

- TabNet: Tabular 데이터 학습을 위한 새로운 딥러닝 아키텍처
- Sequential attention: 각 결정 단계에서 활용할 feature을 선택
- 학습 효율성: 딥러닝 모델이 중요한 특징에 학습 자원을 집중
- 해석 가능성: 모델의 의사결정을 로컬(개별 샘플) 및 글로벌(모델 전체) 수준에서 해석
- 비지도 학습(self-supervised learning): 라벨이 부족한 데이터 환경에서 성능 향상
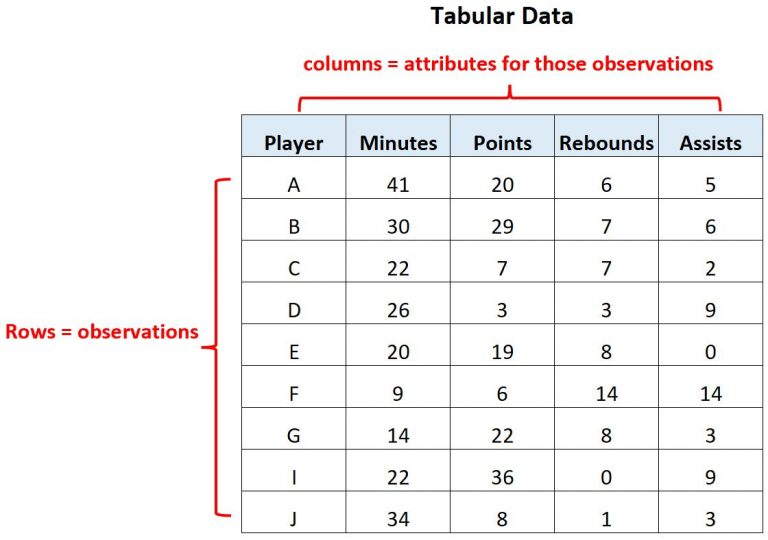
tabluar 데이터
데이터가 행(row)와 열(column)로 구성된 표 형태의 데이터 (정형 데이터)
1. Introduction
기존 딥러닝 모델은 이미지, 텍스트, 음성 데이터에서는 성공을 거두었지만, tabular 데이터에서는 여전히 결정 트리(Decision Trees, DTs) 기반의 모델이 여전히 주류를 이룬다.
왜 정형 데이터에서 DNN보다 DT-based 접근을 선호할까?
- 초평면(hyperplane) 결정 경계를 가지며, 정형 데이터의 특성에 잘 맞다.
*초평면: 데이터를 분리하는 경계면
예: "연봉 5,000만원 이상이면 승인"이라는 규칙처럼 데이터를 간단히 나누는 방식 - 규칙 기반이므로 모델 및 추론 결과에 대한 해석이 용이하다.
- 학습 속도가 빠르다.
반면, DNN은 정형 데이터에 사용하기엔 파라미터가 지나치게 많고, 적합한 inductive bias(귀납 편향) 설계가 어려워 종종 최적해 탐색에 실패하기 때문에 기피되는 경향이 많다. 즉, 결정 트리처럼 "단순한 규칙"을 학습하지 못하고, 필요 없는 복잡한 패턴까지 학습할 가능성이 크다.
그렇다면, DNN의 장점은?
위의 단점에도 불구하고, DNN은 다음의 이점이 있다.
- 정형 데이터와 함께 이미지와 같은 비정형 데이터를 효과적으로 인코딩할 수 있다.
- DT-based 모델과 마찬가지로 feature engineering 과정을 경감시킨다.
- Domain adaptation(도메인 적응), generative modeling(생성 모델링), semi-supervised learning 같은 다양한 시도가 가능하다.
TabNet
TabNet은 정형 데이터에서 DT-based 모델과 DNN의 장점을 계승했다.
- Sequential attention을 사용하여 feature 선택의 이유를 추적할 수 있게 하여 interpretability(해석 가능성)를 확보했다.
- 회귀와 분류와 같은 다양한 데이터셋에서도 높은 성능을 보인다.
- 정형 데이터셋에서 처음으로 비정형 사전학습(unsupervised pre-training)이 성능을 크게 향상시킬 수 있음을 보였다. 이는 기존 DT-based 모델에서는 불가능했던 새로운 접근이다.
2. TabNet for Tabular Learning
TabNet은 Encoder와 Decoder로 구성되어 있다.
