기본 구조 Tree & Heap
1. 트리(Tree)
- 트리: Node와 Branch를 이용해서, 사이클을 이루지 않도록 구성한 데이터 구조로 트리 중 이진 트리 (Binary Tree) 형태의 구조로, 탐색(검색) 알고리즘 구현을 위해 많이 사용됨
- 대용량 데이터 처리에 적합 - 트리는 항상 루트(Root)로부터 시작
- 루트는 자식(Child)노드를 가지며, 간선(Edge)로 연결되어 있다.
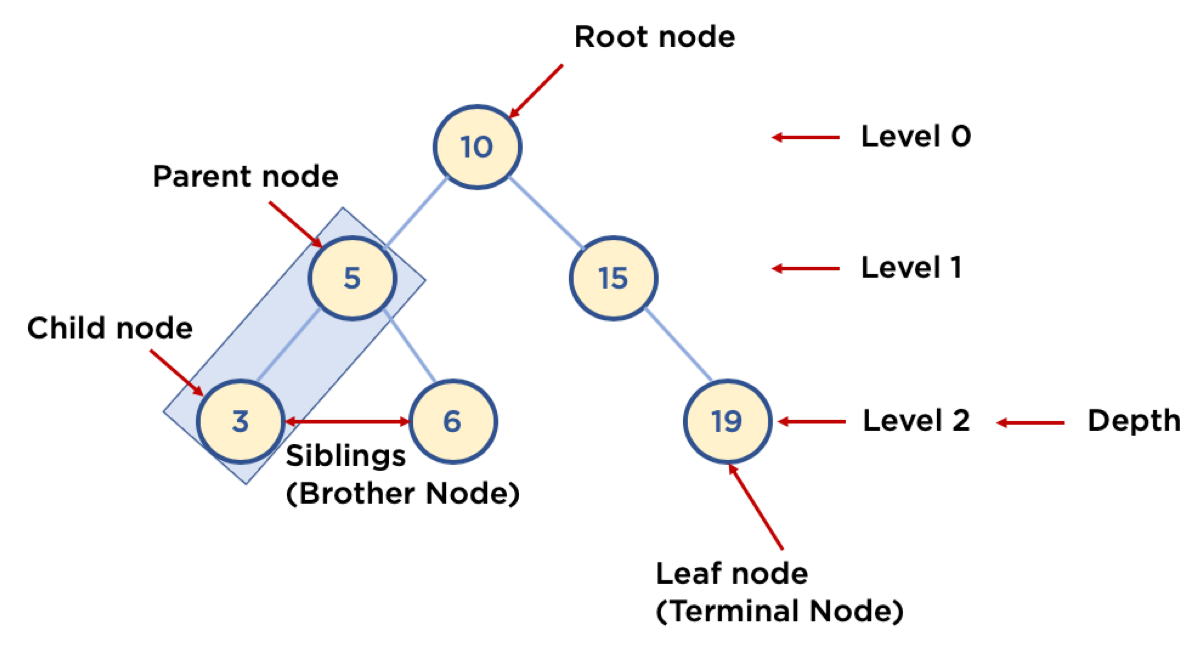
1. 용어
- Node: 트리에서 데이터를 저장하는 기본 요소 (데이터와 다른 연결된 노드에 대한 Branch 정보 포함)
- Root Node: 트리 맨 위에 있는 노드
- Level: 최상위 노드를 Level 0으로 했을 때, 하위 Branch로 연결된 노드의 깊이를 나타냄
- Parent Node: 어떤 노드의 다음 레벨에 연결된 노드
- Child Node: 어떤 노드의 상위 레벨에 연결된 노드
- Leaf Node (Terminal Node): Child Node가 하나도 없는 노드
- Sibling (Brother Node): 동일한 Parent Node를 가진 노드
- Depth: 트리에서 Node가 가질 수 있는 최대 Level
- 아래 그림 트리는 최대 레벨 2까지만 node를 가질 수 있음 (depth 2)
- 항상 위에서 아래로 연결됨 , 건너 뛰거나, 순환 안 됨
2. 이진 트리(Binary Tree)와 이진 탐색 트리 (Binary Search Tree)
- 이진 트리: 노드의 최대 Branch가 2인 트리
- 이진 탐색 트리 (Binary Search Tree, BST): 이진 트리에 다음과 같은 추가적인 조건이 있는 트리
- 왼쪽 노드는 해당 노드보다 작은 값, 오른쪽 노드는 해당 노드보다 큰 값을 가지고 있음!
