
1.Abstract

스테레오 이미지의 경우 지역적인 정보만으로 깊이 추정이 가능하지만 Monocular와 같은 경우 더 다양한 단서로부터 전역, 지역적인 정보를 통합해야 하므로 더 어렵다.
따라서 이 논문에서는 두개의 deep network를 사용하여 이러한 문제를 해결하였고, 스케일 자체보다 깊이 관계를 측정하기 위한 Loss함수를 제시했다.
2. Related Work
Depth Estimation은 크게 두가지 방식으로 나뉜다.
-
Stereo
사람의 눈과 유사하게 여러 개의 카메라를 사용하여 이미지를 획득하고, 깊이 정보를 계산하는 방식이다. 두 이미지간의 시차를 분석해서 거리를 추정하는 방식이다. -
Monocular
하나의 카메라로 촬영한 이미지를 분석해서 깊이 정보를 추정한다. 이미지 내의 단서(원근, 그림자, 텍스처 변화, 물체 크기 변화 등)를 활용해서 깊이를 유추한다.
stereo이미지보다 monocular 이미지가 압도적으로 많으므로 monocular에서 깊이 정보를 추출하는 기술은 더 많은 분야에 사용될 수 있을것이다.
1. stereo depth estimation

동일한 장면을 다른 각도에서 촬영한 두 개의 이미지에서 픽셀 간의 변위를 계산하여 깊이를 추정하는 방법이다. 이는 기하학적 원리이를 이용한 것이고 정확한 카메라 정보를 필요로 하며 계산량이 많다는 단점이 있다.
2. Monocular depth estimation
초기 연구에서는 선의 각도, 소실점, 객체 크기, 대기 효과와 같은 깊이 단서를 이용하여 깊이를 추정함. 그러나 이런 방법은 복잡한 장면에서는 성능이 나오지 않는다.
3. Approach
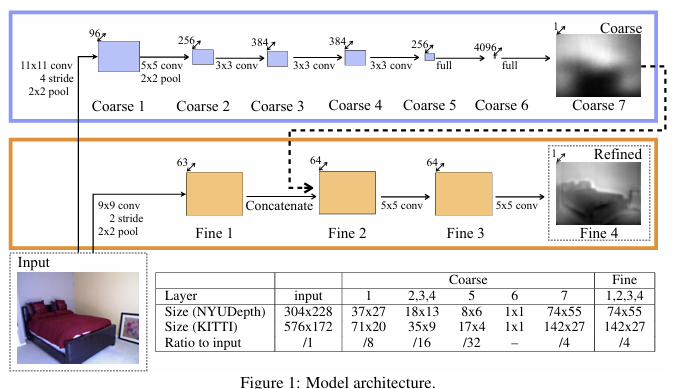
이 논문에서는 Monocular depth estimation을 위해서 두 개의 딥러닝 네트워크를 사용하는 방법을 제시하였다. 위 그림에서 위의 부분이 Global Coarse-Scale Network이고 아래 부분이 Local Fine-Scale Network이다.
1.Global Coarse-Scale Network
이미지 전체를 보고 장면의 대략적인 깊이 구조를 파악하는 네트워크. 여러개의 Conv layer와 max pooling layer를 통해 이미지의 특징을 추출한다.
Conv layer는 이미지의 지역적인 특징을 추출하고, max pooling layer는 중요한 특징을 강조하면서 정보의 차원을 줄이는 역할을 합니다.
마지막에는 fully connected layer를 사용하여 전체 이미지의 정보를 통합하고 대략적인 Depth Map을 예측함으로써 이미지의 전체 정보를 활용하여 전역적인 깊이 단서를 학습합니다.
2. Local Fine-Scale Network
Global Coarse-Scale Network의 예측 결과를 바탕으로 각 픽셀의 깊이 값을 정확하게 조정한다.
Global Coarse-Scale Network의 출력을 저해상도의 depth map으로 입력받아 고해상도 depth map을 예측한다. Global Coarse-Scale Network의 출력뿐만 아니라 원본 이미지 정보도 함꼐 입력받아서 지역적인 깊이 단서까지 활용한다.
이를 통해 객체 경계, 모서리, 세부적인 깊이 변화 등을 더 정확하게 예측할 수 있다.
3. Scale-Invariant Error

