비해 크게 뒤처집니다. 마지막으로, 어떤 모델도 특별히 잘 수행하지 못하는 작업들이 있습니다.
이러한 초기 결과는 GLUE를 해결하는 것이 현재 모델과 방법의 능력을 넘어선다는 것을 나타냅니다.
7. Analysis
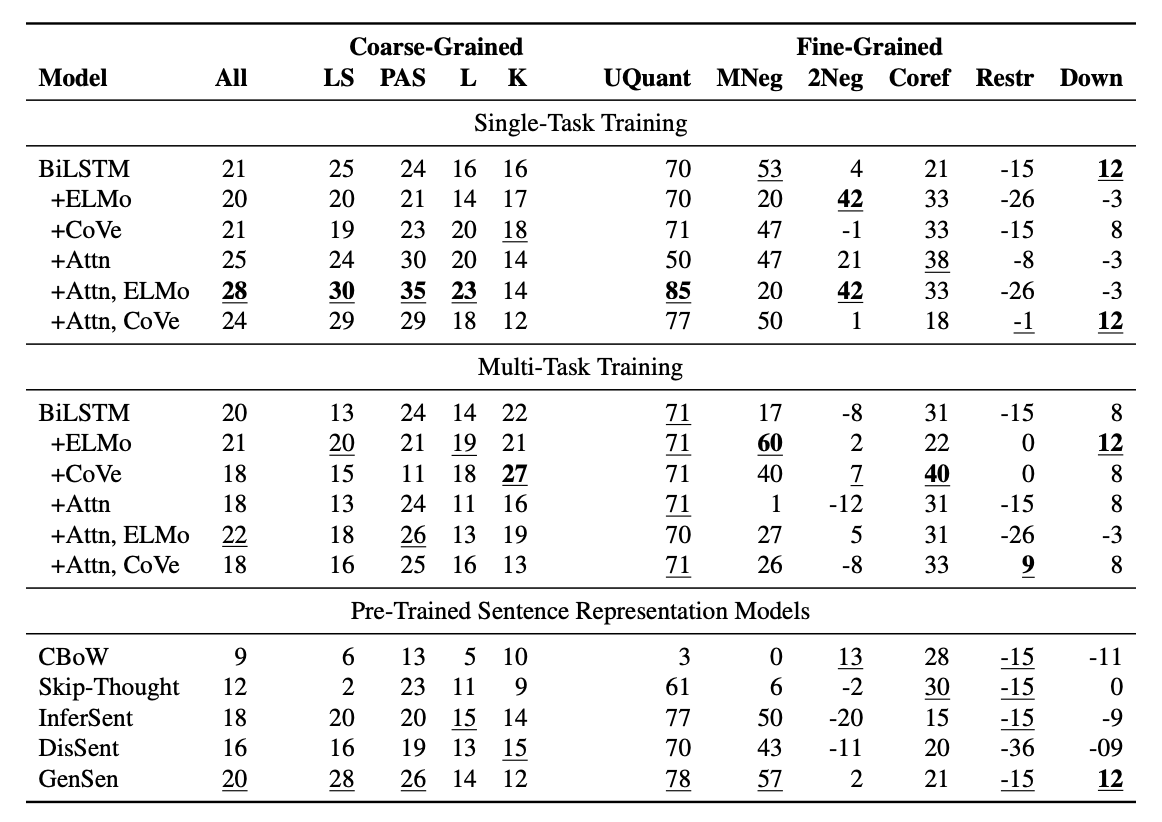
Coarse Categories: 모든 모델의 전반적인 성능이 낮게나오며 성능은 Predicate-Argument구조에서 더 높고 논리에서 더 낮은 경향을 보이지만 직접 비교하기에는 어렵습니다. 주요 벤치마크와 달리, multi-task모델은 거의 항상 single-task모델보다 성능이 하락함을 보여주고 있습니다.
GLUE 작업에 대해 훈련된 모델들은 전반적으로 사전학습모델 대비 성능이 우수합니다. attention메커니즘 사용이 ELMo나 CoVe 사용보다더 큰 영향을 미치는데, 이는 주의 메커니즘이 NLI에서 중요하다는 것을 나타냅니다.
Fine-Grained Subcategories: 대부분의 모델이 universal quantification를 상대적으로 잘 처리하는것을 나타내고 있습니다.
또한 모델 간 다양한 약점을 확인 할수 있는 결과를 도출하고 있습니다.
전반적으로, attention메커니즘과 같이 out of domain데이터에 대한 성능을 향상시킬 수 있다는 것을 보여주며, ELMo와 CoVe 같은 전이학습들이 특정한 언어 정보를 인코딩한다는 것을 알 수 있습니다. 그러나 표현 능력의 증가는 과적합으로 이어질 수 있다고 설명합니다.
연구진들은 GLUE의 플랫폼과 진단 데이터셋이 향후 유사한 분석에 유용할 것으로 기대하며, 이를 통해 모델 설계자들이 그들의 모델의 더 잘 이해할 수 있을 것이라고 주장합니다.
8. Conclusion
연구진들은 자연어 이해 시스템을 평가하고 분석하기 위한 플랫폼 및 리소스 모음인 GLUE를 소개하며 multi-task모델들이 각 작업에 대해 개별적으로 훈련된 모델들의 결합된 성능보다 더 나은 성능을 보인다는 것을 발견했습니다. 또한 NLU 시스템에서 주의 메커니즘과 ELMo와 같은 전이학습 방법의 유용성을 확인했으며 추가적인 개선의 여지가 있다고 설명합니다.
따라서 연구진들은 범용 NLU 모델을 어떻게 설계할 것인가에 대한 질문은 여전히 해답을 찾지 못했으며, 우리는 GLUE가 이 과제를 해결하는 데 큰 기여를 할것이라고 주장합니다.