3. 자료 구조 이진 탐색 트리의 장점과 주요 용도
- 이진트리에서 이진탐색트리가 가장 많이 쓰인다
- 주요 용도: 데이터 검색(탐색)
- 장점: 탐색 속도를 개선할 수 있음
4. 이진트리와 정렬된 배열간의 탐색 비교
- Tree는 node와 branch로 구성된 사이클이 없는 데이터 구조
- 이진트리는 node와 branch로 구성된 사이클이 없는 데이터 구조 + node가 가질 수 있는 최대 branch 개수가 2개
- 이진탐색트리는 node와 branch로 구성된 사이클이 없는 데이터 구조 + node가 가질 수 있는 최대 branch 개수가 2개 + branch 만들 때 자기보다 작으면 left, 크면 right에 넣는다
- 탐색에 유용
- 빠르게 data 넣을 수 있다
5 이진 탐색 트리 삭제
- 매우 복잡하다면,
경우를 나누어서 이해하는 것이 좋음
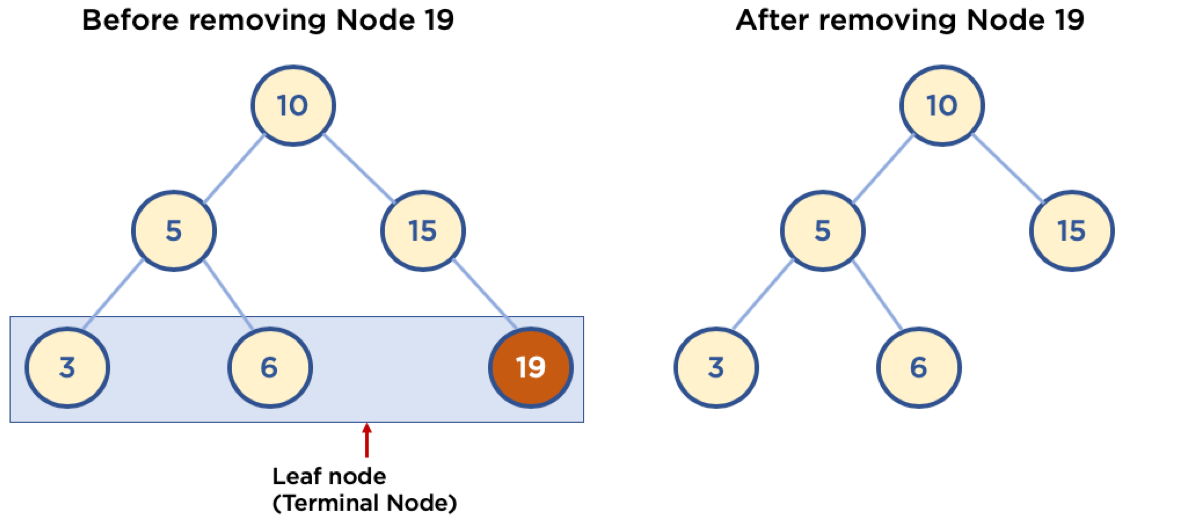
5-1 Leaf Node(Terminal Node) 삭제 (삭제할 Node의 branch가 없을 때)
- Leaf Node: Child Node 가 없는 Node
- 삭제할 Node의 Parent Node가 삭제할 Node를 가리키지 않도록 한다.
