개요
Chomsky를 포함한 여러 이론가들은 대형 언어 모델(LLMs)이 가능한 인간 언어와 불가능한 언어를 동일하게 학습할 수 있다고 주장하였음. 이 주장은 언어 모델이 언어학 연구에서 유효한 도구가 되지 못한다는 결론을 뒷받침하는데, 본 논문에서는 이러한 주장의 타당성을 실험적으로 검토하고자 함. 연구팀은 인간에게 불가능한 것으로 간주되는 여러 유형의 인공 언어를 설계하고, 이 언어들을 GPT-2 모델이 학습할 수 있는지 조사함으로써 이론을 검증하고자 함.
연구 배경
- 불가능한 언어 개념: 논문에서는 언어학적으로 불가능하다고 여겨지는 규칙을 사용해 불가능한 언어를 설계하였고, 이들 불가능한 언어와 가능한 언어 사이에 "불가능성 연속체(impossibility continuum)" 개념을 제시함으로써 언어의 복잡성과 학습 가능성을 평가하고자 함.
- 연구 질문: LLM이 가능한 언어와 불가능한 언어를 동일한 수준으로 학습할 수 있는가? 인간이 학습하지 못하는 언어의 규칙을 GPT-2가 학습할 수 있는가?
방법론
연구팀은 세 가지 실험을 통해 GPT-2의 학습 방식을 비교함으로써 LLM이 불가능한 언어 규칙을 학습할 수 있는지 조사하였음.
-
불가능한 언어 세트 생성 및 학습 실험
