
1.Background
YOLOv1
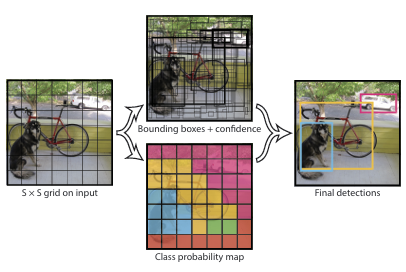
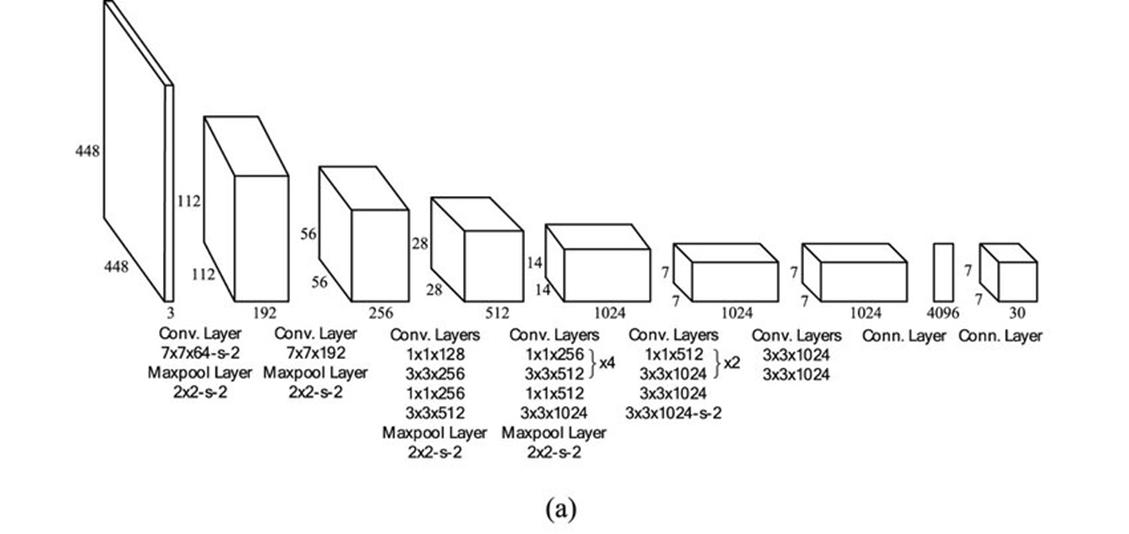
YOLOv1은 객체 감지를 단일 회귀 문제로 접근하였다.
기존의 방식에서는 이미지에서 객체가 있을 만한 영역을 찾고 영역을 분류해서 Bounding Box와 Class를 분류했었다. 그러나 YOLOv1에서는 이 과정을 동시에 진행하면서 두개의 네트워크를 사용하던 기존의 방식에서 하나의 네트워크를 사용하는 방식으로 바꿈으로써 더 빠른 속도를 가지게 되었다.
YOLOv1의 더 빠른 속도는 동영상과 같은 계속해서 객체의 위치나 라벨이 바뀌는 상황에서 유용하게 사용할 수 있도록 해주었다.
CSP(Cross Stage Partial Connections)
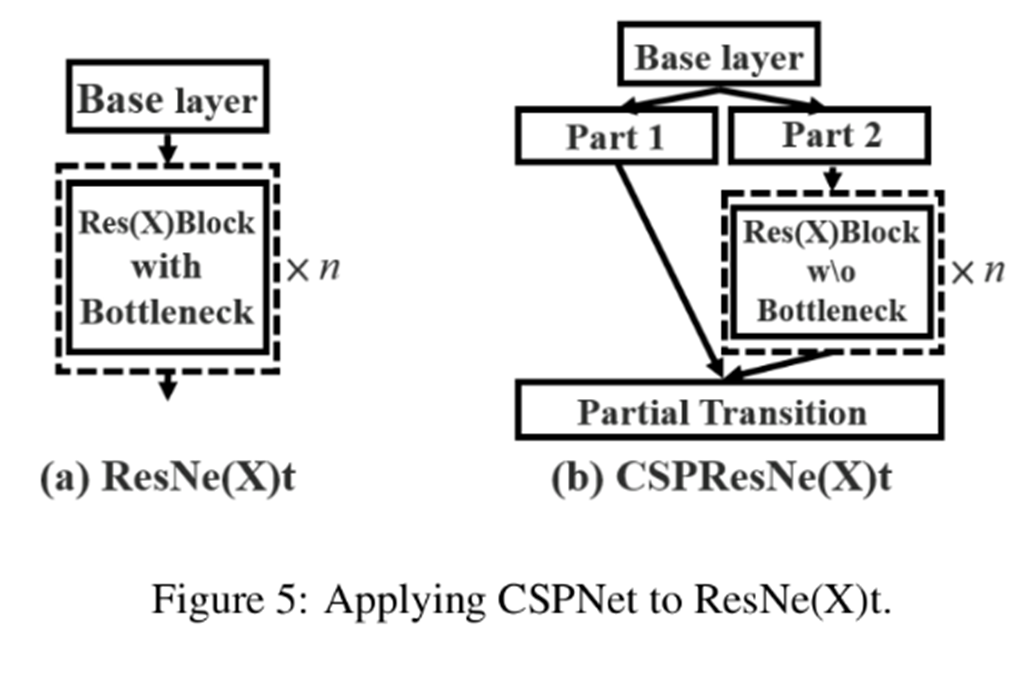
CSP는 네트워크의 앞부분에서 feature map을 두 부분으로 나누고 한 부분만 연산에 활용하고 나머지는 뒤에서 합치는 방식으로, 연산량을 줄임과 동시에 정보를 유지 할 수 있도록 했다.
