Redis

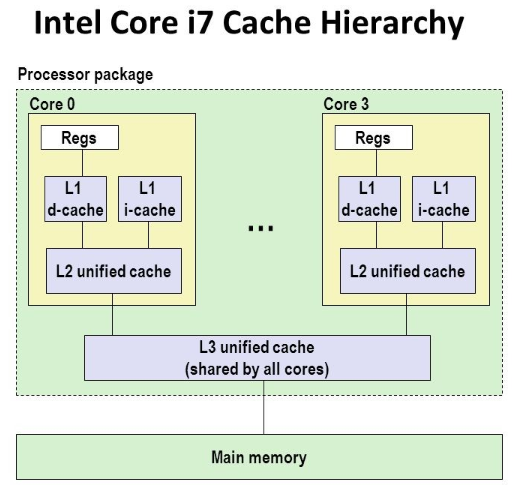
캐싱이라고 하면 나는 대표적으로 CPU안에 있는 캐쉬(L3,L2,L1)를 주로 생각했다. 해당 캐시에 데이터가 있으면 Hit 없음면 Miss로 만약 레지스터에서 필요한 데이터가 없으면 L1캐시에서 가져오고 데이터가 없으면 L2캐시에서 그다음 L1캐시에서 RAM,HDD(SSD)로 데이터를 가져오는 구조를 가져온다.
https://www.linkedin.com/pulse/introduction-cache-memory-omar-ehab/
현대 컴퓨터에서는 캐시라는 용어가 매우 중요한데 그 이유는 속도면에서 갈린다. 특히 HDD SSD의 속도에 한참을 못 미치기에 그 사이간의 간격을 조금이나마 줄여주는것으로 생각하면 된다.
(나는 어렸을때 언젠가 SSD가 매우 빨라지면 RAM도 필요 없어지겠지? 라고 생각했지만 아직 까지 그런날이 오지는 않았다...😅)
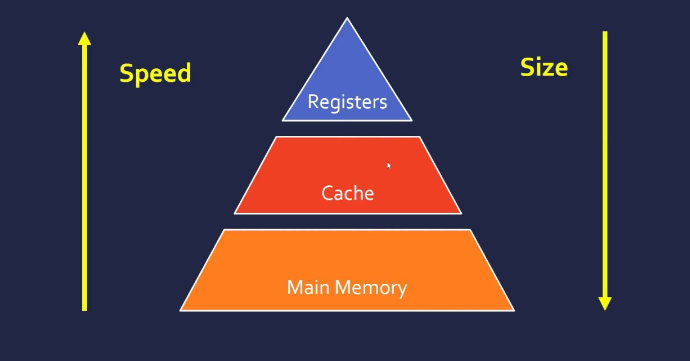
그림 처럼 화살표 밑으로 갈수록 속도는 느리지만 가격이 싸고 반대로 화살표 위로 갈수록 속도는 빠르지만 가격이 매우 비싸다. 그러면 캐시란 정확히 무엇일까?
https://www.linkedin.com/pulse/introduction-cache-memory-omar-ehab/
🎲캐시란?
데이터나 정보의 복사본을 일시적으로 저장하는 저장하는 임시 저장소
원본 데이터 정보에 대한 접근을 더 빠르고 효율적으로 만들어준다.
주로 캐시는 데이터베이스나 웹 서버 등의 백엔드 시스템 사이에서 중간에 위치한다.
