
Lexical Analysis 는 series of bytes를 input으로 받고, series of token을 output으로 낸다.
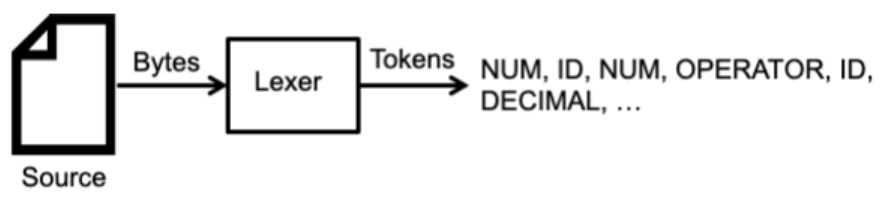
Lexical Analyzer(Lexer)는 이렇게 token을 만들어내는 프로그램/모듈인데, token은 정규 표현식을 통해 만들어진다.
1. 실습 : ID 토큰 만들기
letter = a|b|c|d|e..|A|B|C|D|E ..
digit = 0|1|2|3|4|5|6|7|8|9|
➡️ID = letter(letter | digit | _ )* // lexer의 "패턴"
의미: letter이 오고, 그 뒤에 zero or more (letter or digit or _)이 온다.
1) lexer에게 input으로 "a891_jksdbed"이 주어지면, 어떠한 토큰이 만들어질까?!
a = letter로 통과된다. lexer는 그 뒤 8, 9, 1, _부터 d까지 하나하나 체크하는데 모두 (letter or digit or __)이므로, ID(a891_jksdbed)가 만들어진다.
2) "12ajkdfjb" 가 주어지면 토큰이 만들어질까?!
lexer가 one by one 체크하는데, 1이 letter에 해당하지 않으므로 lexer는 어떠한 토큰도 만들어내지 않고 "lexical error"을 만들어 낸다.
=> 이와 같이, lexer는 정규 표현식을 사용하여 토큰의 패턴을 명시하고, 토큰의 패턴이 맞는 경우 적절하게 토큰을 만들어주게 된다.
2. 실습 : NUM 토큰 만들기
letter = a|b|c|d|e..|A|B|C|D|E ..
digit = 0|1|2|3|4|5|6|7|8|9|
➡️ID = letter(letter | digit | _ )* // lexer의 "패턴"
➡️NUM = digit*
1) "125"를 전달하면 토큰이 만들어질까?!
=> NUM("125") 만들어진다!
2) ""(empty string)을 전달해도 토큰은 만들어질까?!
=> digit* 이므로, NUM("")이 만들어진다. 따라서 NUM 토큰의 패턴을 바꿔야 한다.
➡️NUM = digit+ // one or more을 의미한다.
3) ""을 전달하면, 토큰이 만들어지지 않는다.
4) 00000 을 전달하면 토큰이 만들어질까?!
=> 0은 digit에 있고, 그 뒤 0도 각각 digit에 속하므로 NUM(00000)이 만들어진다. 따라서 NUM 토큰의 패턴을 바꿔야 한다.
letter = a|b|c|d|e..|A|B|C|D|E ..
digit = 0|1|2|3|4|5|6|7|8|9|
positive_digit = 1|2|3|4|5|6|7|8|9|
➡️ID = letter(letter | digit | _ )* // lexer의 "패턴"
➡️NUM = positive_digit(digit)*
5) 00000 을 전달하면 NUM 토큰이 만들어지지 않는다. 052를 전달해도 토큰을 만들어지지 않는다.
3. 실습 : Decimal 토큰 만들기
1) 소숫점이 있는 숫자가 들어왔을 때 decimal 토큰을 어떻게 만들 수 있을까?
현재 상태로는 1.5가 주어지면, lexical error가 발생할 것이다.
letter = a|b|c|d|e..|A|B|C|D|E ..
digit = 0|1|2|3|4|5|6|7|8|9|
positive_digit = 1|2|3|4|5|6|7|8|9|
➡️ID = letter(letter | digit | _ )* // lexer의 "패턴"
➡️NUM = positive_digit(digit)*
➡️DECIMAL = NUM . \. . NUM
(NUM과 dot과 NUM을 concatenate 한 패턴)
=> 1.5 => DECIMAL(1.5) 토큰이 생성된다.
2) 1.05는 토큰이 생성될까?
=> 현재 NUM은 positive digit으로 시작하기 때문에 생성되지 않고 'lexical error' 발생
letter = a|b|c|d|e..|A|B|C|D|E ..
digit = 0|1|2|3|4|5|6|7|8|9|
positive_digit = 1|2|3|4|5|6|7|8|9|
➡️ID = letter(letter | digit | _ )* // lexer의 "패턴"
➡️NUM = positive_digit(digit)*
➡️DECIMAL = NUM . \. . digit*
=> 1.05 => DECIMAL(1.05) 생성된다.
3) 1. 도 토큰이 생성될까?!
=> 1. => DECIMAL(1.)이 생성된다. 따라서 패턴을 바꿔야 한다.
letter = a|b|c|d|e..|A|B|C|D|E ..
digit = 0|1|2|3|4|5|6|7|8|9|
positive_digit = 1|2|3|4|5|6|7|8|9|
➡️ID = letter(letter | digit | _ )* // lexer의 "패턴"
➡️NUM = positive_digit(digit)*
➡️DECIMAL = NUM . \. . digit . digit*
=> 1.은 lexical error가 발생함 !
4) 0.05 는 토큰이 생성될까?!
=> 0은 positive_digit이 아니기 때문에 lexcial error 발생. 업뎃 필요
=> 이런 식으로 패턴을 업뎃 해가면서 원하는 대로 만들면 된다 !