위 그림에서 Part1 부분은 연산에 활용하지 않고 합치는 방식으로 정보를 유지할 수 있도록 했는데, ResNet의 Skip-Connection과 구조는 다르지만 비슷한 원리이지 않을까 생각한다.
SPPF(Spatial Pyramid Pooling-Fast)
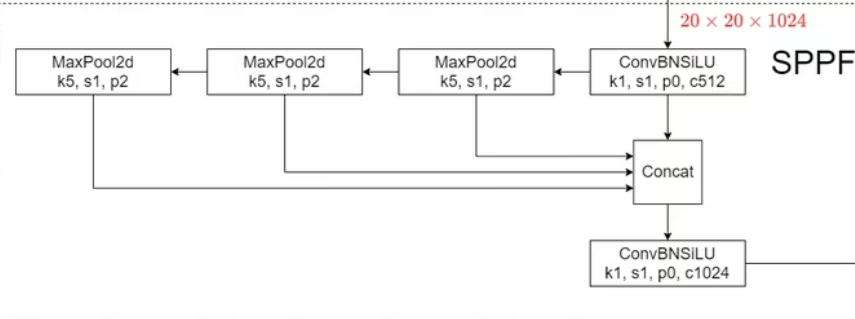
위 그림은 YOLOv5에서 사용되는 구조를 나타낸 건데, 이러한 방식이 YOLOv8에서도 사용되었다.
Feature map을 여러 번 pooling하여 다양한 스케일의 정보가 포함되도록 하며, ConvBNSiLU과정을 통해서 채널수를 조정해준다.
이를 통해 Inputdml 크기를 고정하지 않고 다양한 크기의 Input이미지를 처리할 수 있도록 하며, Input을 왜곡하거나 자를 필요 없이 수용할 수 있게 한다.
SiLU
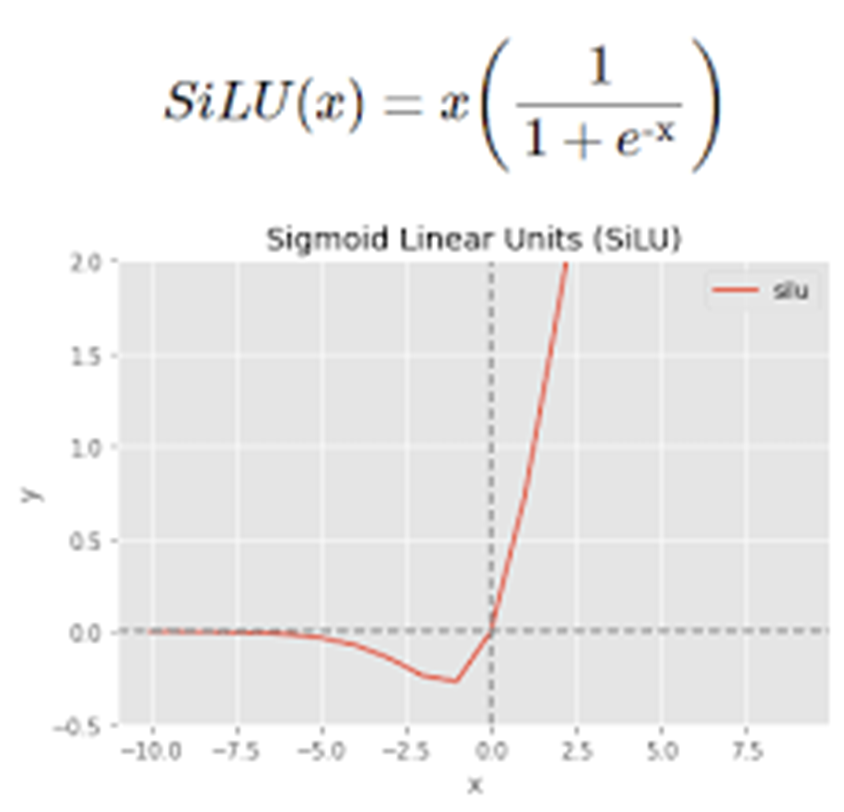
YOLO에서는 위와 같이 sigmoid 함수에 x값을 곱한 형태의 활성화함수를 사용한다. ReLU함수보다 부드러운 형태이며 음수에서의 값 또한 ReLU와 달리 0이 아니기에 gradient vanishing 문제를 완화하는데 효과적이다.
