클라이언트 - 서버 아키텍처
일반적인 모바일앱들을 보았을 때 인터넷 연결 없이 잘 작동하지 않는다. 그 이유는 상품 정보를 인터넷 어딘가에 존재하는 서버로부터 받아와야 하기 때문이다.
만약 상품 정보들이 앱 안에 모두 담긴 경우라면 그 앱은 끊임없이 업데이트를 진행해야 한다. 새로운 상품, 삭제되는 상품들을 수정하기 위해서 말이다
그렇기에 앱을 사용하는 사람들에게 상품 정보를 실시간으로 전달하기가 매우 어렵다 이외 서버가 없다면 결제 라는 행동을 할 수 없다. 금전 정보를 주고받는
은행 서버와 연결이 필요하기 때문이다.
서버 아키텍처
그렇기에 상품 정보 같은 리소스가 존재하는 곳과 리소스를 사용하는 앱을 분리시킨 것을 2-Tier 아키텍처, 또는 클라이언트-서버아키텍처라고 부른다.
리스소를 사용하는 앱을 클라이언트 , 리소스를 제공하는 곳은 서버 라고 부른다.
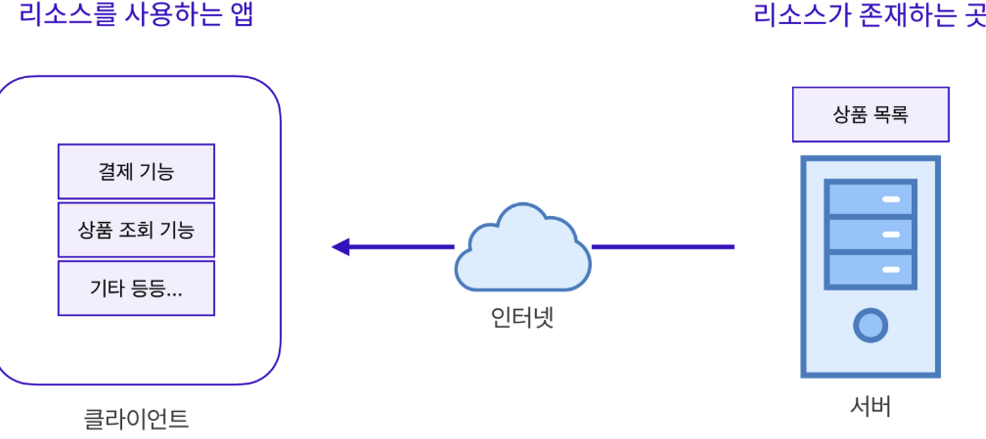
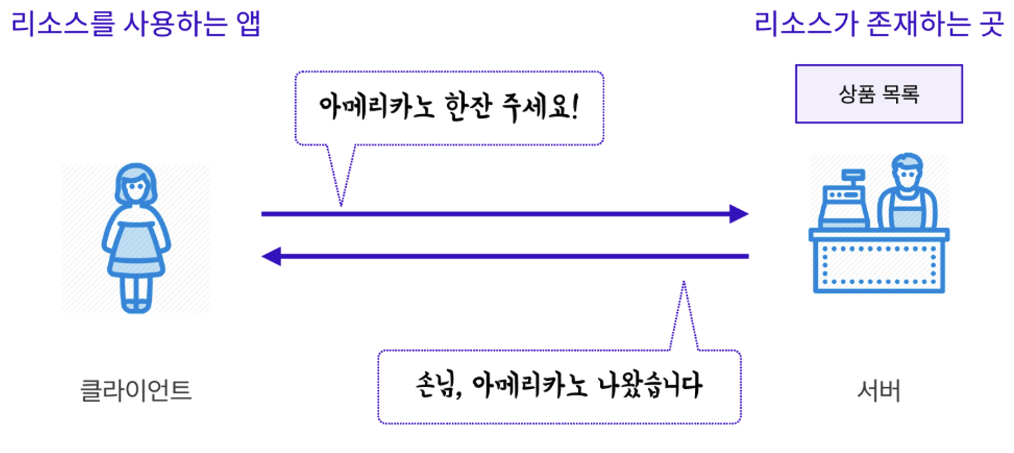
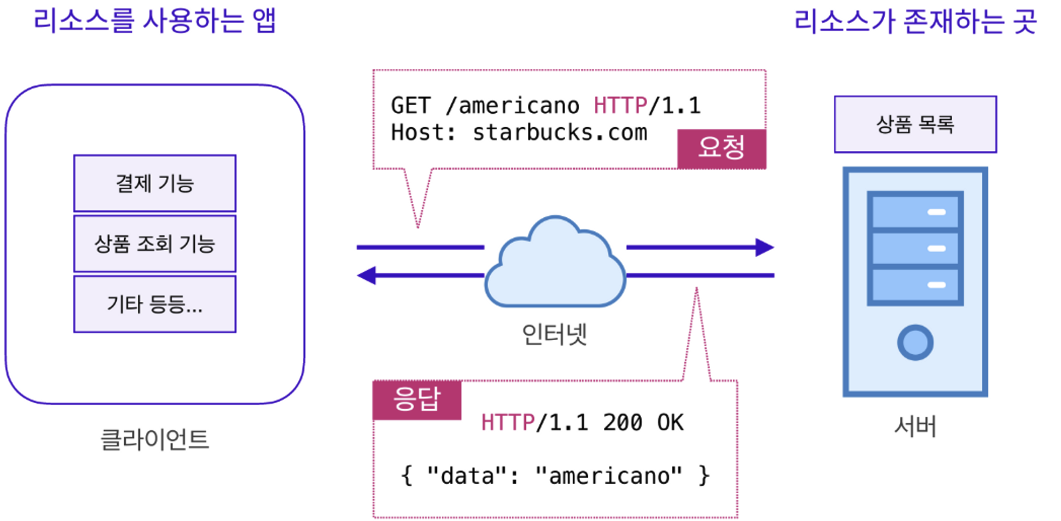
아래와 같이 예시를 보면 쉽게 이해할 수 있다. 클라이언트는 요청을 하게 되는 것 이고 서버는 그 요청에 응답을 해주는 것과 같다.
