2.1 자연어 처리란
한국어와 영어 등 우리가 평소에 쓰는 말을 자연어라고 한다. 차연어 쳐리(NLP)를 풀어서 말하면 '우리의 말을 컴퓨터에게 이해시키기 위한 기술(분야)'이다.
자연어 처리가 추구하는 목표는 사람의 말을 부드럽게 컴퓨터가 이해하도록 만들어서, 컴퓨터가 우리에게 도움이 되는 일을 수행하게 하는 것이다.
2.1.1 단어의 의미
우리의 말은 '문자로'로 구성되며, 말의 의미는 '단어'로 구성된다. 단어는 의미의 최소 단위이기 때문에 자연어를 컴퓨터에게 이해시키는 데는 '단어의 의미'를 이해시키는 것이 중요하다.
이번 장과 다음 장에서 다음의 세 가지 기법을 살펴보겠다.
- 시소러스를 활용한 기법 (이번 장)
- 통계 기반 기법 (이번 장)
- 추론 기반 기법(word2vec) (다음 장)
2.2 시소러스
시소러스란 유의어 사전으로, '뜻이 같은 단어(동의어)'나 '뜻이 비슷한 단어(유의어)'가 한 그룹으로 분류되어 있다.

또한 자연어 처리에 이용되는 시소러스에서는 단어 사이의 '상위와 하위' 혹은 '전체와 부분' 등, 더 세세한 관계까지 정의해둔 경우도 있다.
밑의 그림처럼 각 단어의 관계를 그래프 구조로 정의한다.
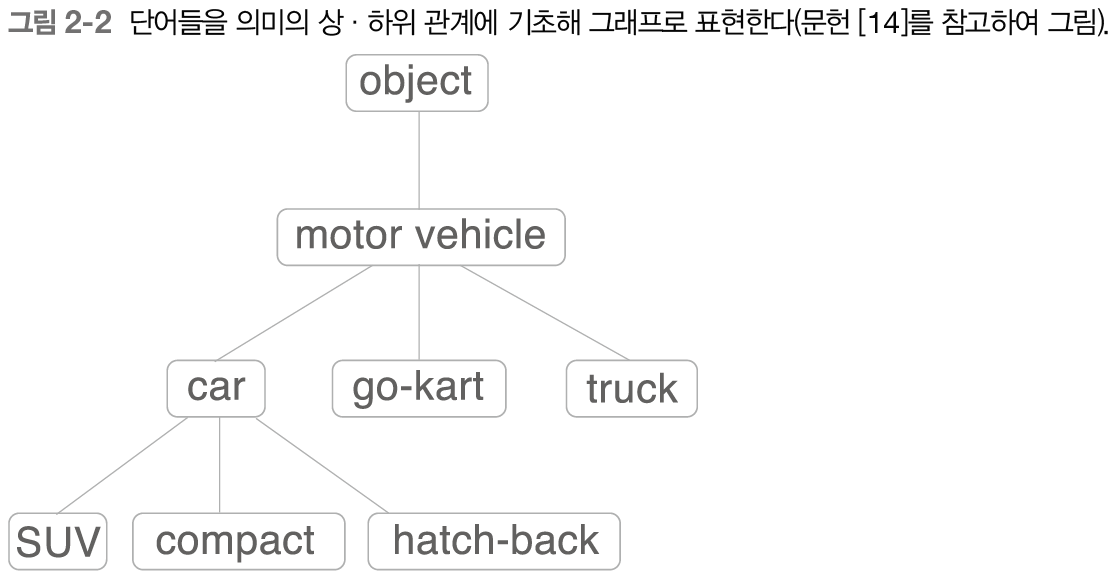
'car'의 상위 개념으로 'motor vehicle'이라는 단어가 존재하며 하위 개념으로 'SUV', 'compact', 'hatch-back' 등 구체적인 차종이 있다.
이처럼 '단어 네트워크'를 이용하여 컴퓨터에게 단어의 관계를 가르쳐줄 수 있다.
2.2.1 WordNet
자연어 처리 분야에서 가장 유명한 시소러스는 WordNet이다. WordNet을 사용하면 유의어를 얻거나 '단어 네트워크'를 이용할 수 있다.