2-1. Feature Transformer
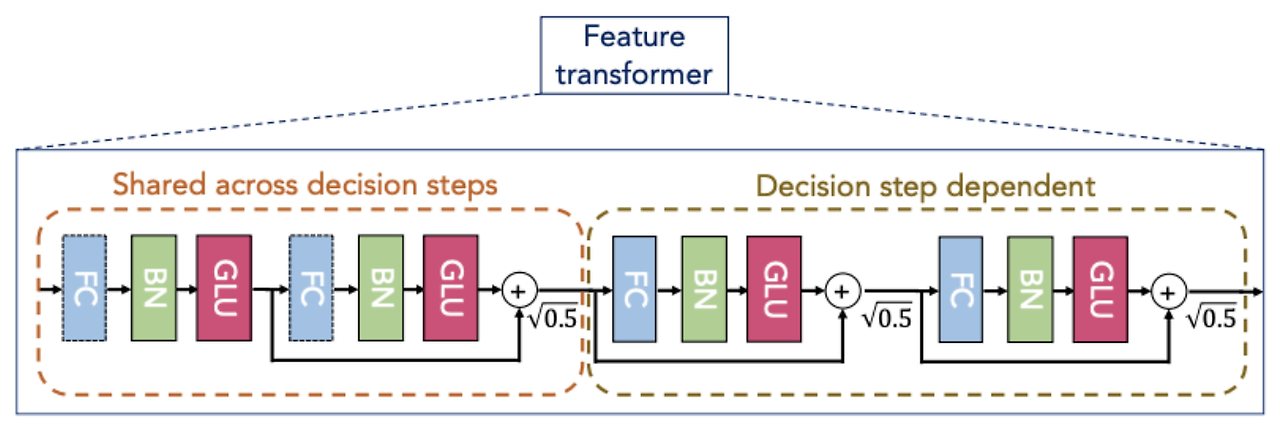
Feature Transformer는 FC, BN, GLU 등으로 구성되어 연산을 수행하며, 두 가지 중요한 정보를 출력하는 모듈이다.
-
최종 Output으로 전달할 정보 (최종 출력 정보)
- Decision step dependent 부분에서 추출된 정보는 최종 Output으로 '전달'할 정보
-
다음 스텝으로 전달할 정보 (공유 정보)
-
Shared across decision steps 부분에서 출력된 이 정보는 다음 Decision Step으로 전달됨
-
앞선 스텝에서 어떤 특성들이 이미 연산되었는지에 대한 정보를 제공하여, 다음 스텝이 새로운 특성에 집중할 수 있도록 도움. 이는 TabNet이 스텝별로 다른 특성에 초점을 맞추는 연산을 가능하게 함
-
GLU (Gated Linear Unit)
1. 선형 변환
- 먼저, 입력 벡터 x에 대해 두 개의 선형 변환을 수행
- 게이팅 (Gating)
- 두 번째 변환에 시그모이드 활성화 함수를 적용하여 게이트 값을 구함
- 이 때, 시그모이드는 0과 1 사이의 값으로 각 요소가 얼마나 "열릴지"를 결정
- 최종 출력
- 첫 번째 변환과 게이트 값을 곱한 후 더하므로써 요소별 곱을 취함으로써, 중요한 정보만을 선택하고 불필요한 정보를 걸러냄


2-2. Attentive Transformer
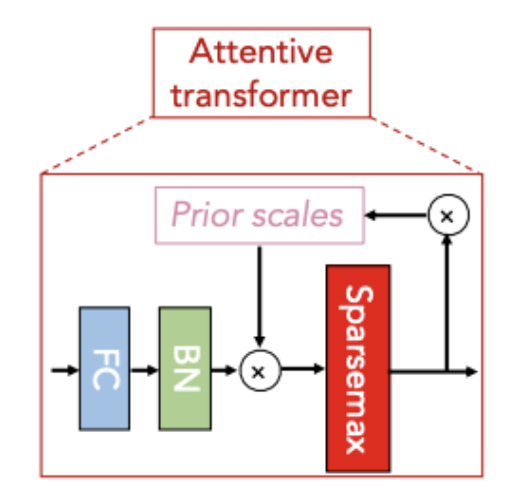
Attentive Transformer는 Feature Transformer로 부터 받은 데이터에 대해 Attention Map을 출력해주는 역할을 하며, 이번 스텝에서는 어떤 정보에 초점을 맞출 것인지만 결정하는 역할을 한다.