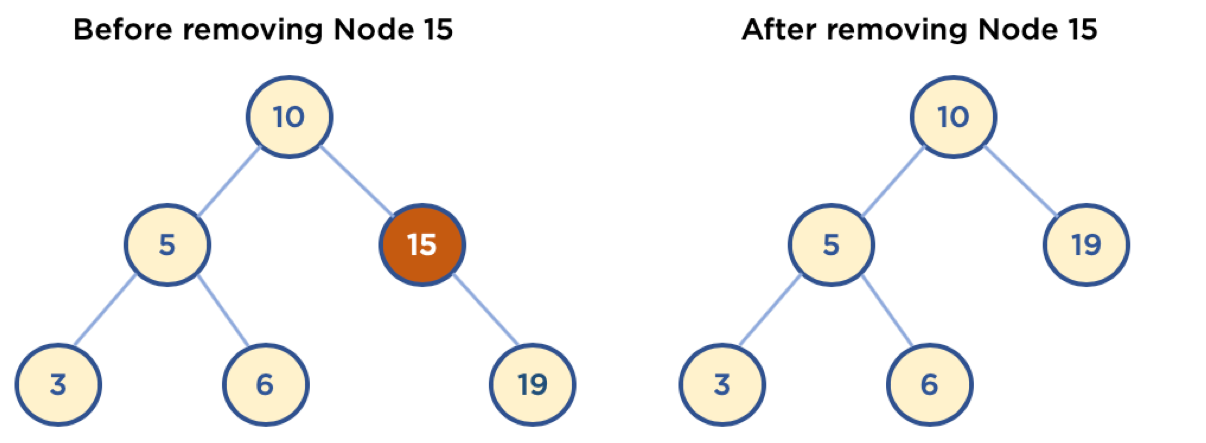
5-2 Child Node 가 하나인 Node 삭제
- 삭제할 Node의 Parent Node가 삭제할 Node의 Child Node를 가리키도록 한다.
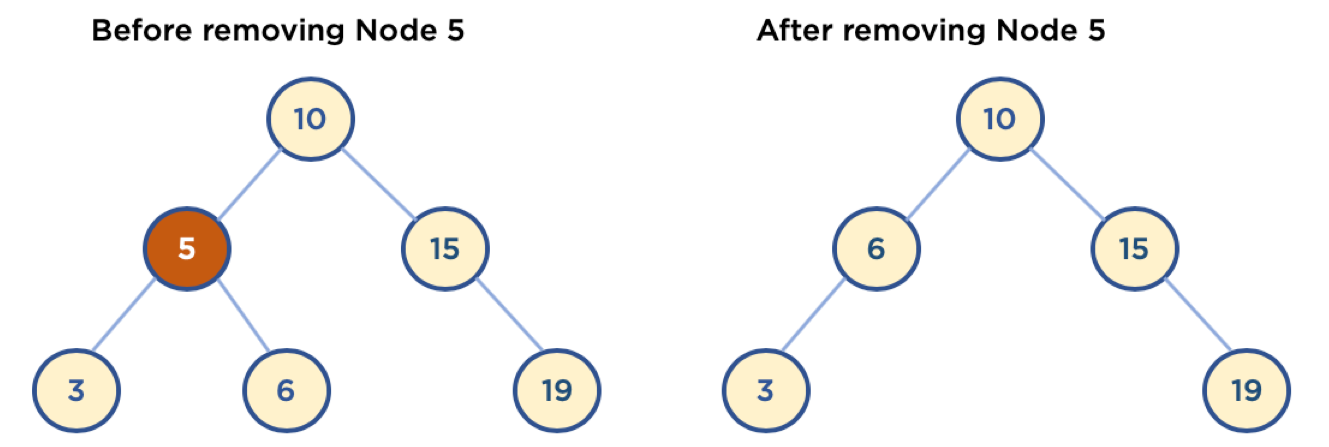
5-3 Child Node 가 두 개인 Node 삭제
- 삭제할 Node의 오른쪽 자식 중, 가장 작은 값을 삭제할 Node의 Parent Node가 가리키도록 한다.