2.2.2 시소러스의 문제점
WordNet과 같은 시소러스에는 수많은 단어에 대한 동의어와 계층 구조 등의 관계가 정의되어 있다. 그리고 이 지식을 이용하면 '단어의 의미'를 컴퓨터에 전달할 수 있다.
하지만 사람이 수작업으로 레이블링하는 방식에는 문제들이 존재한다.
- 시대 변화에 대응하기 어렵다. 신조어 혹은 의미 변화된 단어들을 바로 적용 시키기 어렵다.
- 사람을 쓰는 비용이 든다. 현존하는 영어 단어의 수는 1,000만 개가 넘으며 WordNet에 등록된 단어는 20만 개 이상이다.
- 단어의 미묘한 차이를 표현할 수 없다. 가령, 빈티지와 레트로의 의미는 같으나 용법의 차이가 존재한다.
위 문제점들을 피하기 위해 '통계 기반 기법'과 신경망을 사용한 '추론 기반 기법'을 알아볼 것이다.
2.3 통계 기반 기법
통계 기반 기법을 살펴보면서 말뭉치, 즉 대량의 텍스트 데이터를 이용할 것이다.
2.3.1 파이썬으로 말뭉치 전처리하기
자연어 처리에는 다양한 말뭉치가 사용되는데 예로는 구글 뉴스와 위키백과 등의 텍스트 데이터를 들 수 있다.
<코드 따라하기>
2.3.2 단어의 분산 표현
색에는 고유한 이름이 붙여진 다채로운 색들도 있고, RGB(Red/Green/Blue)라는 세가지 성분이 어떤 비율로 섞여 있느냐로 표현하는 방법이 있다. 전자는 색의 가짓수만큼 의 이름을부여하는 반면에 후자는 색을 3차원의 벡터로 표현한다.
여기서 주목할 점은 RGB같은 벡터 표현이 단 3개의 성분으로 간결하게 표현할 수 있고, 색을 더 정확하게 명시할 수 있다는 점이다.
'색'을 벡터로 표현하듯 '단어'도 벡터로 표현할 수 있다. 이를 단어의 '분산 표현'이라고 한다.
2.3.3 분포 가설
분포 가설이란 단어의 의미는 주변 단어에 의해 형성된다는 것이다. 분포 가설이 말하고자 하는 것은 단어 자체에는 의미가 없고, 그 단어가 사용된 '맥락'이 의미를 형성한다는 것이다.
예를 들어, I drink beer를 I guzzle beer라고 해도 guzzle을 drink로 이해할 수 있다는 것이다.

위 그림에서 goodbye를 기준으로 좌우의 두 단어씩이 '맥락'에 해당한다. 맥락의 크기를 '윈도우 크기'라고 한다. 여기서는 '위도우 크기'가 2이기 때문에 좌우로 두 단어씩이 맥락에 포함된다.
2.3.4 동시발생 행렬
분포 가설에 기초해 단어를 벡터로 나타내는 방법을 생각해보면 주변 단어를 세어보는 방법이 떠오를 것이며 이를 '통계 기반'기번이라고 한다.

단어가 총 7개이며 윈도우 크기는 1로 하고 단어 ID가 0인 'you'부터 단어의 맥락에 해당하는 단어의 빈도를 세어보겠다.
'you'의 맥락은 'say'라는 단어 하나뿐이다.
표로 정리하면 밑에 그림과 같다.
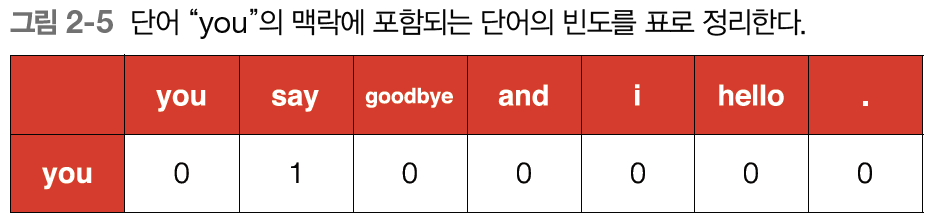
'you'의 맥락으로써 동시에 발생하는 단어의 빈도를 나타낸 것이며 벡터로 표현하면 [0, 1, 0, 0, 0, 0, 0]이다.
