LLMEmbed: Rethinking Lightweight LLM’s Genuine Function in Text Classification (ACL 2024)
LLMEmbed: Rethinking Lightweight LLM’s Genuine Function
in Text Classification
1. 문제점
- 모델 크기의 증가로 인한 inference 지연 → LLM은 성능이 뛰어나지만, 파라미터 수가 늘어나면서 추론 시간이 길어짐.
- 프롬프트 기반 패러다임의 복잡성과 높은 cost → COT, TOT 같은 프롬프트 엔지니어링이 필요하고, 경량 LLM에서는 기대만큼 성능을 못 내는 경우가 많음.
- 경량 LLM의 성능 한계 → LLAMA2-7B 같은 경량 모델은 파라미터 수가 작아서 자원 소모는 적지만, GPT-4 같은 대형 모델에 비해 복잡한 작업(예: 텍스트 분류나 추론)에서 성능이 떨어짐.
- 프롬프트 기반 접근법의 한계: Hallucination → 프롬프트 기반 접근법에서는 LLM이 입력을 제대로 이해하지 못하거나, 입력과 상관없는 내용을 생성하는 환각(hallucination) 현상이 발생할 수 있음.
2. 제안 방법
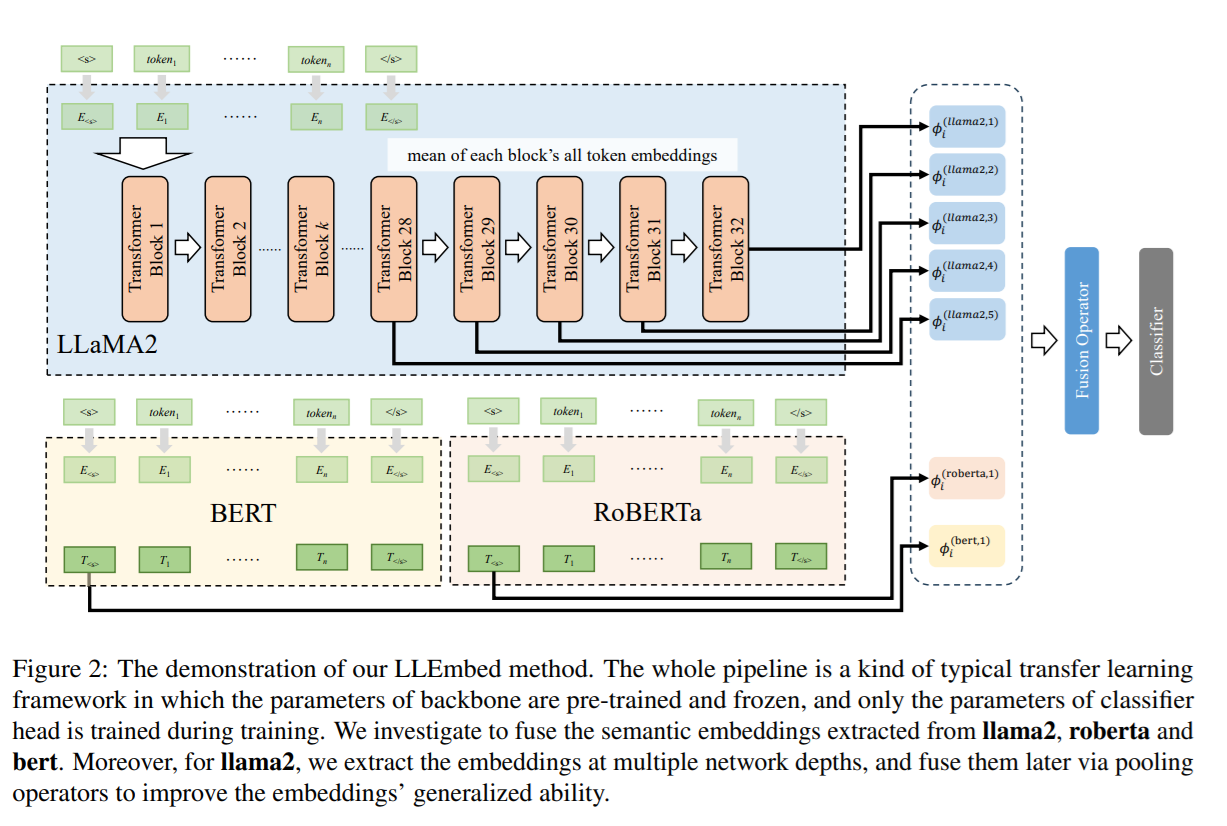
제안된 LLMEmbed 방법? 아이디어
- 프롬프트 기반 접근법 대신 Lighweighted LLM의 의미적 임베딩(semantic embeddings)을 직접 활용하여 텍스트 분류 작업을 수행.