- 삭제할 Node의 왼쪽 자식 중, 가장 큰 값을 삭제할 Node의 Parent Node가 가리키도록 한다.
5-4 삭제할 Node의 오른쪽 자식중, 가장 작은 값을 삭제할 Node의 Parent Node가 가리키게 할 경우
- 삭제할 Node의 오른쪽 자식 선택
- 오른쪽 자식의 가장 왼쪽에 있는 Node를 선택
- 해당 Node를 삭제할 Node의 Parent Node의 왼쪽 Branch가 가리키게 함
- 해당 Node의 왼쪽 Branch가 삭제할 Node의 왼쪽 Child Node를 가리키게 함
- 해당 Node의 오른쪽 Branch가 삭제할 Node의 오른쪽 Child Node를 가리키게 함
- 만약 해당 Node가 오른쪽 Child Node를 가지고 있었을 경우에는, 해당 Node의 본래 Parent Node의 왼쪽 Branch가 해당 오른쪽 Child Node를 가리키게 함
5-5 삭제할 Node 탐색
- 삭제할 Node가 없는 경우도 처리해야 함
- 이를 위해 삭제할 Node가 없는 경우는 False를 리턴하고, 함수를 종료 시킴
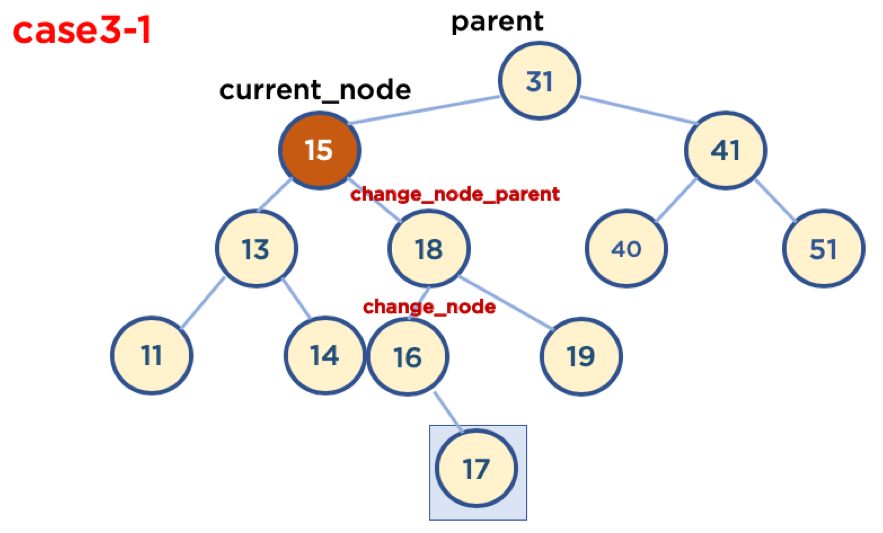
5-6 Case3-1: 삭제할 Node가 Child Node를 두 개 가지고 있을 경우 (삭제할 Node가 Parent Node 왼쪽에 있을 때)
- 기본 사용 가능 전략
- 삭제할 Node의 오른쪽 자식 중, 가장 작은 값을 삭제할 Node의 Parent Node가 가리키도록 한다.
- 삭제할 Node의 왼쪽 자식 중, 가장 큰 값을 삭제할 Node의 Parent Node가 가리키도록 한다.