Others
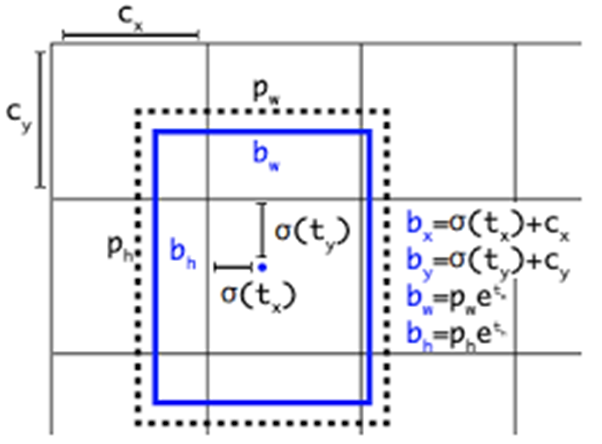
그 외에도 기존에 Anchor Box를 수동으로 설정해야 했던것과 달리 YOLOv8에서는 객체의 중심점과 크기를 직접 예측하는 Anchor Free Detection도 사용되었다.
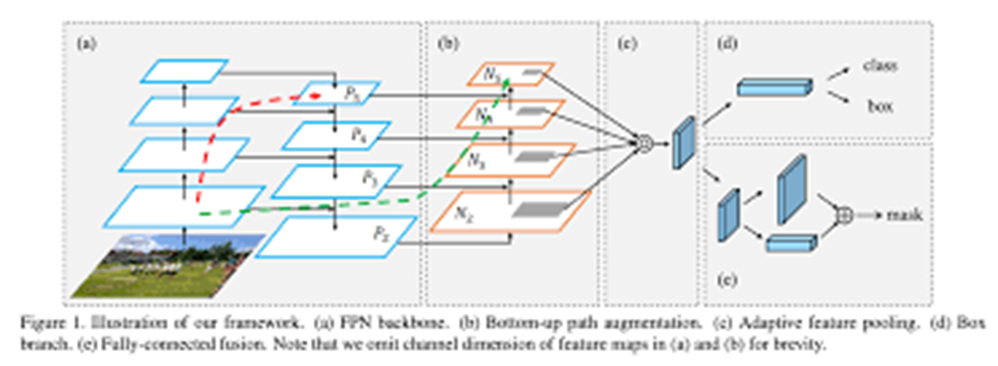
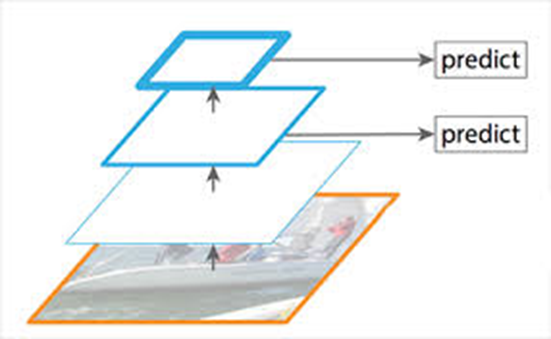
또한 FPN과 PANet을 사용해서 High level feature과 Low level Feature를 효과적으로 합칠 수 있도록 하였다.
Architecture
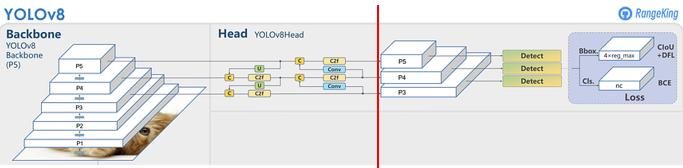
전체 구조를 먼저 살펴보면 Backbone과 Head로 구성되어 있다. Backbone과 Head로 구성되어 있으며, backbone에서는 input데이터의 feature를 추출하고, head에서는 추출한 feature를 이용해서 classification, detection과 같은 task를 수행한다.