이처럼 클라이언트와 서버는 요청과 응답을 주고 받는 관계이다. 클라이언트-서버 아키텍처에서 요청이 선행되고 그 후 응답이 온다.
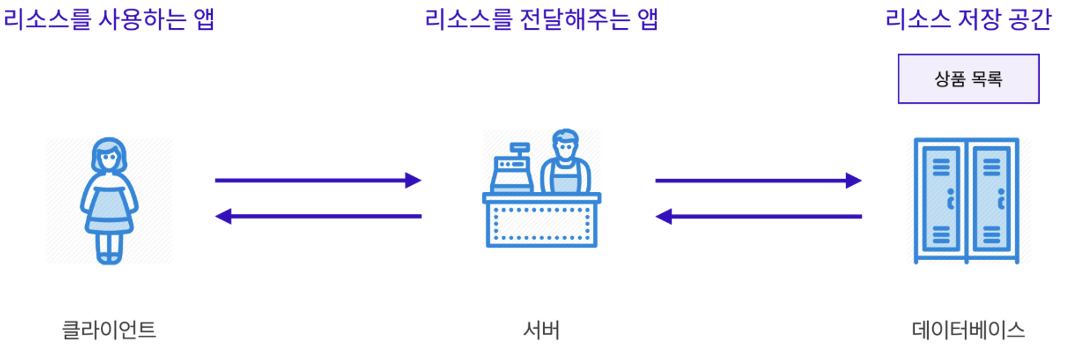
3-Tier 아키텍처
일반적으로 서버는 리소스를 전달 해주는 역할만 담당한다. 리소스를 저장하는 공간을 별도로 마련하는데 그 공간을 데이터베이스 라고 부른다.
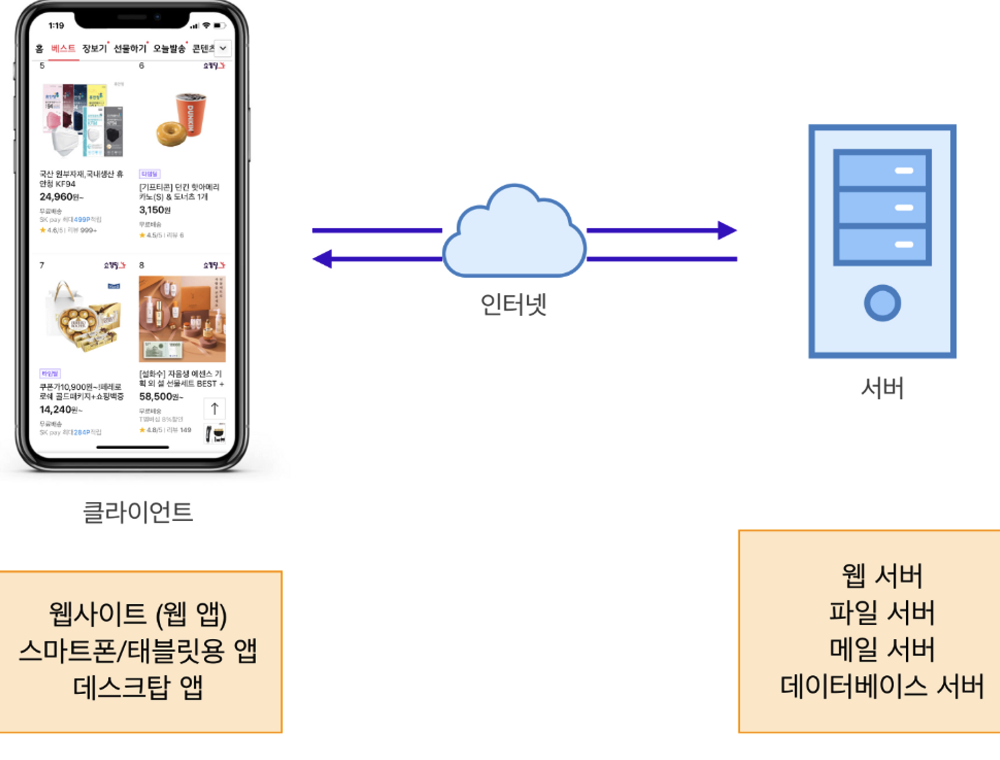
클라이언트 서버 종류
클라이언트는 플랫폼에 따라 구분된다. 브라우저를 통해 주로 웹 플랫폼에서의 클라이언트는 웹사이트 또는 웹 앱이라고 부른다.