- 이를 통해 복잡한 프롬프트 설계 없이도 높은 성능을 유지하고, 추가적인 토큰 비용(token overhead) 없이 효율적으로 학습.
LLMEmbed의 장점
- 환각 현상(Hallucination) 없음: 입력과 출력을 정렬하기 위해 복잡한 프롬프트를 설계할 필요가 없기 때문에, LLM이 잘못된 응답을 생성하는 현상이 발생 X.
- 더 낮은 비용과 높은 효율성: 기존의 프롬프트 기반 방법보다 학습 비용이 낮고, 병렬 처리가 가능하여 더 빠르고 효율적으로 분류 작업을 수행.
- 확장성과 유연성: LLMEmbed는 Lighweighted LLM의 임베딩을 RoBERTa, BERT와 같은 판별 모델(discriminative models)과 결합하거나, 다른 표현 학습 방법을 사용하여 성능을 향상.
LLMEmbed 구현
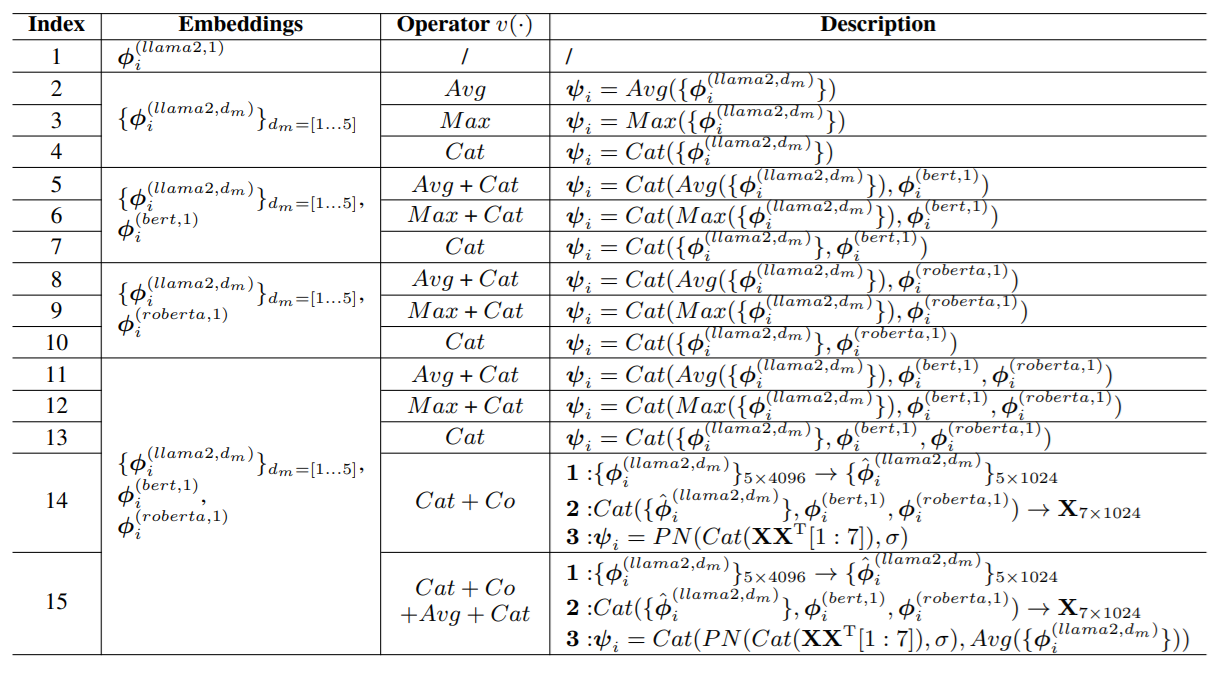
- 임베딩 추출
- 사용된 모델: LLaMA, RoBERTa, BERT
- : 선택된 모델 m의 네트워크 깊이 dm에서 임베딩을 추출하는 함수
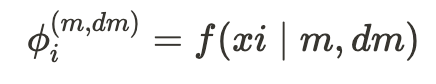
- 여기서 는 i번째 데이터 포인트,
- m은 선택된 백본 모델 (LLaMA, RoBERTa, BERT),
- 은 해당 모델의 특정 블록 또는 레이어의 깊이.