-
입력 데이터를 처리하기 위해 FC와 BN을 적용
-
Prior Scales를 사용하여 이전 단계에서 선택되지 않은 특성의 중요도를 점차 감소시켜 새로운 특성을 탐색하도록 유도
-
Sparsemax는 희소성이 높은 Attention 분포를 생성하여 중요한 특성만 선택하며, 선택 결과는 Prior Scales를 갱신하여 다음 단계로 전달
*희소성(Sparsity): 많은 값이 0인 상태로, 소수의 값만 활성화되는 특성
이 과정에서 Prior Scales는 중복된 특성 선택을 방지하고, Sparsemax는 중요한 특성만 선택하도록 설계되어 TabNet의 특성 선택이 효율적이고 해석 가능하도록 만든다.
Sparsemax
확률 분포를 생성하는 함수로, softmax와 유사하지만, 차이점은 출력값 중 일부를 0으로 만드는 기능을 한다는 것
Softmax vs. Sparsemax
- Softmax는 모든 출력값이 0~1 사이이며, 중요하지 않은 값도 완전히 0이 되지 않으므로, 모든 특성에 영향일 미칠 수 있음
- Sparesmax는 일부 출력값을 0으로 만들어, 모델이 중요한 특성에 더 집중하게 하고, 나머지 특성들은 무시
2-3. ENCODER
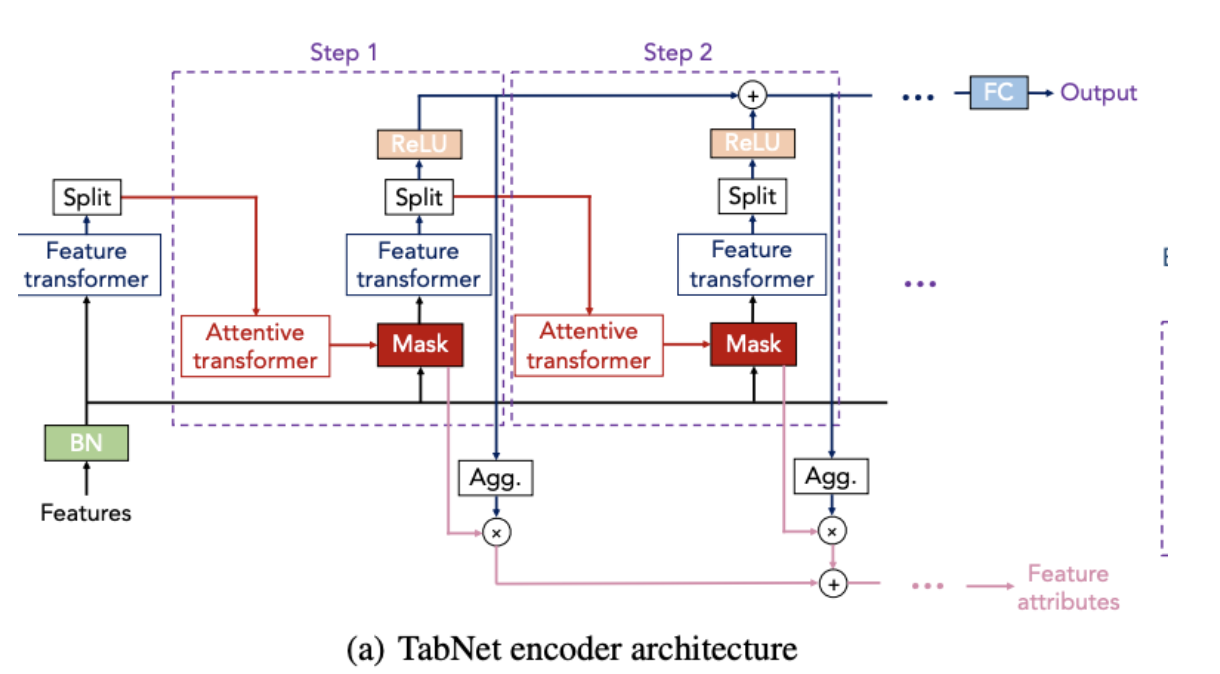
Encoder는 데이터를 입력받아 풀고자 하는 문제에 맞도록 데이터를 재구성한다.