iOS나 안드로이드와 같은 스마트폰/태블릿 플랫폼, 윈도우와 같은 데스크탑 플랫폼에서 이용하는 앱 역시 클라이언트가 될 수 있다.
서버는 어떤 일을 하냐에 종류가 달라진다. 파일을 제공하는 앱은 파일 서버를 메일을 주고받는 앱은 메일 서버를 데이터베이스 도 일종의 서버라고 볼 수 있다.
클라이언트 - 서버 통신과 API
클라이언트와 서버 간의 통신을 알기위해선 프로토콜이라는 개념을 이해해야 한다.
프로토콜
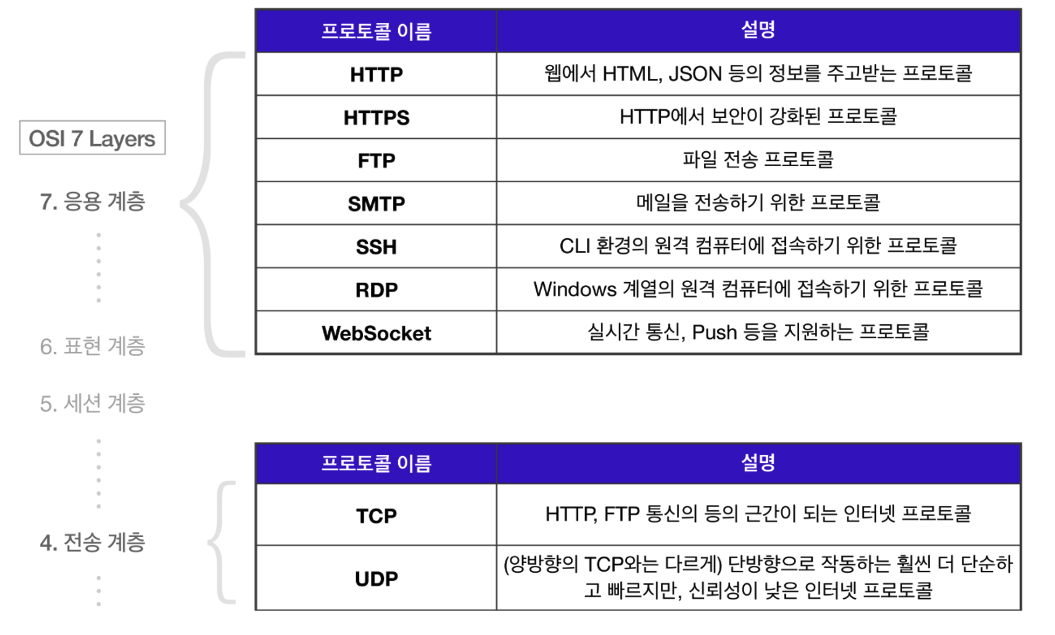
프로토콜은 통신 규약, 약속과 같은 의미를 지닌다. 웹 애플리케이션 아키텍처에서는 클라이언트와 서버가 HTTP라는 프로토콜을 이용해서 서로 대화를 나눈다
OSI 7 Layers라는 개념으로 주요 프로토콜이 어떤 계층에 속해있는지를 표시하고 있다.
API
Application Programming Interface 서버는 클라이언트에게 리소스를 잘 활용할 수 있게 인터페이스를 제공해 줘야 한다. 메뉴판이라고 생각하면 편하다.
API는 앱이 요청할 수 있고 프로그래밍 가능한 인터페이스다. 예를들어 커피전문점에서 곰탕을 시키지 않도록 정해진 메뉴판을 만들어 놓기 때문에
적절한 요청을 할 수 있게만든다. 따라서 서버가 리소스 전달을 위한 API를 구축해놔야 클라이언트가 이를 활용할 수 있다.