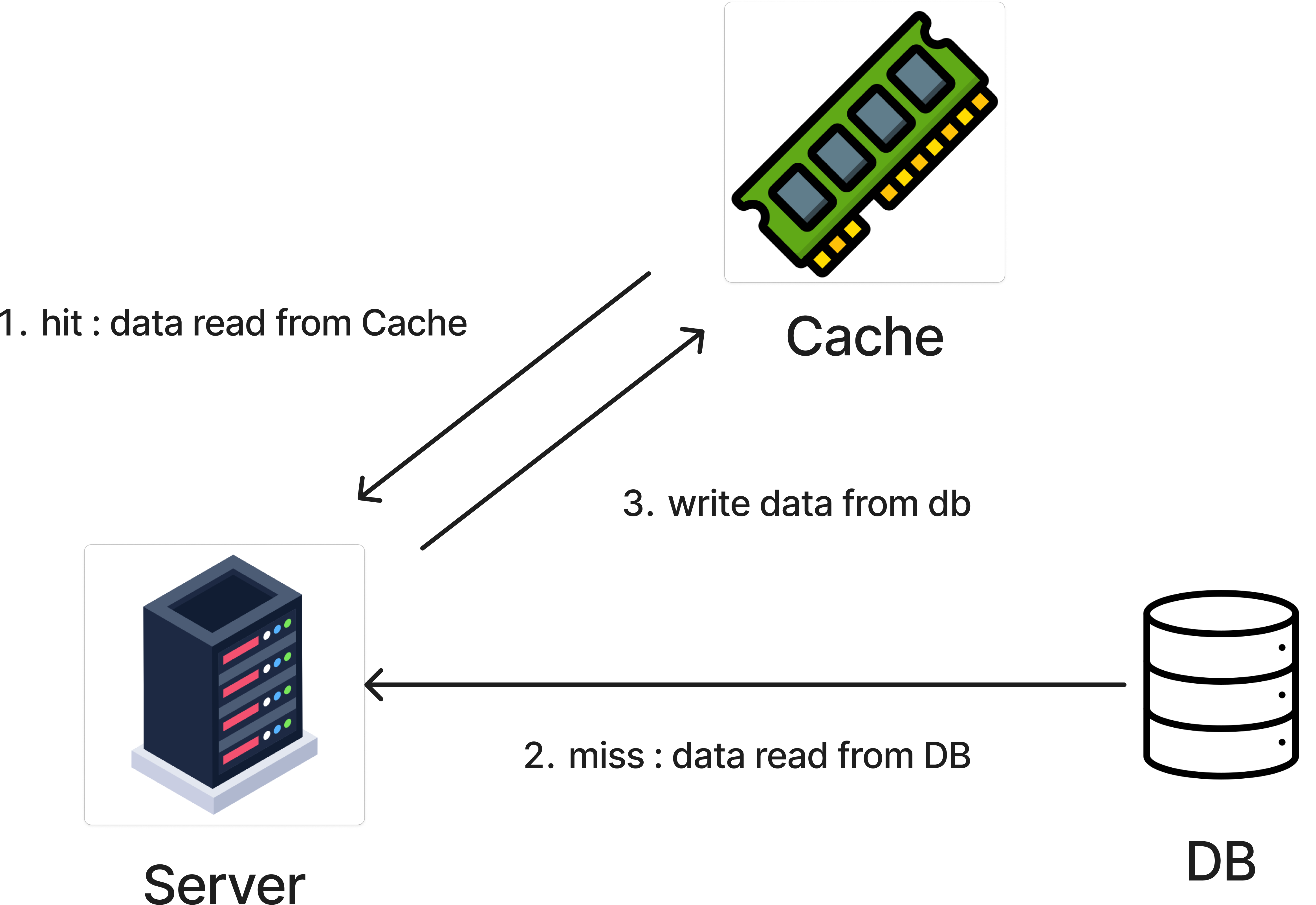
- 서버 또는 어플리케이션이 캐시(또는 캐시서버)에 데이터가 있는지 확인(이때 데이터가 존재하면 hit)
- 캐시에 데이터가 존재하지 않으면 데이터베이스에서 데이터를 가져온다.
- 가져온 데이터를 캐시에 저장하고 요청에 응답한다.
캐시를 쓰는 이유
- 성능 향상 : 캐시를 사용하면 데이터나 결과를 빠르게 검색하고 제공할 수 있어 응답 시간을 줄일 수 있다.
- 서버 부하 감소 : 캐시를 사용하면 데이터나 결과를 반복적으로 계산하거나 조회할 필요 없이 캐시된 정보를 사용할 수 있고 데이터 베이스에 접근하는 횟수를 줄여 응답 속도를 높일 수 있다.
- 데이터 보호 : 캐시는 데이터를 임시로 저장 하는 용도로 사용되기에 원본 데이터가 변경되어도 캐시된 데이터는 변경되지 않는다.
여러가지 이유가 있지만 가장 큰 이유는 데이터 베이스에 접근하는 횟수를 줄인다는 장점이 가장 크다고 생각된다.
Spring Data JPA에서 사용하는 1차 캐시도 이와 같은 원리로 동작한다.
대표적인 캐시가 Redis가 있다.
📕Redis
🎉Done
참고자료