-
입력 처리
- 입력된 Feature는 Batch Normalization(BN)을 통해 정규화
-
Feature Transformer
- 입력 데이터를 변환하여 Feature 표현을 학습
- Feature Transformer의 출력은 두 부분으로 나뉨(Split):
1. Attentive Transformer로 전달
2. 특성 변환 결과로 사용
-
Attentive Transformer
- 어떤 정보가 중요한지 판단하고, 다음 단계에서 사용할 중요한 데이터 선택
-
Mask
- Attentive Transformer가 선택한 중요 정보만 남김
- 이 과정에서 Sparsemax가 사용되어 중요한 정보만 남김
- 이 Mask는 Feature Transformer에서 나온 변환된 Feature에 곱해져 중요한 특성만 활성화
-
Aggregation
- 활성화된 특성(Feature x Mask)은 Agg. 모듈에서 출력 방향으로 집계
- 집계된 결과는 결과값 출력에 기여하며, 각 step에서 누적됨
-
Feature attributes
- 단계별로 중요한 feature를 추출하여 모델이 학습 과정에서 어떤 데이터를 사용했는지 설명
- 이 부분은 해석 가능성(Interpretability)를 제공
- 모델이 "왜 이런 결정을 내렸는지"를 보여주는데 사용
2-4. DECODER
Decoder의 경우 각 단계별 feature transformer로 구성된다. 일반 학습에서는 Decoder를 사용하지 않지만 Self-supervised 학습 진행시 인코더 다음 붙여지며 기존 결측값 보완 및 표현 학습을 진행한다.
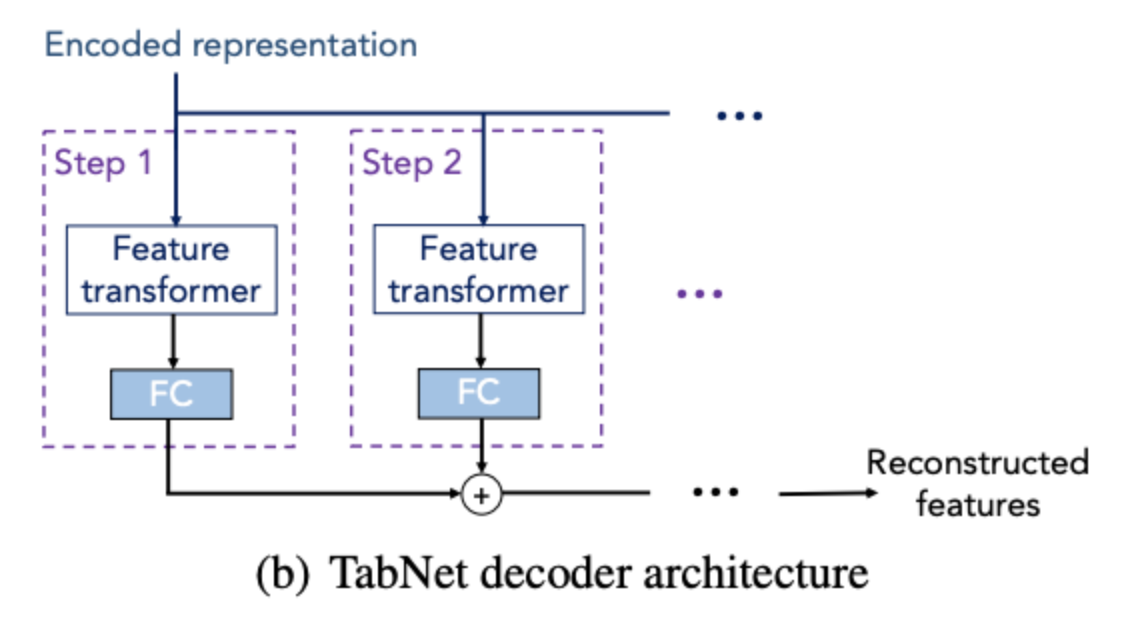
-
Encoded Representation
- 인코더에서 학습된 정보를 입력으로 받아 재구성
-
Feature Transformer
- 재구성을 위한 변환 과정 수행
-
Reconstructed Features
- 최종 출력은 원래의 입력 데이터를 재구성
3. TabNet Features
3-1. Sparse Feature Selection(=Decision Blocks)