- 기본 사용 가능 전략 중, 1번 전략을 사용하여 코드를 구현하기로 함
- 경우의 수가 또다시 두가지가 있음
- Case3-1-1: 삭제할 Node가 Parent Node의 왼쪽에 있고, 삭제할 Node의 오른쪽 자식 중, 가장 작은 값을 가진 Node의 Child Node가 없을 때
- Case3-1-2: 삭제할 Node가 Parent Node의 왼쪽에 있고, 삭제할 Node의 오른쪽 자식 중, 가장 작은 값을 가진 Node의 오른쪽에 Child Node가 있을 때
- 가장 작은 값을 가진 Node의 Child Node가 왼쪽에 있을 경우는 없음, 왜냐하면 왼쪽 Node가 있다는 것은 해당 Node보다 더 작은 값을 가진 Node가 있다는 뜻이기 때문임
- 경우의 수가 또다시 두가지가 있음
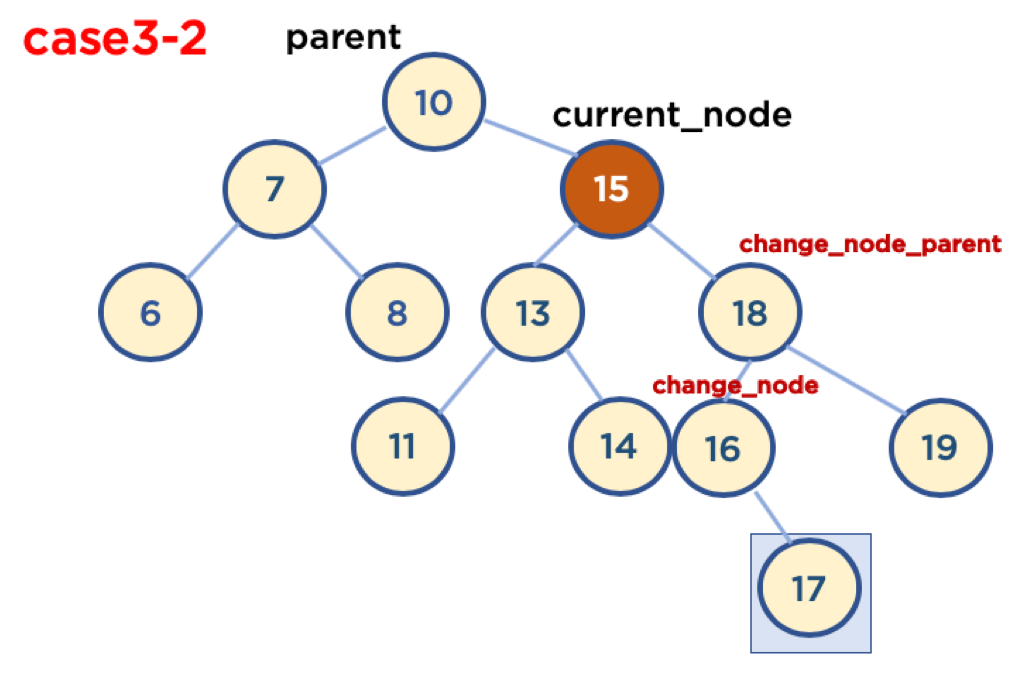
5-7 Case3-2: 삭제할 Node가 Child Node를 두 개 가지고 있을 경우 (삭제할 Node가 Parent Node 오른쪽에 있을 때)
- 기본 사용 가능 전략
- 삭제할 Node의 오른쪽 자식 중, 가장 작은 값을 삭제할 Node의 Parent Node가 가리키도록 한다.
- 삭제할 Node의 왼쪽 자식 중, 가장 큰 값을 삭제할 Node의 Parent Node가 가리키도록 한다.
- 기본 사용 가능 전략 중, 1번 전략을 사용하여 코드를 구현하기로 함
- 경우의 수가 또다시 두가지가 있음
- Case3-2-1: 삭제할 Node가 Parent Node의 오른쪽에 있고, 삭제할 Node의 오른쪽 자식 중, 가장 작은 값을 가진 Node의 Child Node가 없을 때
- Case3-2-2: 삭제할 Node가 Parent Node의 오른쪽에 있고, 삭제할 Node의 오른쪽 자식 중, 가장 작은 값을 가진 Node의 오른쪽에 Child Node가 있을 때
- 가장 작은 값을 가진 Node의 Child Node가 왼쪽에 있을 경우는 없음, 왜냐하면 왼쪽 Node가 있다는 것은 해당 Node보다 더 작은 값을 가진 Node가 있다는 뜻이기 때문임
- 경우의 수가 또다시 두가지가 있음
6. 이진 탐색 트리의 시간 복잡도와 단점
6.1. 시간 복잡도 (탐색시)
- depth (트리의 높이) 를 h라고 표기한다면, O(h)
- n개의 노드를 가진다면, h = log_2{n} $ 에 가까우므로, 시간 복잡도는 $ O(log{n}) $ - 참고: 빅오 표기법에서 $log{n} 에서의 log의 밑은 10이 아니라, 2입니다.