- 연구팀은 불가능한 언어를 세 가지 주요 카테고리로 정의하고 각각의 언어를 학습시키는 실험을 수행함.
- SHUFFLE 언어: 문장의 단어 순서를 무작위로 섞는 언어.
- REVERSE 언어: 문장을 전체 혹은 부분적으로 반전시키는 언어.
- HOP 언어: 동사의 수식어 위치를 특정 규칙에 따라 변경하는 언어.
- 각각의 언어를 학습하는 모델의 효율성을 테스트셋의 퍼플렉시티 (모델이 다음 단어를 얼마나 잘 예측할 수 있는지를 수치화한 값) 를 통해 평가함.
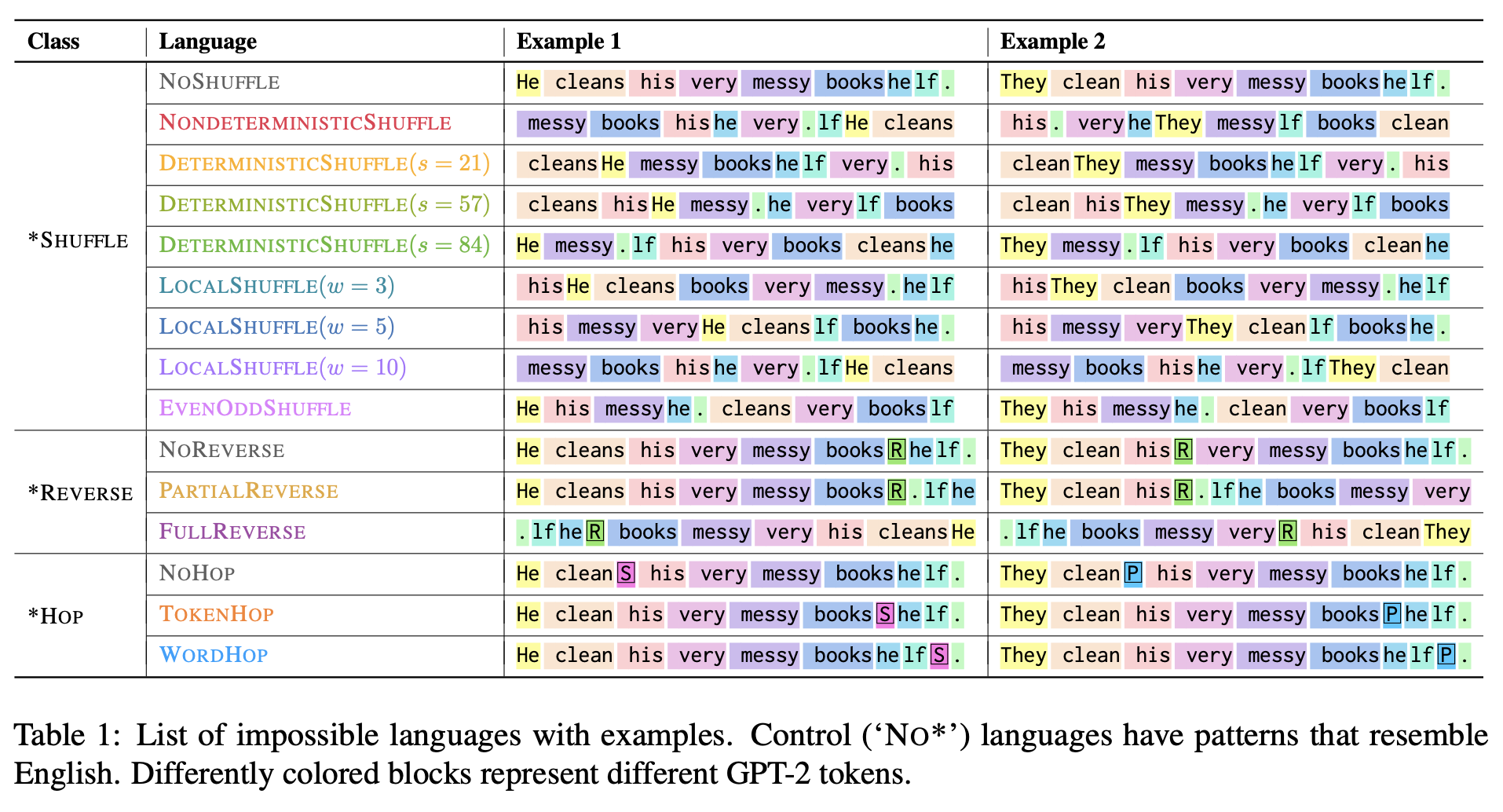
- 연구팀은 불가능한 언어를 세 가지 주요 카테고리로 정의하고 각각의 언어를 학습시키는 실험을 수행함.
-
서프라이즈(Surprisal) 테스트
- 모델이 불가능한 언어 규칙을 적용했을 때 특정 토큰의 위치를 얼마나 잘 예측하는지 확인하기 위해 서프라이즈 값을 계산함.
- 모델이 가능한 언어와 불가능한 언어에서 예측하는 방식을 비교함으로써 불가능한 언어 규칙의 학습이 어려웠음을 확인함.
-
내부 메커니즘 분석
- "인과 추론 분석(Causal Abstraction Analysis)"을 통해 모델이 특정 문법 규칙을 학습할 때 사용하는 내부 메커니즘을 조사함.
- 모델이 불가능한 언어 규칙을 학습할 때 복잡한 내부 메커니즘을 만들어내야 했음을 확인함.