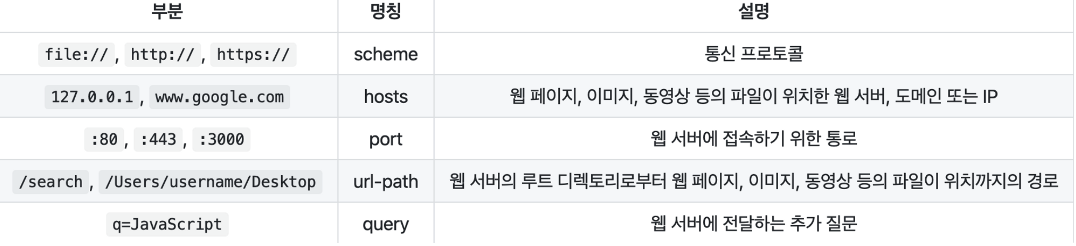
보통 인터넷에 있는 데이터를 요청할 때 HTTP라는 프로토콜을 사용하여 주소(URL, URI)를 통해 접근한다. 일반적인 주소 뒤에 정보들이 담긴 곳을 보면
? 또는 & 기호를 사용하는데 이 옵션들을 파라미터라고 부른다.
URL , URI
URL
URL은 Uniform Resource Locator의 줄임말로 네트워크 상에서 웹 페이지, 이미지, 동영상 등의 파일이 위치한 정보를 나타낸다.
URI
URI 은 Uniform Resource Identifier의 줄임말로 일반적으로 URL의 기본 요소에 더한 URL을 포함하는 상위개념이다.
IP , Port
IP 란 네트워크에 연결된 특정 PC주소를 나타내는 체계를 IP address(internet protocol address)라고 한다.
PORT 란 IP 주소에 진입할 수 있는 정해진 통로를 얘기한다.
IP
대부분의 공유기를 설치하고 비밀번호를 설정하려면 공유기 관리 페이지에 접속해야한다. 웹 브라우저에서 닷(.)으로 구분된 네 덩이의 숫자를 입력하면 접속이 가능한대
이때 사용되는 네 덩이의 숫자를 IP주소라고 한다. 이 네 덩이의 숫자로 구분된 IP 주소체계를 IPv4라고 하며 주소체계의 네 번째 버전을 뜻한다.
IPv4는 각 덩어리마다 0부터 255까지 나타낼 수 있다. 그 중 몇 가지는 이미 용도가 정해져 있다.
[localhost](http://localhost),127.0.0.1: 현재 사용 중인 로컬PC를 지칭한다.
인터넷 보급률 낮았던 초기에는 IPv4만으로 주소할당이 가능했지만 보급률이 높은 지금 그 한계점에 부딪혀 IPv6가 나오게 되었다.

Port
로컬 PC의 IP 주소인 127.0.0.1 뒤에 :3000 과 같은 숫자가 표현된다. 이 숫자는 IP 주소가 가리키는 PC에 접속할 수 있는 통로(채널)을 의미한다.
이미 사용 중인 포트는 중복해서 사용할 수 없다. 포트 번호는 0 ~ 65535까지 사용할 수 있다. 그중에서 0 ~ 1024번까지의 포트 번호는 주요 통신을 위한 규약에 따라
이미 정해져있다 주요 포트번호는 22 : SSH 80 : HTTP 443 : HTTPS 등이 있다.
도메인 , DNS
도메인
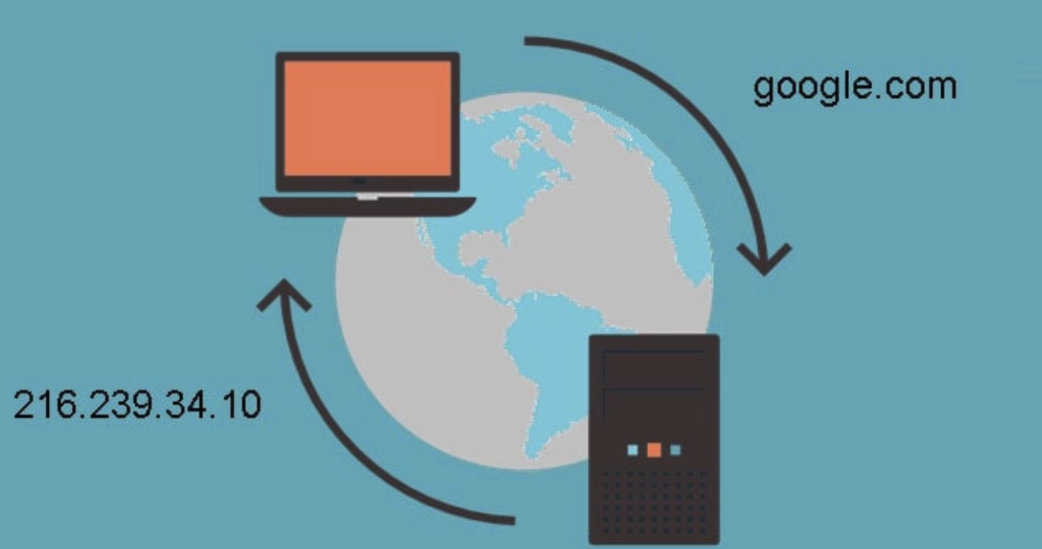
도메인은 IP 주소를 대신하여 사용하는 주소다 IP주소만 사용하게 된다면 매번 숫자를 입력해서 들어가야하기 때문에 한눈에 파악하기 힘들다
그렇기에 대표하는 주소를 표기해 도메인을 사용한다. 터미널에서 nslookup 명령어를 이용하여 도메인 주소를 입력하면 IP 주소와 도메인 이름이 나온다.