- 한번 실행시마다, 50%의 실행할 수도 있는 명령을 제거한다는 의미. 즉 50%의 실행시간을 단축시킬 수 있다는 것을 의미함
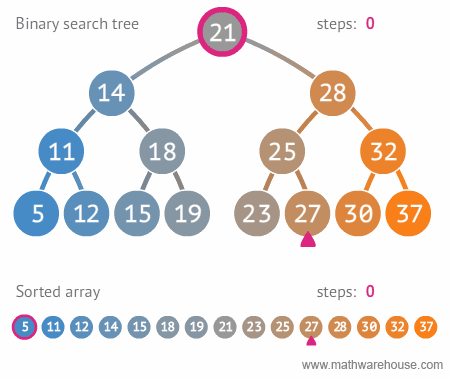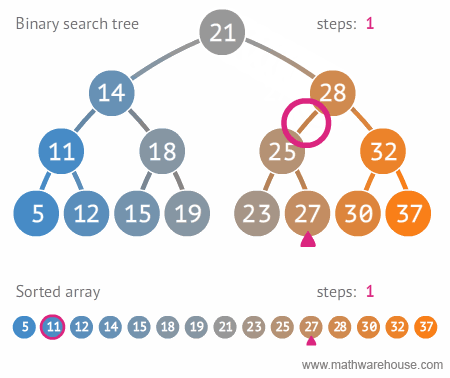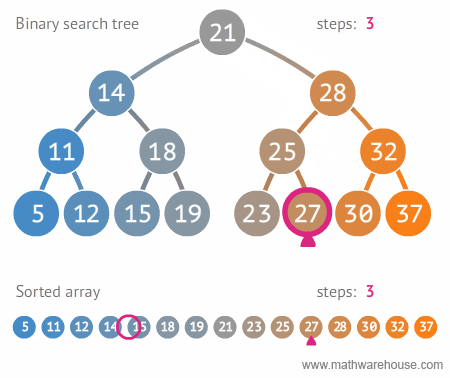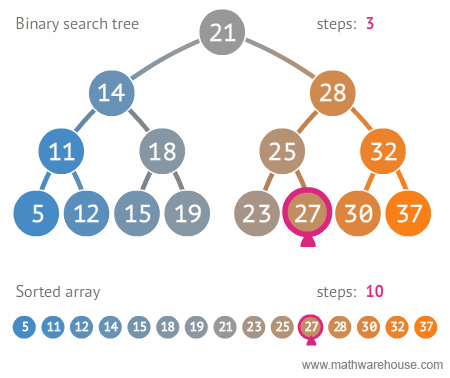
6.2. 이진 탐색 트리 단점
- 평균 시간 복잡도는 $ O(log{n}) $ 이지만,
- 이는 트리가 균형잡혀 있을 때의 평균 시간복잡도이며,
- 다음 예와 같이 구성되어 있을 경우, 최악의 경우는 링크드 리스트등과 동일한 성능을 보여줌 ( )
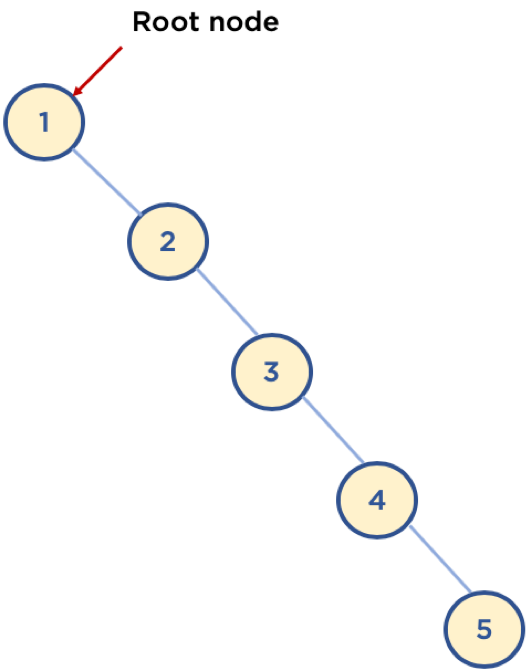
2.힙(Heap)
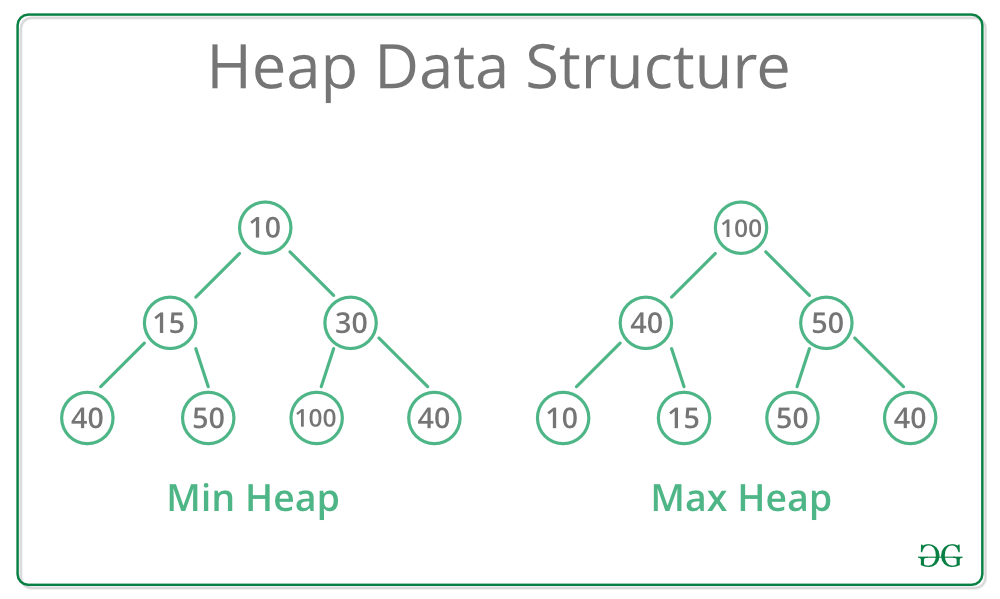
- 우선순위 큐를 구현하기 위해 사용하는 자료구조 중 하나
- 완전 이진 트리의 일종으로, 항상 부모 값 < 자식 값
- 루트는 최댓값 이거나 최솟값
- 우선순위 큐 ADT(추상 자료형)는 주로 힙으로 구현되고, 힙은 주로 배열로 구현되기에 우선순위 큐 ADT(추상 자료형)는 배열로 구현됨
- 정렬된 구조가 아님
-최소 힙의 경우 부모 노드가 항상 작다는 조건만 만족할 뿐 서로 정렬되어 있지 않다
최소힙 (Min Heap) 과 최대힙 (Max Heap)
- 최소힙 : '값이 낮은 데이터가 먼저 삭제' 되는 경우
- 최대힙 : '값이 큰 데이터가 먼저 삭제' 되는 경우
우선순위 큐 구현 방식
| 우선순위 큐 구현방식 | 삽입시간 | 삭제 시간 |
|---|---|---|
| 리스트 | O(1) | O(N) |
| 힙(heap) | O(logN) | O(logN) |
- 힙을 사용하는 경우 모든 원소를 저장한 뒤 우선순위에 맞게 빠르게 뽑아낼 수 있으므로 '우선순위 큐'를 구현하는데 가장 많이 사용

🧑🏻💻 비전공자의 개발자 도전기