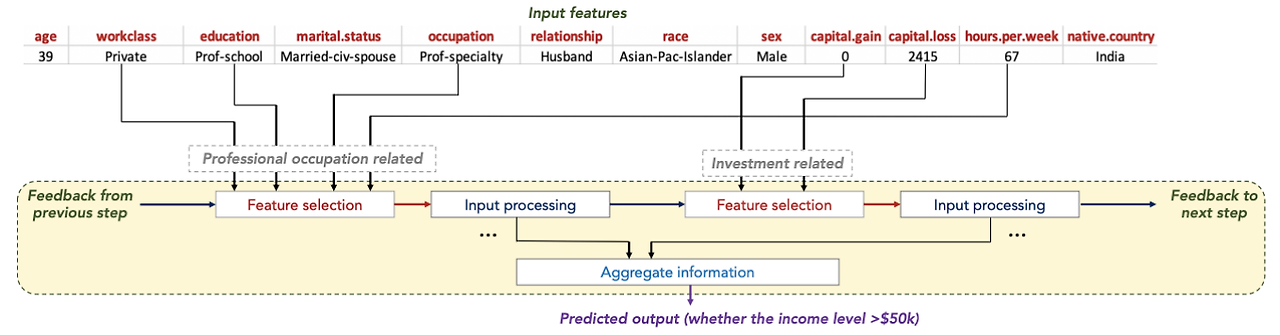
-
Input features (tabular 데이터)
- 목표(target): 연봉이 $50,000 이상인지 예측
-
Feature Selection
-
TabNet은 입력된 feature 중 어떤 특징이 현재 단계에서 중요한지 선택
-
Sequential Attention 매커니즘을 사용하여 각 단계에서 가장 중요한 feature에 집중
-
예를 들자면, 첫 번째 단계에서는 "professional occupation"가 예측에 중요하다고 판단하여, occupation, education와 같은 특징을 선택하고, 선택되지 않은 특징은 다음 단계로 넘어가며, 이후 단계에서 새로운 중요한 특징을 고려
-
-
Input Processing
- 특징별로 가중치를 계산하여, 해당 특징이 목표 예측에 얼마나 중요한지 학습
-
Feedback Mechanism
- TabNet의 강점은 이전 단계의 피드백을 받아 다음 단계에서 새로운 특징을 선택한다는 점
- 첫 번째 단계에서 "professional occupation"이 선택되었다면, 두 번째 단계에서는 "Investment"가 선택되게 하여, 모든 중요한 정보가 모델에 반영
-
Aggregation of Information
- 모든 단계에서 처리된 정보를 통합하여 최종 예측에 사용
-
Predicted Output
- 최종적으로, 모델은 모든 학습 단계를 바탕으로 목표를 예측
3-2. Self-supervised tabular learning
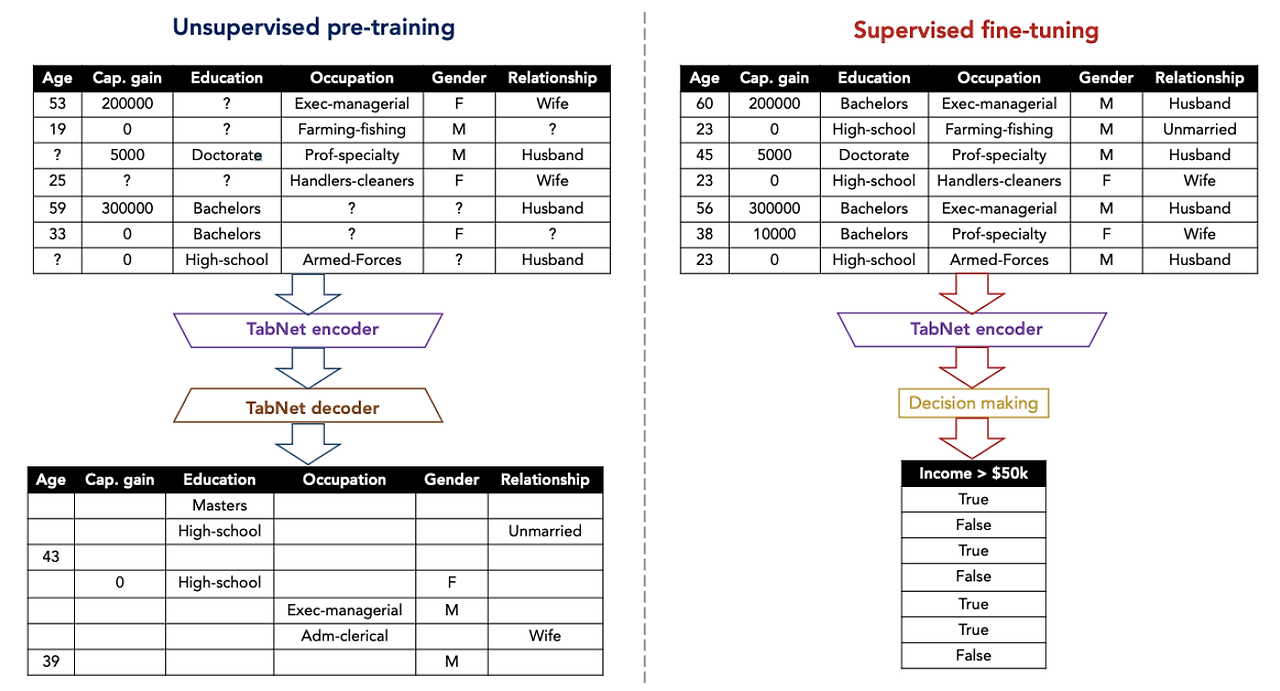
TabNet에서는 레이블이 없거나 결측치가 포함된 데이터셋에서 유용하게 사용할 수 있고, pre-training에도 사용할 수 있는 self-supervised learning을 제안한다. Encoder의 출력값을 입력받아 feature를 복원(reconstruct)하는 Decoder를 연결한 Autoencoder 구조이다.
4. Experiments
TabNet은 다양한 데이터셋에서 기존 모델보다 우수한 성능을 보였다.