DNS
네트워크 상에 존재하는 모든 PC는 IP 주소가 존재하는데. 모든 IP주소가 도메인 이름을 가지고 있는 것은 아니다. 도메인 이름은 일정 기간 동안에 대여하여 사용한다
이렇게 대여한 도메인 이름과 IP주소를 확인하는 작업이 필요하다. 네트워크에서는 이것을 위한 서버가 별도로 존재하는데 그걸 DNS(Domain Name System)라고 한다.
DNS는 호스트의 도메인 이름을 IP 주소로 변환하거나 반대의 경우를 수행할 수 있도록 개발된 데이터베이스 시스템이다.
HTTP Messages
HTTP Messages
HTTP Messages는 클라이언트와 서버 사이에서 데이터가 교환되는 방식이다. 두 가지 유형이 존재하는데. 요청(Requests) , 응답(Responses)가 있다.
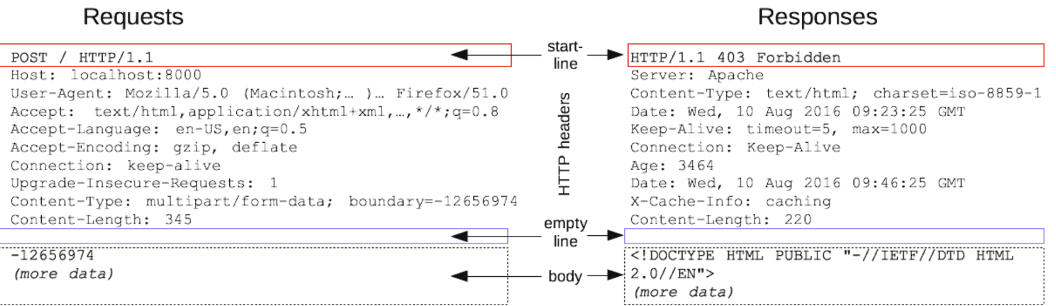
요청과 응답은 다음과 같은 유사한 구조를 가진다.
- start line : start line에는 요청이나 응답의 상태를 나타낸다. 항상 첫 번째 줄에 위치한다. 응답에서는 status line이라고 한다.
- HTTP headers : 요청을 지정하거나, 메시지에 포함된 본문을 설명하는 헤더의 집합이다.
- empty line : 헤더와 본문을 구분하는 빈 줄
- body : 요청과 관련된 데이터나 응답과 관련된 데이터 또는 문서를 포함한다. 요청과 응답의 유형에 따라 선택적으로 사용한다.
Stateless
상태를 가지지 않는다는 뜻이며, HTTP의 큰 특징 중 하나 HTTP로 클라이언트와 서버가 통신을 주고받는 과정에서, HTTP가 클라이언트나 서버의 상태를 확인하지 않는다.
사용자는 쇼핑몰에 로그인하거나 상품을 클릭해서 상세 화면으로 이동하고, 상품을 카트에 담거나 로그아웃할 수도 있다. 클라이언트에서 발생한 이런 모든 상태를
HTTP통신이 추적하지않는다. 통신 규약일 뿐이므로, 상태를 저장하지 않기 때문이다.
HTTP Requests
클라이언트가 서버에게 보내는 메시지이다.
Start line
요청의 Headers는 기본 구조를 따릅니다. 헤더 이름(대소문자 구분이 없는 문자열), 콜론( : ), 값을 입력합니다. 값은 헤더에 따라 다릅니다. 여러 종류의 헤더가 있고, 다음과 같이 그룹을 나눌 수 있습니다.
- 수행할 작업(GET, PUT, POST)이나 방식(HEAD or OPTIONS)을 설명하는 HTTP 메서드를 나타낸다
- 요청 대상(일반적 URL or URI) 또는 프로토콜, 포트, 도메인의 절대 경로는 요청 컨텍스트에 작성된다. 요청 형식은 HTTP 메서드 마다 다르다
- origin 형식 :
'?'와 쿼리 문자열이 붙는 절대 경로입니다. GET, POST, HEAD, OPTIONS 등의 method와 함께 사용합니다.