실험 결과
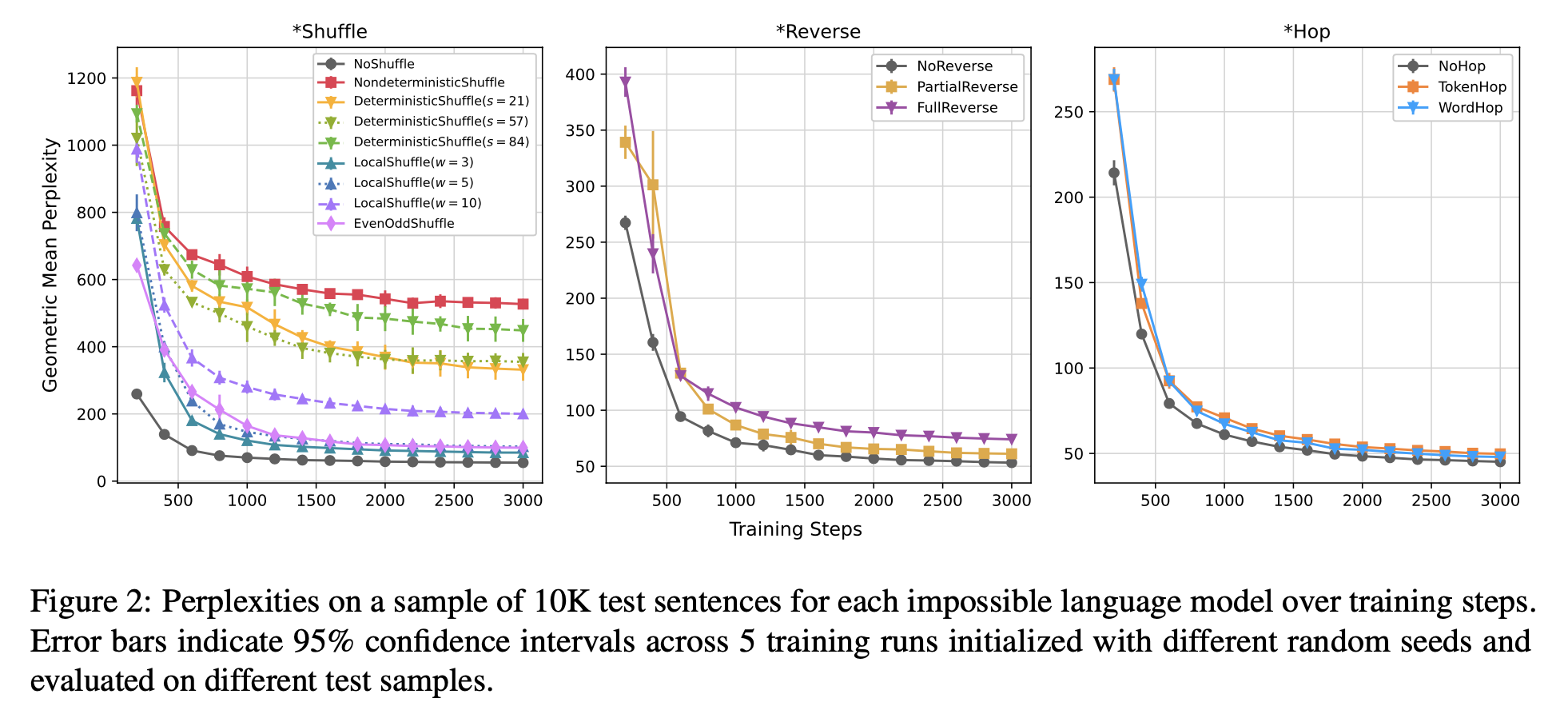
- 학습 효율성: 가능한 언어(자연어)에서 GPT-2 모델이 불가능한 언어보다 더 효율적으로 학습하였으며, 이는 퍼플렉서티와 학습 속도에서 뚜렷하게 드러남.
- 서프라이즈 테스트: 가능한 언어에서는 예상 위치에 토큰이 올 가능성이 높았으나, 불가능한 언어 규칙에서는 높은 서프라이즈 값을 보여 예측이 어려웠음을 확인함.
- 내부 메커니즘 분석: 가능한 언어 규칙의 경우 적은 계층(layer)과 단순한 메커니즘으로 예측할 수 있었으나, 불가능한 언어 규칙의 경우 복잡한 내부 메커니즘을 통해 학습해야 했음.
결론 및 시사점
이 연구는 LLM이 불가능한 언어를 인간 언어와 동일하게 학습할 수 없음을 입증하며, 기존 이론가들의 주장에 대한 도전 과제를 제시함. 또한, LLM이 언어 연구에서 유용한 도구가 될 수 있는 가능성을 보여주었으며, 모델의 학습 방식이 인간의 언어 학습과 어떻게 다른지에 대한 시사점을 제공함.

GDG Gachon Ai 스터디입니다.