그 다음 단어인 'say'로 같은 작업을 수행하면 밑의 그림과 같다.
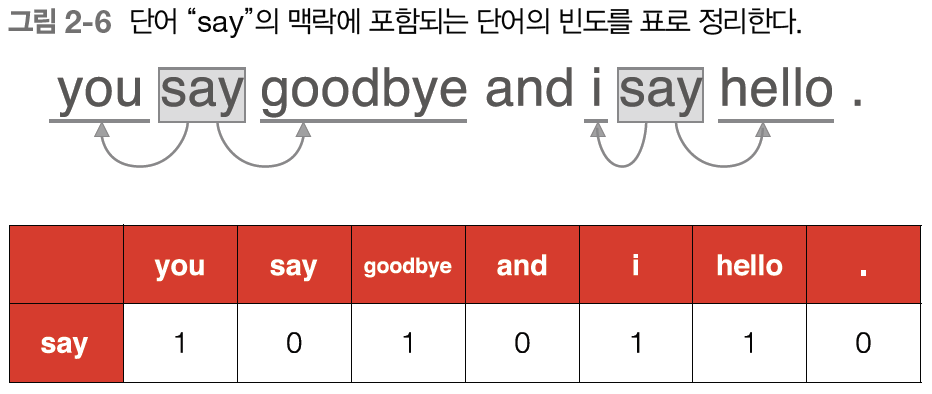
'say'라는 단어는 벡터 [1, 0, 1, 0, 1, 1, 0]으로 표현할 수 이다.
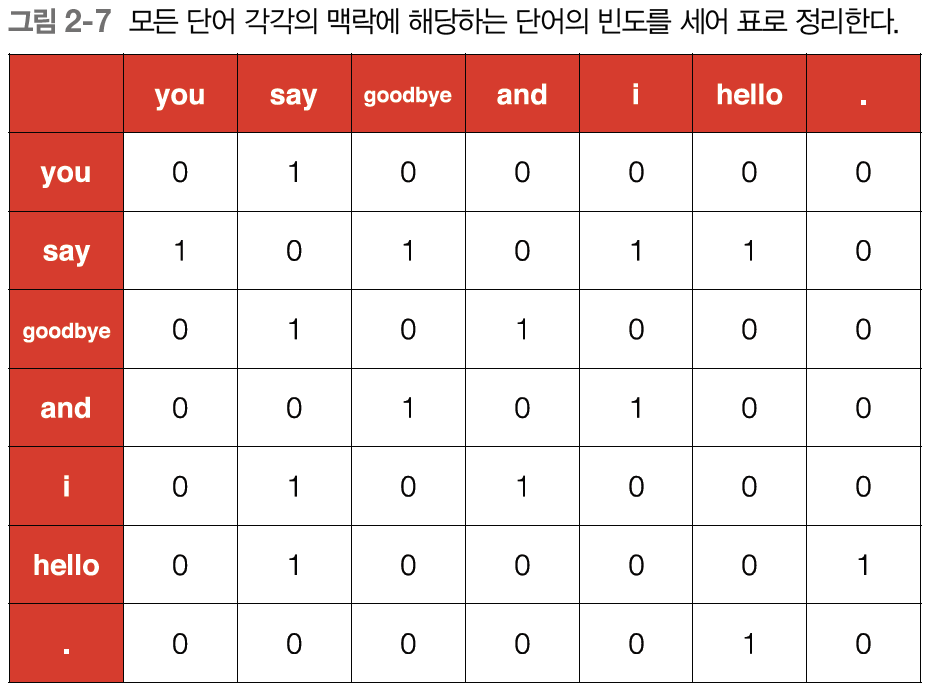
위의 표는 모든 단어에 대해 동시발생하는 단어를 표에 정리한 것이다. 위 표의 각 행은 벡터이며 행렬의 형태를 띄어 동시발생 행렬이라 한다.
2.3.5 벡터 간 유사도
단어 벡터의 유사도를 나타낼 때는 코사인 유사도를 자주 이용한다.