POST / HTTP 1.1GET /background.png HTTP/1.0HEAD /test.html?query=alibaba HTTP/1.1OPTIONS /anypage.html HTTP/1.0 - absolute 형식 : 완전한 URL 형식으로, 프록시에 연결하는 경우 대부분 GET method와 함께 사용합니다.
GET http://developer.mozilla.org/en-US/docs/Web/HTTP/Messages HTTP/1.1 - authority 형식 : 도메인 이름과 포트 번호로 이루어진 URL의 일부분입니다. HTTP 터널을 구축하는 경우,
CONNECT와 함께 사용할 수 있습니다.
CONNECT developer.mozilla.org:80 HTTP/1.1 - asterisk 형식 :
OPTIONS와 함께 별표(`) 하나로 서버 전체를 표현합니다.OPTIONS * HTTP/1.1`
- origin 형식 :
- HTTP 버전에 따라 구조가 달라진다. 따라서 start line에 HTTP 버전을 함께 입력한다.
Headers
-
General headers : 메시지 전체에 적용되는 헤더로, body를 통해 전송되는 데이터와는 관련이 없는 헤더입니다.
-
Request headers : fetch를 통해 가져올 리소스나 클라이언트 자체에 대한 자세한 정보를 포함하는 헤더를 의미합니다. User-Agent, Accept-Type, Accept-
Language와 같은 헤더는 요청을 보다 구체화합니다. Referer처럼 컨텍스트를 제공하거나 If-None과 같이 조건에 따라 제약을 추가할 수 있습니다.
-
Representation headers : 이전에는 Entity headers로 불렀으며, body에 담긴 리소스의 정보(콘텐츠 길이, MIME 타입 등)를 포함하는 헤더입니다.

Body
GET, HEAD, DELETE, OPTIONS처럼 서버에 리소스를 요청하는 경우에는 본문이 필요하지 않습니다. POST나 PUT과 같은 일부 요청은 데이터를 업데이트하기 위해 사용
합니다. body는 다음과 같이 두 종류로 나눌 수 있습니다.
- Single-resource bodies(단일-리소스 본문) : 헤더 두 개(Content-Type과 Content-Length)로 정의된 단일 파일로 구성됩니다.
- Multiple-resource bodies(다중-리소스 본문) : 여러 파트로 구성된 본문에서는 각 파트마다 다른 정보를 지닙니다. 보통 HTML form과 관련이 있습니다.
HTTP Responses
Status line
- 현재 프로토콜의 버전(HTTP/1.1)
- 상태 코드 - 요청의 결과를 나타냅니다. (ex. 200, 302, 404 등)
- 상태 텍스트 - 상태 코드에 대한 설명
Headers
-
Heneral headers : 메시지 전체에 적용되는 헤더로, body를 통해 전송되는 데이터와는 관련이 없는 헤더이다.
-
Response headers : 위치 또는 서버 자체에 대한 정보(이름, 버전)와 같이 응답에 대한 부가적인 정보를 갖는 헤더로, Vary, Accept-Ranges와 같이
상태 줄에 넣기에는 공간이 부족했던 추가 정보를 제공한다.
-
Representation headers : 이전에는 Entity headers로 불렀으며, body에 담긴 리소스의 정보(콘텐츠 길이, MIME 타입 등)를 포함하는 헤더입니다.
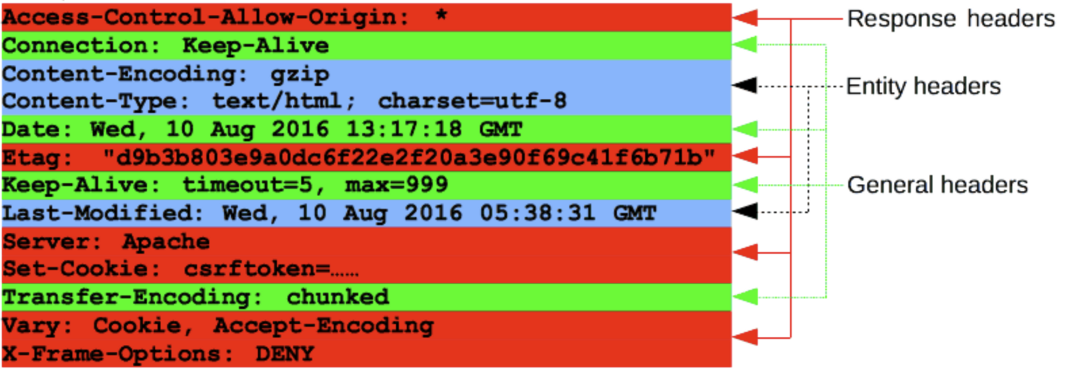
Body
- Single-resource bodies(단일-리소스 본문) :
- 길이가 알려진 단일-리소스 본문은 두 개의 헤더(Content-Type, Content-Length)로 정의합니다.