4-1. Forest Cover Type
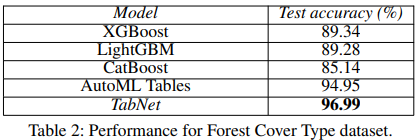
Forest Cover Type 데이터셋은 지리적 변수들을 기반으로 특정 지역의 삼림 덮개 유형을 분류하는 문제를 다루며, TabNet은 복잡한 하이퍼파라미터 튜닝 없이도 다양한 앙상블 모델을 기반으로 한 AutoML 시스템과 트리 기반 모델들을 초과하는 성능을 보여준다.
4-2. Poker Hand
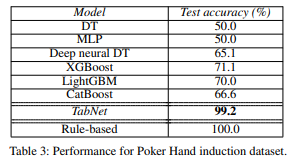
Poker Hand 데이터셋은 카드의 슈트(suit)와 랭크(rank) 속성으로 포커 손을 분류하는 문제를 다루며, TabNet은 다른 방법들보다 우수한 성능(99.2%)을 보인다.
4-3. Sarcos
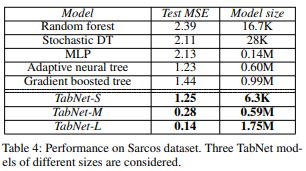
Sarcos 데이터셋은 로봇 팔의 역동학을 예측하는 데 사용되며, TabNet은 이 데이터셋에서 작은 모델 크기로도 뛰어난 성능을 보이며, 모델 크기가 제한되지 않으면 테스트 MSE가 다른 모델에 비해 현저히 낮은 성과를 달성한다.
4-4. Higgs Boson
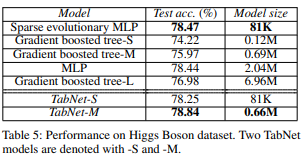
Higgs Boson 데이터셋은 힉스 보손 과정과 배경을 구별하는 분류 문제를 다루며, TabNet은 MLP보다 더 간결한 표현으로 성능을 향상시킨다.
4-5. Rossmann Store Sales
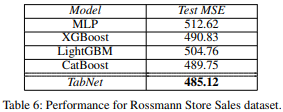
Rossmann Store Sales 데이터셋은 정적 및 시간에 따라 변하는 특성을 이용해 매장 판매를 예측하는 작업으로, TabNet은 일반적인 방법들을 능가하며 시간 관련 특성(날짜)의 중요도가 높게 나타났다.
5. Conclusions
TabNet은 tabular 데이터를 위한 딥러닝의 새로운 가능성을 제시하며, 해석 가능성과 성능 모두를 제공하는 독창적인 모델이다. 비지도 학습의 성공적인 도입은 데이터 레이블링 비용이 높은 응용 분야에서 TabNet의 활용성을 높인다는 점에서 큰 의의를 가지고 있다.