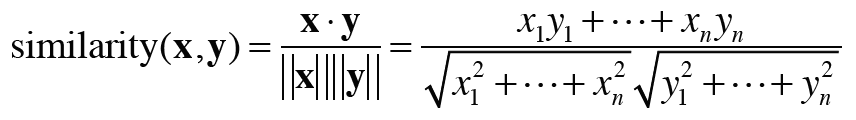
위의 식처럼 정의되며 분자에는 벡터의 내적이 분모에는 벡터의 노름(크기)이 등장한다. 위 식의 핵심은 벡터를 정규화하고 내적을 구하는 것이다.
2.3.6 유사 단어의 랭킹 표시
코사인 유사도를 이용하여 어떤 단어가 주어지면, 그 검색어와 비슷한 단어를 유사도 순으로 출력하는 함수를 만들어 본다.
이를 구현하기 위한 코드에는 밑에 같은 함수의 인수들이 쓰인다.

<책의 코드를 따라한다.>
코드를 따라할 때 는 다음 순서로 동작한다.
1. 검색어의 단어 벡터를 꺼낸다.
2. 검색어의 단어 벡터와 다른 모든 단어 벡터와의 코사인 유사도를 각각 구한다.
3. 계산한 코사인 유사도 결과를 기준으로 값이 높은 순서대로 출력한다.
동시발생 행렬을 이용하면 단어를 벡터로 표현할 수 있다.
2.4 통계 기바 기법 개선하기
2.4.1 상호정보량
동시발생 행렬의 원소는 두 단어가 동시에 발생한 횟수를 나타내지만 '발생' 횟수라는 것은 사실 좋은 특징이 아니다.
예를 들어 'the' 와 'car'의 동시발생을 생각해보자. '...the car...'라는 문구가 자주 보일 것이며 'car'와 'drive'는 관련이 깊다. 하지만 'the'가 고빈도 단어이기 때문에 'car'와 더 관련이 있어 보이게 결과가 나올 수 있다.
이를 해결하기 위해 점별 상호정보량이라는 척도를 사용한다. PMI는 확률 변수 x와 y에 대해 다음 식으로 정의 된다.
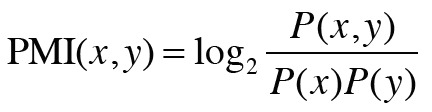
P(x)는 x가 일어날 확률, P(y)는 y가 일어날 확률, P(x,y)는 x,y가 동시에 일어날 확률이다. PMI값이 높을수록 관련성이 높다는 의미이다.
위 식을 다시 정리하면 밑에 식처럼 표현된다.
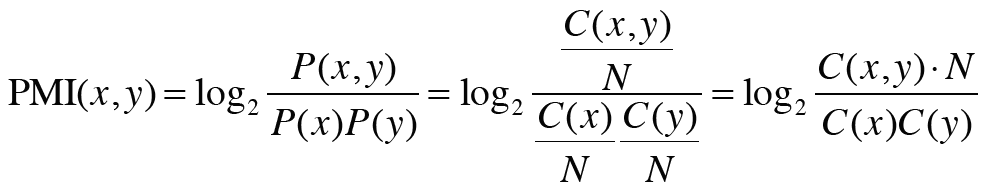
여기서 C는 동시발생 행렬, C(x,y)는 단어 x와 y가 동시발생하는 횟수, C(x)와 C(y)는 각각 단어 x와 y의 등장 횟수이며 N은 말뭉치에 포함된 단어 수이다.
이 식을 토대로 1,000번 등장한 'the', 20번 등장한 'car'와 10번 등장한 'drive'를 계산해보자.
우선 'the'와 'car'의 동시발생 수가 10회라면 PMI 결과는 다음과 같다.
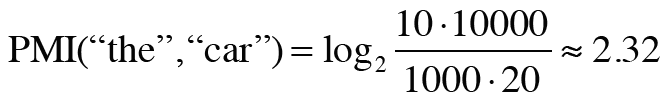
그 다음으로 'car'와 'drive'의 동시발생 수가 5라면 PMI 결과는 다음과 같다.