2. Lexical Analysis
Lexical Analysis는 Syntax Analyzer(=Parser)과 함께 일한다. Parser는 Lexer에게 토큰을 요청하고, Lexer는 토큰을 반환한다.
Lexer가 문자열의 '현재 위치'를 기억하고, parser가 다시 토큰을 요청할 때 그 위치로 돌아가서 다음 토큰을 생성한다.
만약 잘못 되면, Lexical Error나 Syntax Error가 발생한다. Lexical Error는 주어진 문자열이 토큰의 패턴에 맞지 않으면 발생한다.
3. Longest Matching Prefix Rule
1) input="abc"에 대해 lexer는 어떤 토큰을 만들까?!
letter = a|b|c|d|e..|A|B|C|D|E ..
digit = 0|1|2|3|4|5|6|7|8|9|
positive_digit = 1|2|3|4|5|6|7|8|9|
ID = letter.(letter|digit|_)*
=> ID(abc)
=> ID(a), ID(b), ID(c)
두 가지 모두 가능하지 않을까? lexer는 어떤 토큰을 만들까?!
2) input="12"에 대해 lexer는 어떤 토큰을 만들까?!
digit = 0|1|2|3|4|5|6|7|8|9|
positive_digit = 1|2|3|4|5|6|7|8|9|
DIGIT = digit+
PDIGIT = pdigit+
=> DIGIT(12)
=> PDIGIT(12)
두가지 모두 가능하지 않을까? lexer는 어떤 토큰을 만들까?
3) 이 문제를 해결하는 규칙 = "Longest Matching Prefix Rule"
(1) Starting from the next input symbol, find the longest string that matches a token.
(2) Break ties by giving preference to token listed first in the list
-> 규칙(1)에 의해 ID(abc)와 ID(a), ID(b), ID(c) 중 ID(abc)가 가장 길기 때문에, ID(abc)가 생성된다.
-> 규칙(2) DIGIT(12), PDIGIT(12)의 경우에는 토큰 리스트 중 가장 먼저 Matching된 토큰을 생성한다. DIGIT 토큰이 먼저 정의되어 있기 때문에 DIGIT 토큰이 생성된다.
4) 실습 : "1.1abc1.2" 에 대해서 어떤 토큰이 반환될까?!
letter = a|b|c|d|e..|A|B|C|D|E ..
digit = 0|1|2|3|4|5|6|7|8|9|
positive_digit = 1|2|3|4|5|6|7|8|9|ID = letter.(letter|digit|_)*
DOT = \.
NUM = digit.(digit)* | 0
DECIMAL = NUM.DOT.digit.digit
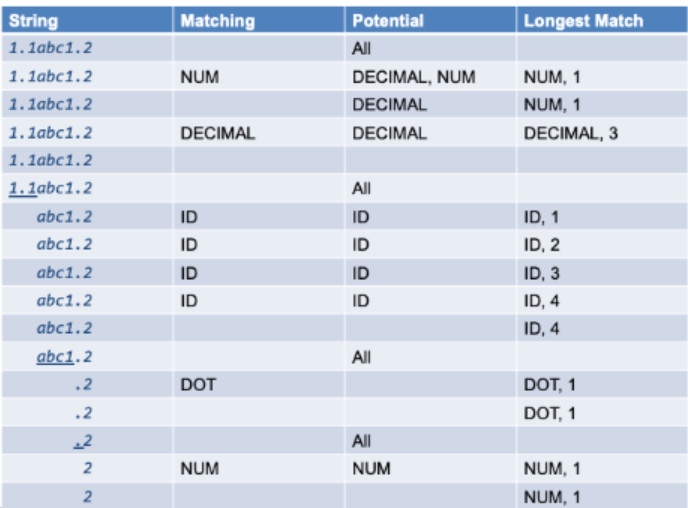
1.1 = DECIMAL("1.1")
abc1 = ID("abc1")
. = DOT(".")
2 = NUM("2")
4. 주의할 점
1) Whitespace
➡️ (5+10) vs ( 5 + 10 )
두가지를 동일하게 볼 것인가? 대부분의 프로그래밍 언어에서 whitespace는 중요하지 않다.
python에서는 indentation이 중요하기 때문에 whitespace가 중요하다.
Fortran에서는 whitespace가 무시된다.
Do 15 |= 1,100
// loop statement (i = 1부터 100까지 DO 15)
Do 15 |= 1.1000
// assign statement (DO15| = 1.100 대입)
=> Whitespace는 fortran에서 무시되기 때문에 .을 , 로 잘못 쓰면 위와 같이 완전히 의미가 달라질 수 있다.
따라서 whitespace는 우리가 정의하는 프로그래밍언어에 따라 의미가 생길 수도, 없을 수도 있다.
2) 10 === 010 ?
두가지를 동일하게 볼 것인가?
우리가 정의하는 프로그래밍언어의 설계에 따라 달라진다.
python에서는 int(10)는 10이고, int(010)은 8이다. int(0x10)은 16이다.
python 에서는 10 = decimal number system, 010 = octal number system, 0x10 = hexadecimal number system이기 때문이다.
5. 실습 : Ocaml 프로그램을 lexical analysis 해 보기!
1) regular expression
KW_LET : let
INDENT : [a-z] [0-9a-zA-Z'_]*
OP_EQ : =
INT : [1-9][0-9]*
KW_IN : in
KW_WILDCARD : _
LPAREN : \(
RPAREN : \)
2) input
let xyz = 3 in
let _ = foo xyz in
()
3) output
KW_LET (INDENT "xyz") OP_EQ (INT 3) KW_IN
KW_LET KW_WILDCARD OP_EQ (INDENT "foo") (INDENT "xyz") KW_IN
LPAREN RPAREN