- 길이를 모르는 단일 파일로 구성된 단일-리소스 본문은 Transfer-Encoding이
chunked로 설정되어 있으며, 파일은 chunk로 나뉘어 인코딩 되어 있습니다.
- Multiple-resource bodies(다중-리소스 본문) : 서로 다른 정보를 담고 있는 body입니다.
AJAX
Ajax는 Asynchronous JavaScript And XMLHttpRequest의 약자로 , JavaScript , DOM, Fetch, XMLHttpRequest HTML등의 다양한 기술을 사용하는
웹 개발 기법이다. 가장 큰 특징은 웹 페이지에 필요한 부분에 필요한 데이터만 비동기적으로 받아와 화면에 그려낼 수 있다.
AJAX의 핵심 기술
JavaScript, DOM, Fetch가 Ajax를 구성하는 핵심 기술이다. 페이지를 매번 새로운 페이지로 이동하지 않고 필요한 데이터를 받아올 수 있게 만든것이 가장 큰 특징이다.
Fetch를 이용하면 브라우저는 Fetch가 서버에 요청을 보내고 응답을 받을 때까지 모든 동작을 멈추는 것이 아니라 계속해서 페이지를 사용할 수 있게 하는 비동기적인
방식을 사용한다. 필요한 데이터만 가져와 페이지를 이동하지 않고 기존 페이지에서 필요한 부분만 변경이 가능하다.
XHR 과 Fetch
Fetch 이전에 XHR을 사용하여 비동기를 진행했었다. Fetch는 XHR의 단점을 보완한 새로운 Web API이며, XML보다 가볍고 JavaScript와 호환되는 JSON을 사용한다.
- Fecth 예제
fetch('http://52.78.213.9:300/messages')
.then(function (response))// Fetch를 사용
.then (function(response) {
return response.json();
})
.then(function (json) {
...
});- XMLHttpRequest 예제
var xhr = new XMLHttpRequest();
xhr.open('get', 'http://52.78.213.9:3000/messages');
xhr.onreadystatechange = function(){
if(xhr.readyState !== 4) return;
// readyState 4: 완료
if(xhr.status === 200) {
// status 200: 성공
console.log(xhr.responseText); // 서버로부터 온 응답
} else {
console.log('에러: ' + xhr.status); // 요청 도중 에러 발생
}
}
xhr.send(); // 요청 전송AJAX의 장점
- 서버에서 HTML을 완성하여 보내주지 않아도 웹페이지를 만들 수 있습니다. 이전에는 서버에서 HTML을 완성하여 보내주어야 화면에 렌더링을 할 수 있었습니다. 그러나 AJAX를 사용하면 서버에서 완성된 HTML을 보내주지 않아도 필요한 데이터를 비동기적으로 가져와 브라우저에서 화면의 일부만 업데이트하여 렌더링 할 수 있습니다.
- 표준화된 방법 이전에는 브라우저마다 다른 방식으로 AJAX를 사용했으나, XHR이 표준화되면서부터 브라우저에 상관없이 AJAX를 사용할 수 있게 되었습니다.
- 유저 중심 애플리케이션 개발 AJAX를 사용하면 필요한 일부분만 렌더링하기 때문에 빠르고 더 많은 상호작용이 가능한 애플리케이션을 만들 수 있습니다.
- 더 작은 대역폭 대역폭: 네트워크 통신 한 번에 보낼 수 있는 데이터의 크기 이전에는 서버로부터 완성된 HTML 파일을 받아와야 했기 때문에 한 번에 보내야 하는 데이터의 크기가 컸습니다. 그러나 AJAX에서는 필요한 데이터를 텍스트 형태(JSON, XML 등)로 보내면 되기 때문에 비교적 데이터의 크기가 작습니다.
AJAX의 단점
- Search Engine Optimization(SEO)에 불리 AJAX 방식의 웹 애플리케이션은 한 번 받은 HTML을 렌더링 한 후, 서버에서 비동기적으로 필요한 데이터를 가져와 그려냅니다. 따라서, 처음 받는 HTML 파일에는 데이터를 채우기 위한 틀만 작성되어 있는 경우가 많습니다. 검색 사이트에서는 전 세계 사이트를 돌아다니며 각 사이트의 모든 정보를 긁어와 사용자에게 검색 결과로 보여줍니다. AJAX 방식의 웹 애플리케이션의 HTML 파일은 뼈대만 있고 데이터는 없기 때문에 사이트의 정보를 긁어가기 어렵습니다.
- 뒤로가기 버튼 문제 일반적으로 사용자는 뒤로가기 버튼을 누르면 이전 상태로 돌아갈 거라고 생각하지만, AJAX에서는 이전 상태를 기억하지 않기 때문에 사용자가 의도한 대로 동작하지 않습니다. 따라서 뒤로가기 등의 기능을 구현하기 위해서는 별도로 History API를 사용해야 합니다.