아래에서 설명할 때는 빨간 선을 기준으로 앞부분은 neck, 뒷부분을 head로 표현한다.

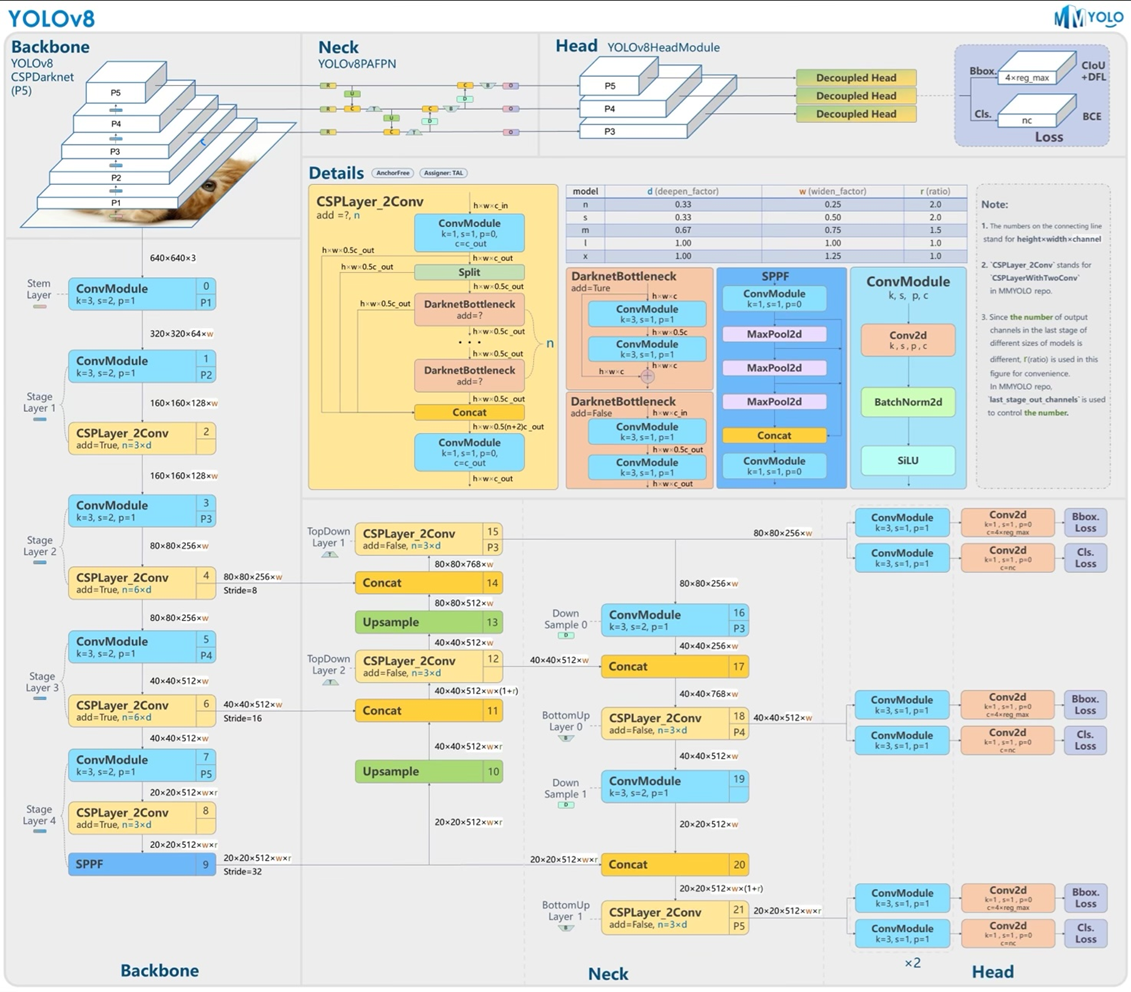
Backbone
먼저 위 표는 YOLOv8 모델을 크기에 따라 분류하고 각 모델에 따른 d,w,r을 설정하는 표이다. 아래로 가면서 모델의 크기가 더 커지고, 이와 같은 모델은 YOLOv8n과 같은 형태로 표시한다.