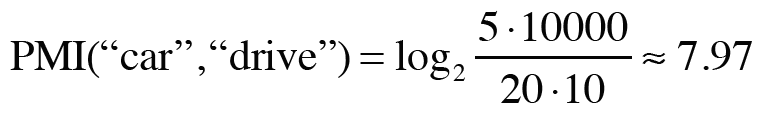
두 PMI의 결과를 살펴보면 'car'와 'drvie'의 관계성이 강하다는 것을 볼 수 있다. 이러한 결과가 나온 이유는 단어가 단독으로 출현하는 횟수가 고려되었기 때문이다. 이 예에서는 'the'가 자주 출현하였기 때문에 PMI값이 낮아진 것이다.
하지만 PMI에도 문제가 하나 있다. 이는 두 단어의 동시발생 횟수가 0이면 log(0,2) = -infinite가 된다. 이 문제를 피하기 위해 실제 구현할 때는 양의 상호정보량(PPMI)를 사용한다.
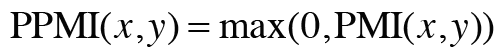
이 식에 따라 PMI가 음수인 때는 0으로 취급하며 단어 사이의 관련성을 0 이상의 실수로 나타낼 수 있다.
하지만 PPMI 행렬에도 문제가 있는데 말뭉치의 어휘 수가 증가함에 따라 각 단어 벡터의 차원 수도 증가한다는 문제이다. 이 문제를 대처하고자 자주 수행하는 기법이 '벡터의 차원 감소'이다.
2.4.2 차원 감소
차원 감소는 벡터의 차원을 '중요한 정보'는 최대한 유지하면서 줄이는 방법을 말한다.
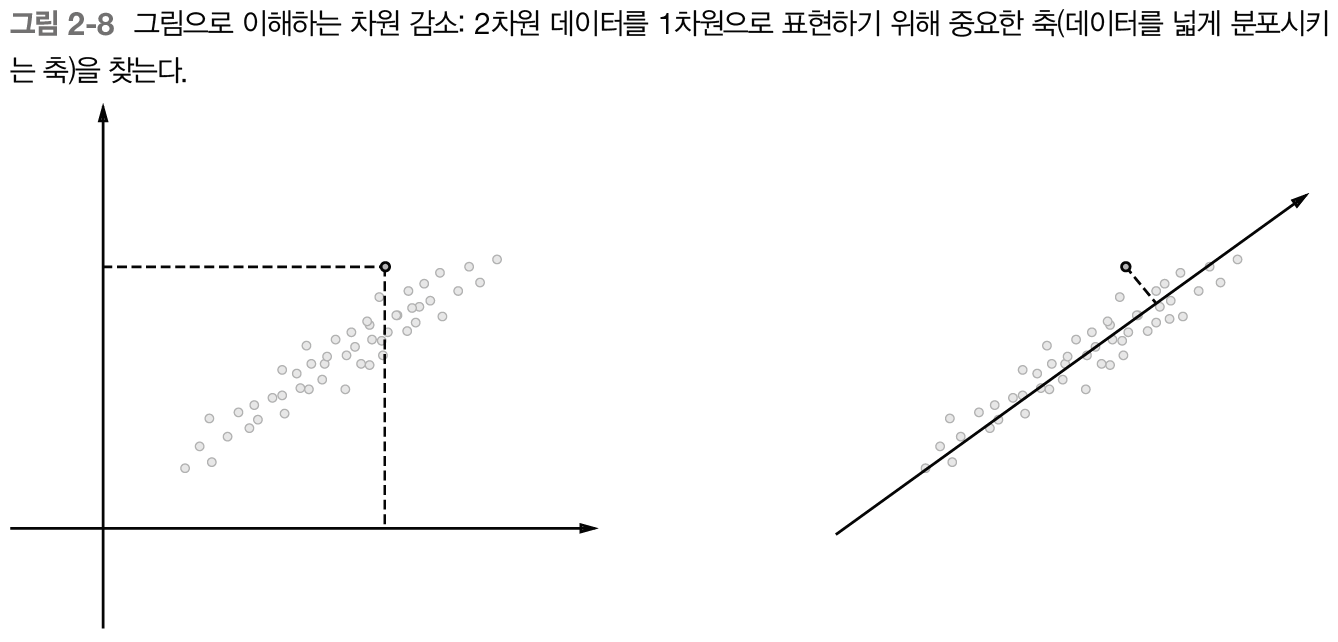
위의 그림 예시처럼 데이터의 분포를 고려해 중요한 '축'을 찾는 일을 수행한다. 왼쪽 그림은 데이터점들을 2차원 좌표에 표시한 모습이고 오른쪽 그림은 새로운 축을 도입하여 똑같은 데이터를 촤표축 하나만으로 표시했다.