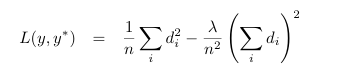
monocular depth estimation에서는 실제 깊이 값을 정확히 예측하기 어렵다. 같은 이미지라도 카메라와의 거리에 따라 실제 깊이 값은 달라질 수 있다는 문제가 있다.
따라서 픽셀 간의 상대적인 깊이 관계에 집중해서 학습하여 전역적인 스케일에서 불변하는 오류 함수를 사용함으로써 깊이 추정의 안정성을 높이고 좀 더 현실적인 depth map을 예측할 수 있다.
예측값이 y와 ground truth값인 y 값의 차이를 통해 loss를 계산하는데 이때 모든 i값에 대한 ground truth와의 차이를 평균을 낸 a값을 더하면서 scale을 보정해주었다.
(y는 예측값, y는 ground truth 값)
밑에 있는 2, 3 식은 실제로 논문에서 사용하지는 않았지만 두가지 픽셀간의 상관관계에 대한 로스 함수이다. 3번식에서 앞부분은 L2 loss 형태이고 두번째 식은 깊이 차이의 방향을 고려하는 항이다.
따라서 training에서는 아래 이미지에서 사용되는 함수를 사용했는데 이는 위의 loss를 사용해서 lamda가 0일때는 L2 loss, 1일때는 scale-variant loss이다. 이때 lamda를 0.5로 사용하면 출력이 약간 개선되는 것을 발견했다.
4. Data Augmentation
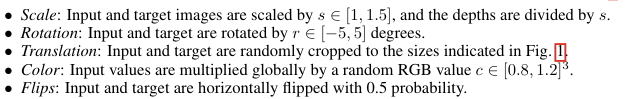
데이터 양을 늘리고 다양한 환경에 대한 일반화 성능을 높이기 위해 이미지 스케일링, 회전, 이동, 색상 변환, 뒤집기 등의 데이터 증강 기법을 사용했습니다.
4. Results
1.NYU Depth
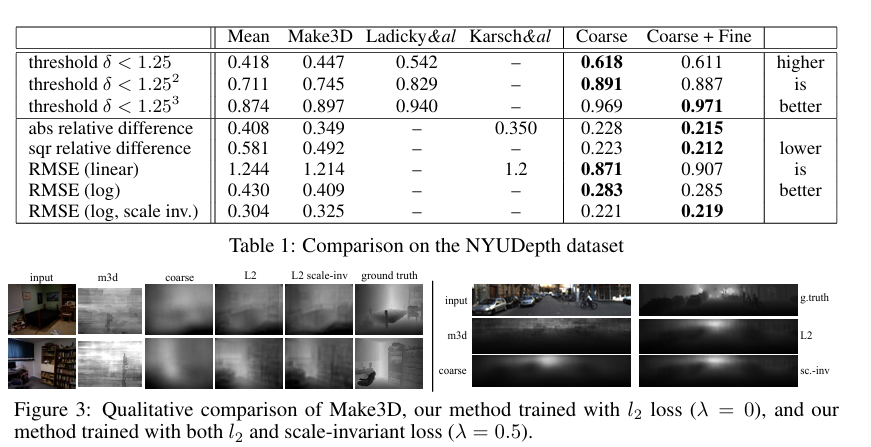
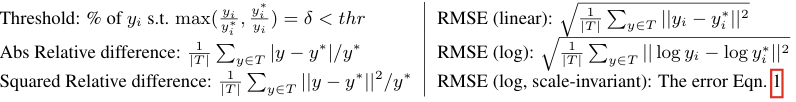
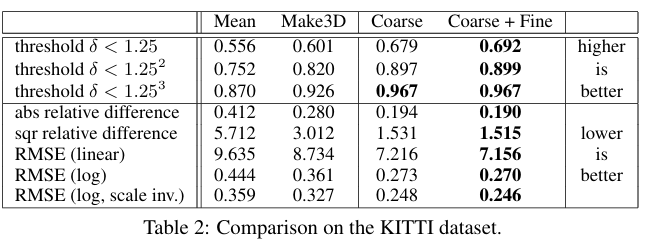
2. KITTI
5. After
coarse-fine network는 향후 'BERT for Spatial Reasoning in Monocular Depth Estimation'에서 자연어 처리 분야에서 널리 사용되는 BERT 모델을 깊이 예측에 적용했다. 이미지의 Contextual 정보를 효과적으로 추출하고, self-attention 메커니즘을 통해 픽셀 간의 관계를 모델링하여 정확도를 높였습니다.
또한 scale-invariant error 또한 image depth estimation에서 사용되고 있다.
모델 코드:
https://github.com/imran3180/depth-map-prediction/blob/master/model.py