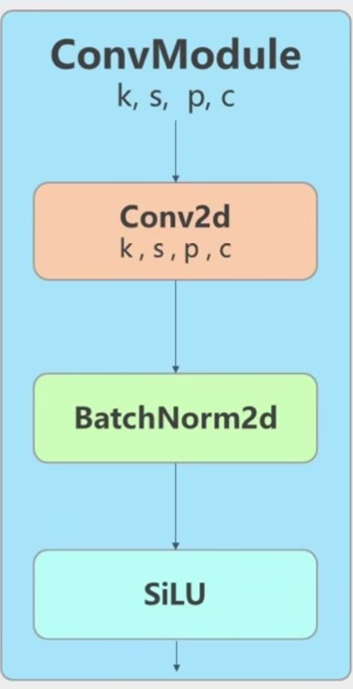
먼저 위 모델에서 사용되는 ConvModule은 Conv-BatchNorm-SiLU와 같은 구조를 사용하고 있다.
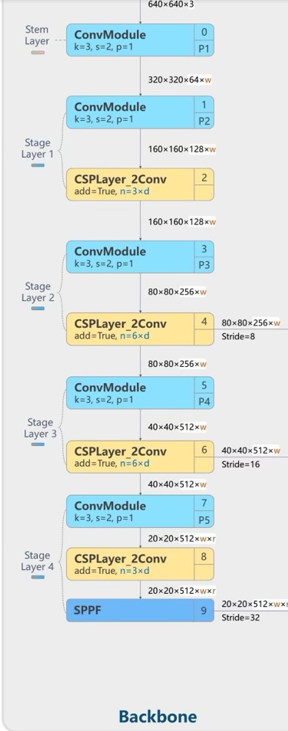
위 구조는 Backbone구조를 나타낸 부분의 그림이다. P1은 ConvMoudle하나로 구성되어 있고, P2, P3, P4는 ConvModule-CSPLayer_2Conv(C2F)로 구성되어 있으며 P5는 이런 모델에서 SPPF모델이 추가된 형태이다.
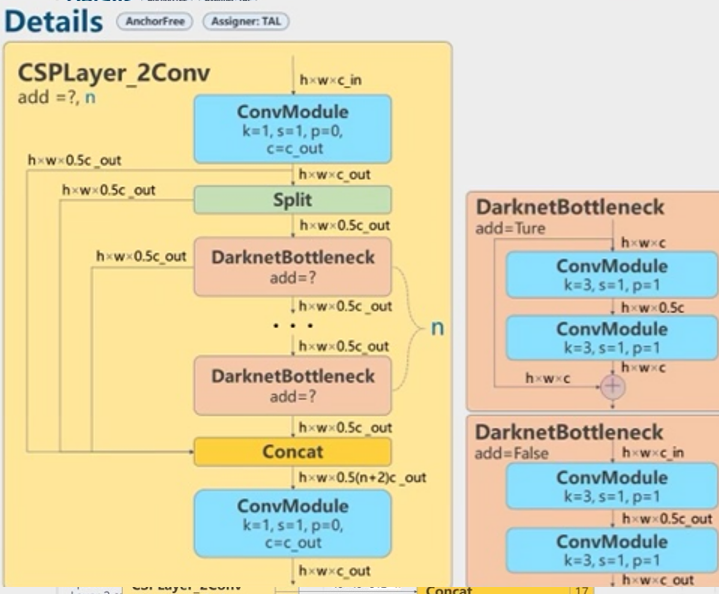
그러면 ConvModule-CSPLayer_2Conv(C2F)이 뭐냐하면 위에서 설명한 CSP를 적용해서 연산량을 줄이면서 정보를 유지하는 방식을 사용했다.
Backbone구조를 보면 각 레이어에 있는 n, add의 boolean값을 가지고 bottleneck레이어의 개수와 bottleneck의 skip-connection의 유무를 정해준다.