여기서 중요한 것은 가장 적합한 축을 찾아내는 일로, 1차원 값만으로 데이터의 본직적인 차이를 구별할 수 있어야 한다. 그리고 다차원 데이터에 대해서도 수행 가능하다.
차원을 감소시키는 방법 중 하나인 특잇값분해(SVD)는 임의의 행렬을 세 행렬의 곱으로 분해하며, 수식으로는 다음과 같다.
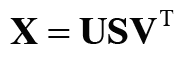
SVD는 임의의 행렬 X를 U,S,V라는 세 행렬의 곱으로 분해한다.
U와 V는 직교행렬이고 열벡터는 서로 직교한다. S는 대각행렬이다.

행렬 S에서 특잆값이 작다면 중요도가 낮다는 뜻이므로 행렬 U에서 여분의 열벡터를 깎아내려 원래의 행렬을 근사할 수 있다.
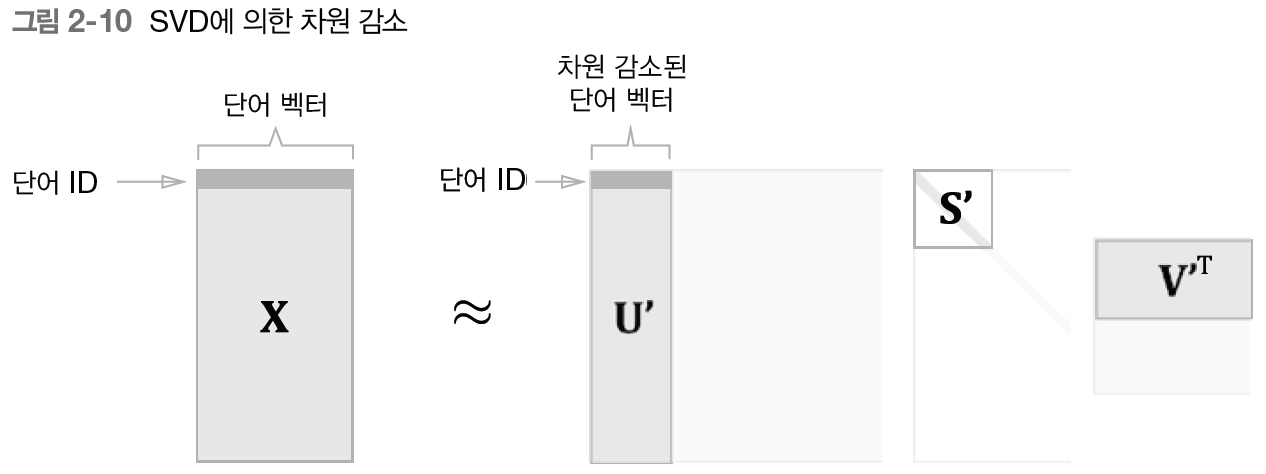
이를 '단어의 PPMI 행렬'에 적용하면 행렬 X의 각 행에는 해당 당너 ID의 단어 벡터가 저장되어 있으며, 그 단어 벡터가 행렬 U'라는 차원 감소된 벡터로 표현된다.
2.4.3 SVD에 의한 차원 감소
SVD는 넘파이의 linalg 모듈이 제공하는 svd 메서드로 실행 가능하다.