SSR , CSR
SSR
서버 사이드 렌더링은 웹 페이지를 브라우저에서 렌더링하는 대신에 서버에서 렌더링을 한다. 브라우저가 서버의 URI로 GET 요청을 보내면, 서버는 정해진 웹 페이지
파일을 브라우저로 전송한다. 그리고 서버의 웹 페이지가 브라우저에 도착하면 완전히 렌더링된다. 서버에서 웹 페이지를 브라우저로 보내기 전에 서버에서 완전히
렌더링했기 때문에 서버 사이드 렌더링이라고 한다.
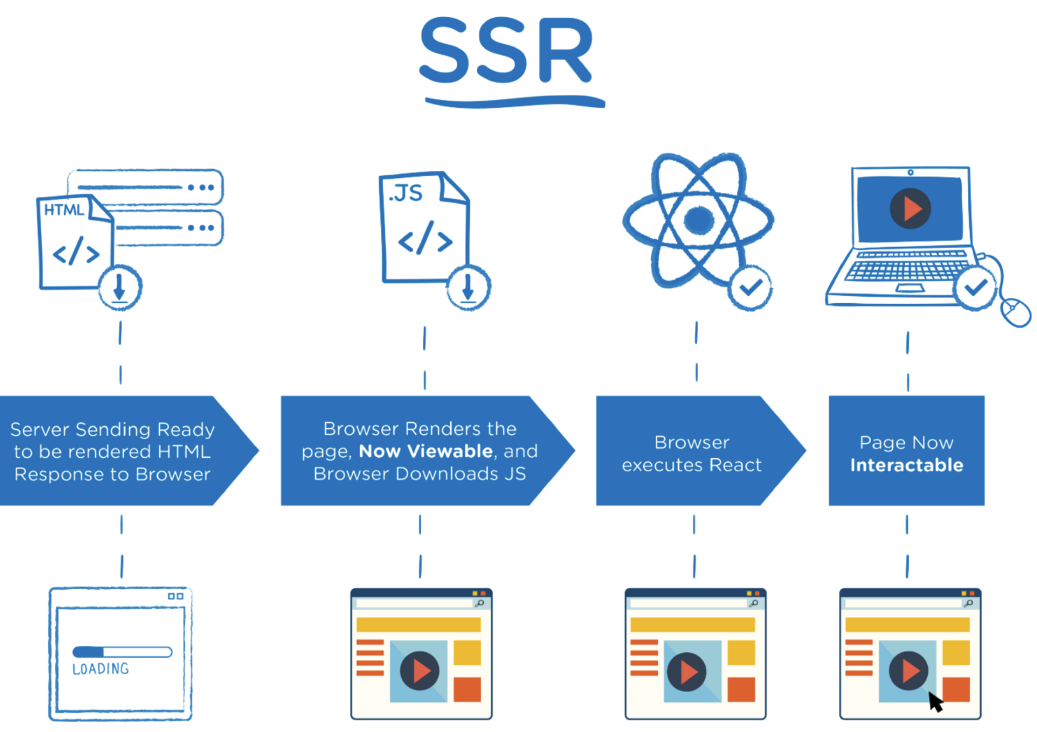
CSR
클라이언트 사이드 렌더링은 클라이언트에서 페이지를 렌더링한다. 웹 개발에서 사용하는 대표적인 클라이언트는 웹 브라우저이며 브라우저의 요청을 서버로 보내면
서버는 웹 페이지를 렌더링하는 대신 웹 페이지의 골격이 될 단일 페이지를 클라이언트에 보낸다. 이때 서버는 웹 페에지와 함께 JavaScript파일을 보낸다.
클라이언트가 웹 페이지를 받으면, 웹 페이지와 함께 전달된 JavaScript파일은 브라우저의 웹 페이지를 완전히 렌더링 된 페이지로 바꾼다.

SSR , CSR 차이점
페이지의 렌더링되는 위치에 차이가있다. SSR은 서버에서 페이지를 렌더링하고, CSR은 브라우저(클라이언트)에서 페이지를 렌더링한다. CSR은 사용자가
다른 경로를 요청할 때마다 페이지를 새로고침 하지 않고, 동적으로 라우팅을 관리한다.
SSR 사용
- SEO가 우선순위인 경우, 일반적으로 SSR을 사용한다
- 웹 페이지의 첫 화면 렌더링이 빠르게 필요한 경우, 단일 파일의 용량이 적은 SSR이 적합하다.
- 웹 페이지가 사용자와 상호작용이 적은 경우, SSR을 활용할 수 있다.
CSR 사용
- SEO 가 우선순위가 아닌 경우, CSR을 이용할 수 있다
- 사이트에 풍부한 상호 작용이 있는 경우, CSR은 빠른 라우팅으로 강력한 사용자 경험을 제공한다
- 웹 애플리케이션을 제작하는 경우, CSR을 이용해 더 나은 사용자 경험을 제공할 수 있다