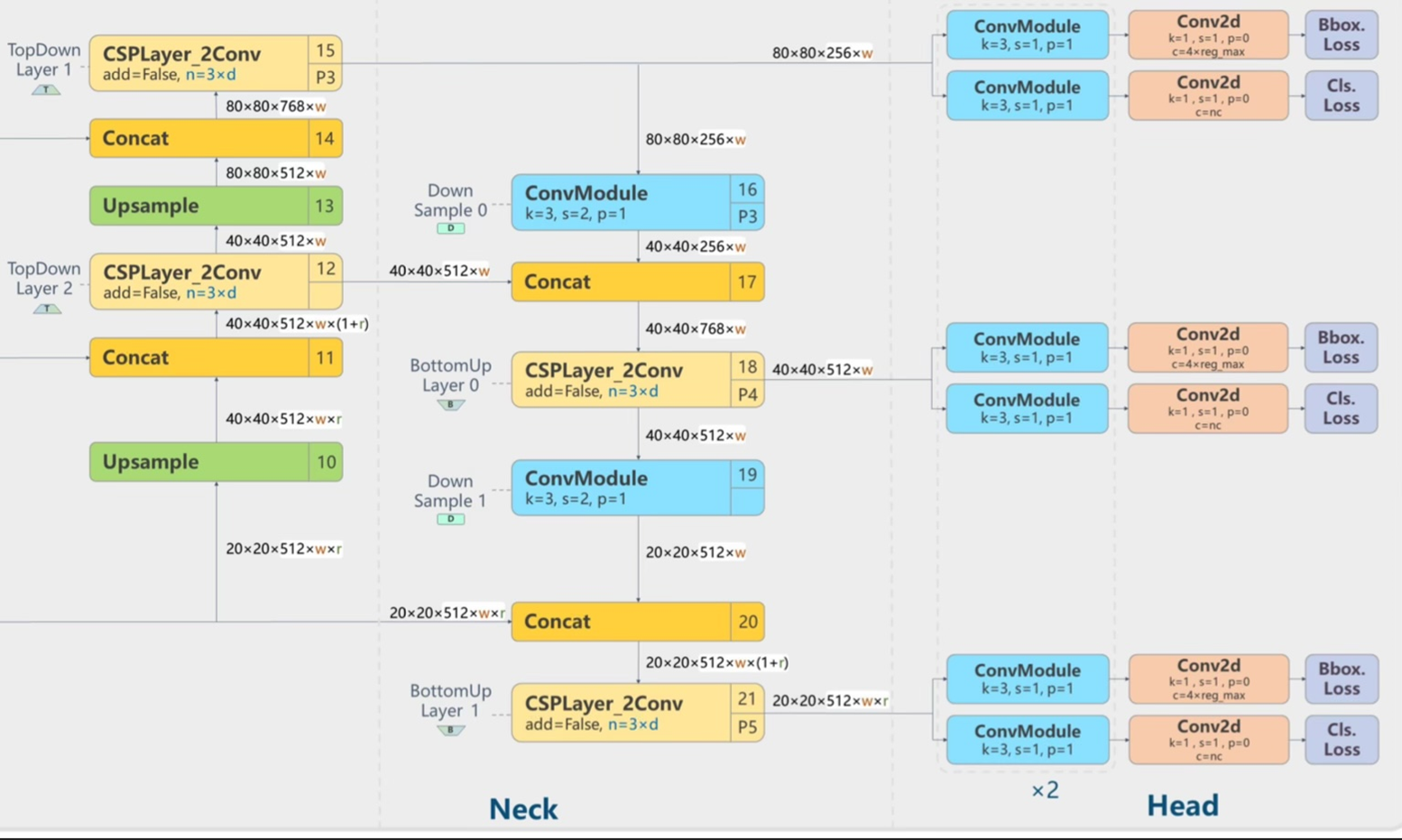
Neck부분에서 가장 왼쪽부분에서 데이터가 들어가는 부분은 위에서부터 backbone의 P3,P4,P5에서 나오는 부분이다. 가장 아래의 branch
가장 아래의 branc는 sppf를 통해서 나온 p5의 정보, 그리고 위의 c2f는 각각 p4, p3이다.
Neck 구조에서 Upsampling과 Downsampling을 통해서 종합된 정보들은 head부분으로 전달되어 ConvModule 두번과 convlayer를 통해서 loss가 bounding box와 class에 대한 loss가 도출된다. Downsample을 할 때 pooling을 사용하지 않고 convmodule을 사용한 이유는 학습이 가능한 커널을 사용하기 위해서 사용했다고 생각한다.
P3,4,5의 head는 서로 다른 스케일의 객체를 담당하여 예측작업을 수행한다.