<코드 따라하기>
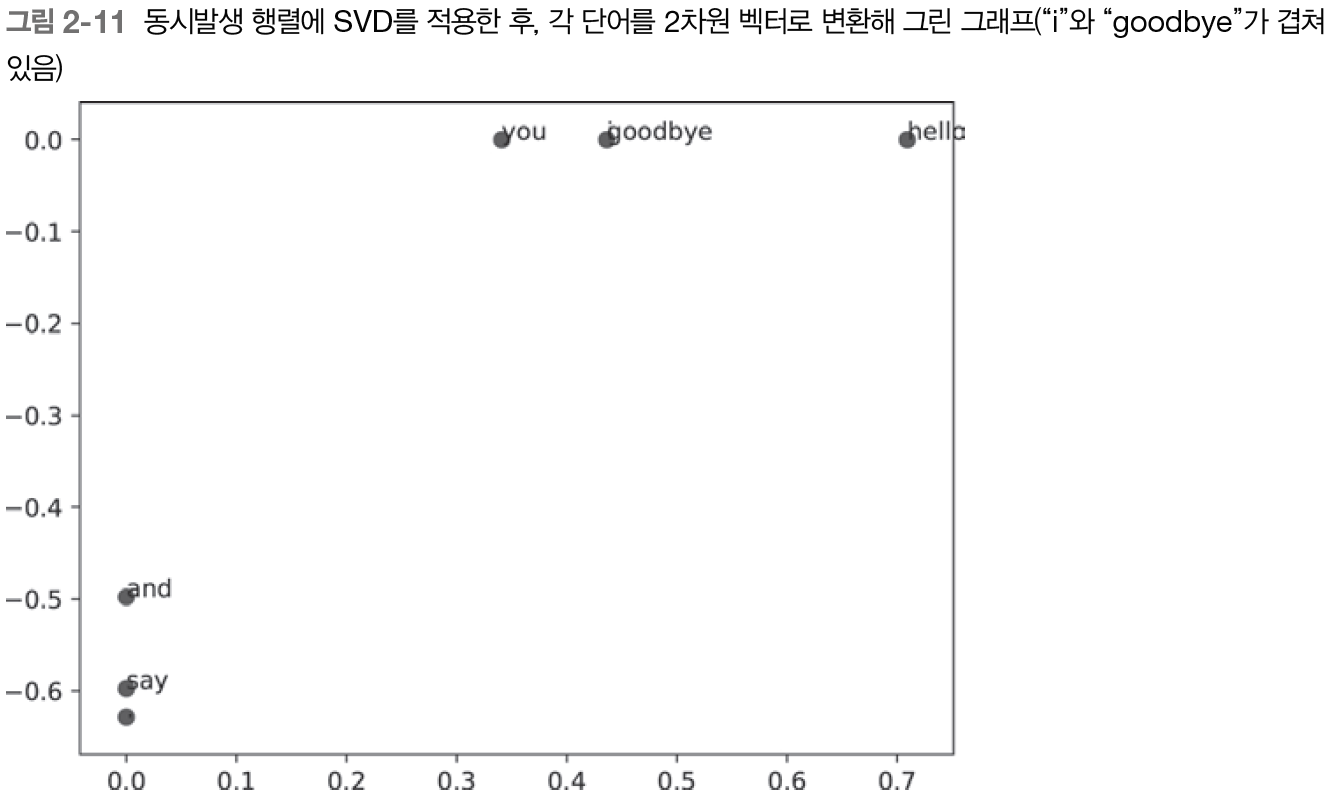
코드를 돌린 결과 위의 그림이 나온다. 'goodbye'와 'hello', 'you'와 'i'가 제법 가까이 있음을 알 수 있다. 하지만 지금 사용한 말뭉치가 작기 때문에 PTB 데이터셋이라는 더 큰 말뭉치를 사용하여 똑같은 실험을 수행해보자.
2.4.4 PTB 데이터셋
우리가 사용할 PTB(펜 트리뱅크) 말뭉치는 word2vec의 발명자인 토마스 미콜로프의 웹 페이지에서 받을 수 있다.
<코드 따라하기>
결과적으로 말뭉치를 사용해 맥락에 속한 단어의 등장 횟수를 센 후 PPMI 행렬로 변환하고 다시 SVD를 이용해 차원을 감소시킴으로서 더 좋은 단어 벡터를 얻었다. 이것이 단어의 분산 표현이고, 각 단어는 고정 길이의 밀집벡터로 표현되었다.