- 임베딩 융합
각 모델에서 추출한 임베딩를 하나의 최종 임베딩 로 결합.
- 는 임베딩 결합을 위한 연산자(operator)로, 평균 풀링(Average Pooling), 최대 풀링(Max Pooling), 또는 연결(Concatenation) 방식을 사용
수식으로 표현하면 다음과 같습니다:
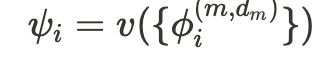
- 여기서 ψi는 i번째 데이터 포인트의 최종 결합된 의미적 임베딩
- 최종 분류기
결합된 임베딩 는 최종 분류기 헤드 에 입력되어 출력 결과 를 생성. 이 과정에서, 분류기의 매개변수는 크로스 엔트로피 손실(Cross-Entropy Loss)을 통해 학습.
- 최종 분류기 학습 수식:
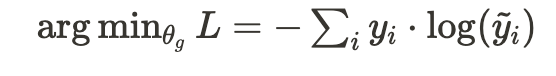
- 여기서 는 실제 라벨, 는 예측된 라벨.
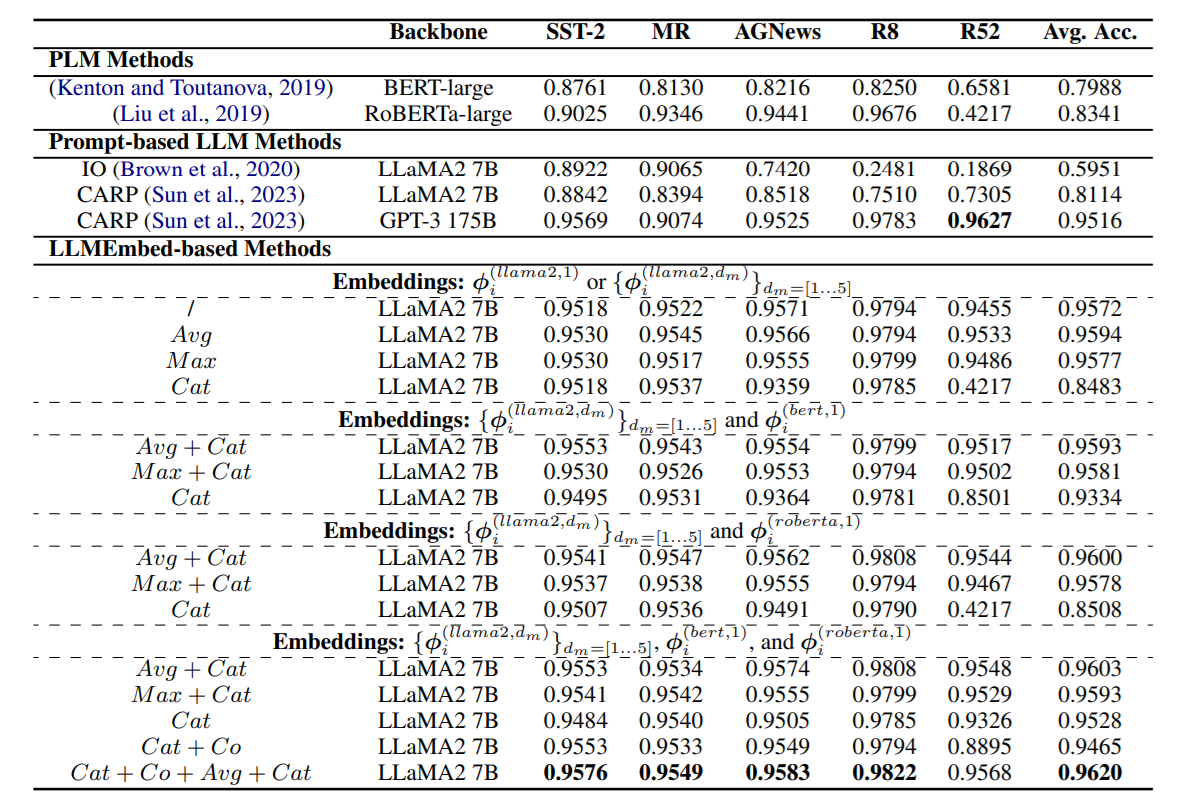
3. 실험 결과

GDG Gachon Ai 스터디입니다.