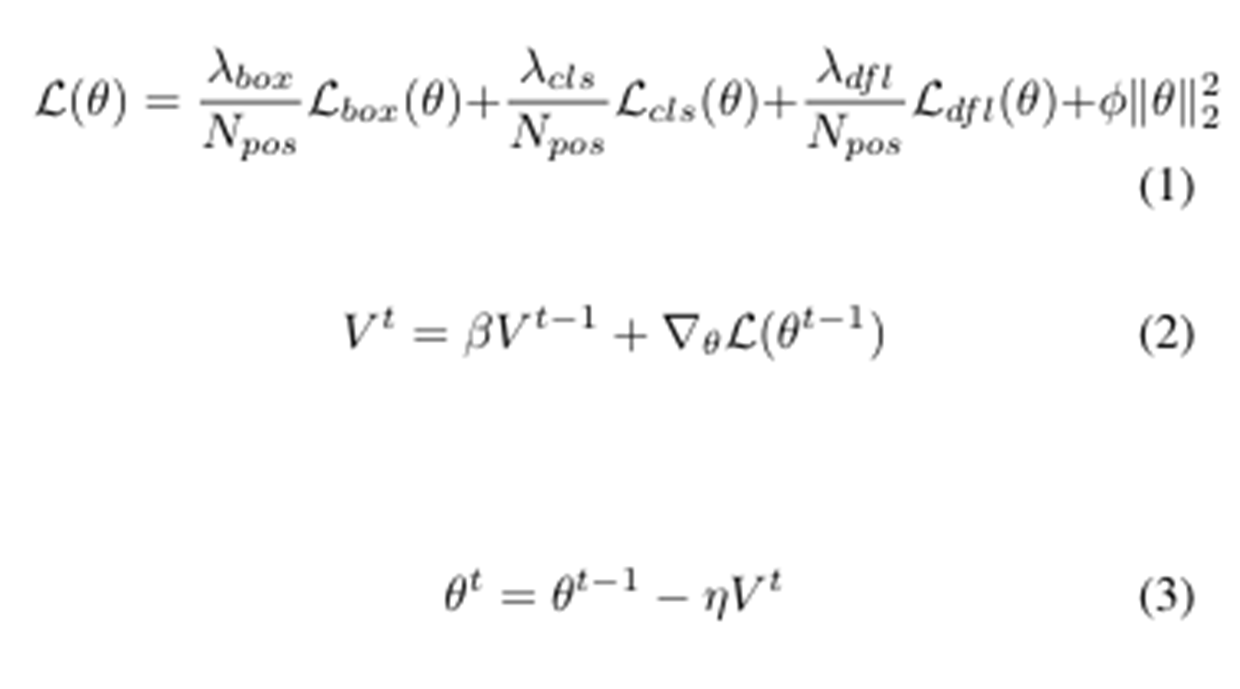
Box loss, Class loss, dfl loss를 모두 더한 것이 YOLOv8의 loss function이다.
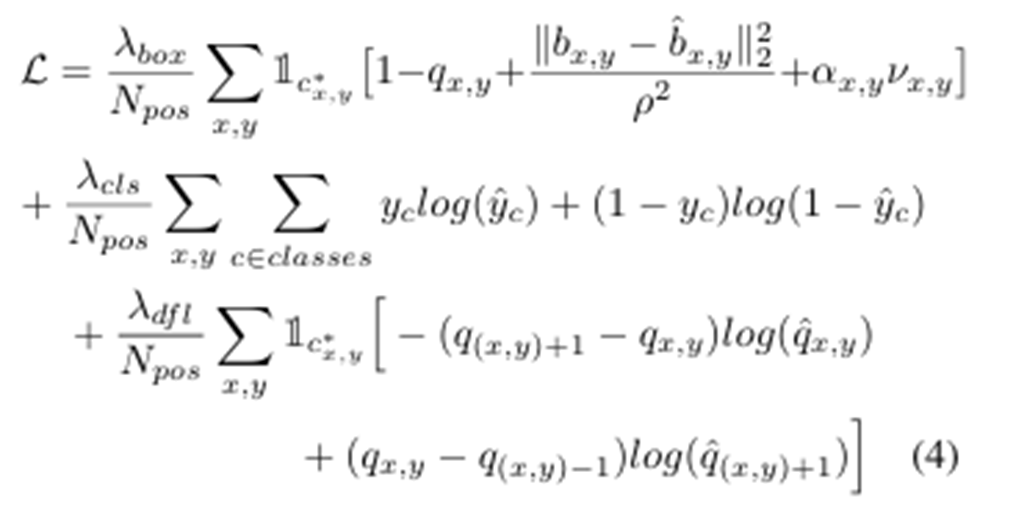
Box loss는 IOU와 bounding box의 중심점의 차이와 바운딩 박스 위치 예측의 불확실성에 대한 가중치 a와 실제와 예측 바운딩 박스의 가로 세율의 비율의 차이에 대한 v를 곱한 term을 사용하며 loss를 구한다.
Class loss는 일반적으로 logistic regression에서 사용하는 log를 사용하는 loss function이다.
dlf loss는 더 정밀한 위치 예측을 위해서 사용되며, 좌표를 단일값으로 표현하기 보다 분포 형태로 확률에 따른 예측한다.
Experiment
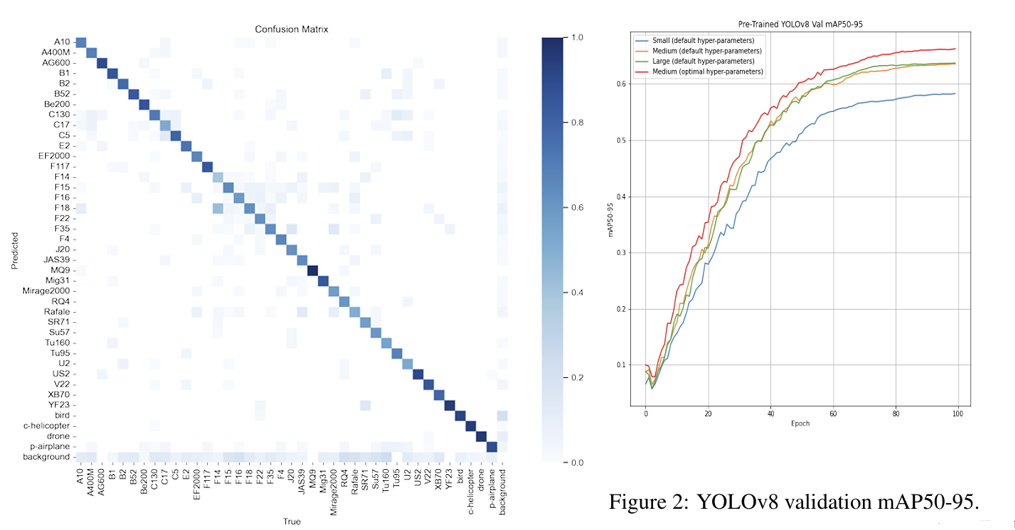
위 사진은 비행물체 탐지에 대해서 YOLOv8을 적용한 결과를 나타낸 Confusion Matrix와 Small, Medium, Large그리고 파라미터를 조정한 Medium의 모델에 대한 성능 차이를 나타낸 그래프이다


위 이미지들은 전투기와 드론을 탐지한 이미지이다. 제일 왼쪽은 원본, Input이미지이고, 오른쪽으로 순서대로 backbone에서의 P2,3,4,5에서의 Feature map이다. 레이어가 얕은 부분에서는 모서리, 질감과 같은 특징을 감지하고 레이어가 깊어질수록 전반적인 형태, 위치와 같은 좀 더 세밀한 특징이 나타난다.

일반화된 모델을 적용한 결과이다. 아주 작은 수준의 객체도 좋은 성능으로 탐지하는 것을 볼 수 있다.
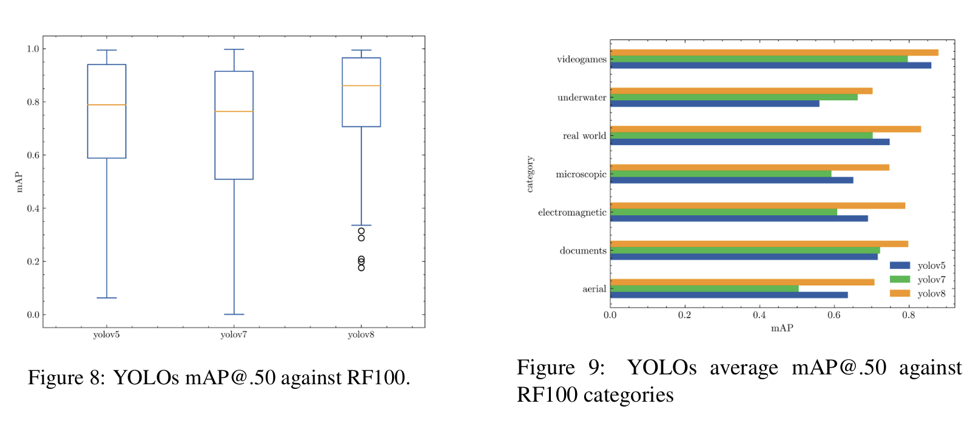
RF100은 100가지의 다양한 클래스의 객체를 포함하는 데이터셋으로 Box Plot과 mAP를 성능지표로 하여 보여주는 그래프이다. 이전 YOLO버전보다 더 나은 성능을 보이는 것을 확인 할 수 있다.
따라서 YOLOv8은 이전 버전의 장점을 이어받으면서 Anchor free detection이나 구조를 개선하여 사용하면서 성능을 향상 시켰다.
참고 문헌
https://docs.ultralytics.com/ko/yolov5/tutorials/architecture_description/#1-model-structure
https://sh-tsang.medium.com/brief-review-real-time-flying-object-detection-with-yolov8-6a2a630ffb99
