밑바닥부터 시작하는 딥러닝2
1.[밑바닥부터 시작하는 딥러닝2] 3장. word2vec

밑바닥부터 시작하는 딥러닝2 github 이번 장의 주제도 단어의 분산 표현이다. 앞 장에서는 통계 기반 기법으로 단어의 분산 표현을 얻었는데, 이번 장에서는 더 강력한 기법인 추론 기반 기법을 살펴본다. 추론 기반 기법의 추론 과정에서 신경망을 이용한다. 여기서 word2vec 이 등장한다. 이번 장에서는 word2vec 의 구조를 차분히 들여다보고 ...
2.밑바닥부터 시작하는 딥러닝2 - 2장
2.1 자연어 처리란 한국어와 영어 등 우리가 평소에 쓰는 말을 자연어라고 한다. 차연어 쳐리(NLP)를 풀어서 말하면 '우리의 말을 컴퓨터에게 이해시키기 위한 기술(분야)'이다. 자연어 처리가 추구하는 목표는 사람의 말을 부드럽게 컴퓨터가 이해하도록 만들어서, 컴퓨터가 우리에게 도움이 되는 일을 수행하게 하는 것이다. 2.1.1 단어의 의미 우리의 말은...
3.밑바닥 부터 시작하는 딥러닝2 - 4장
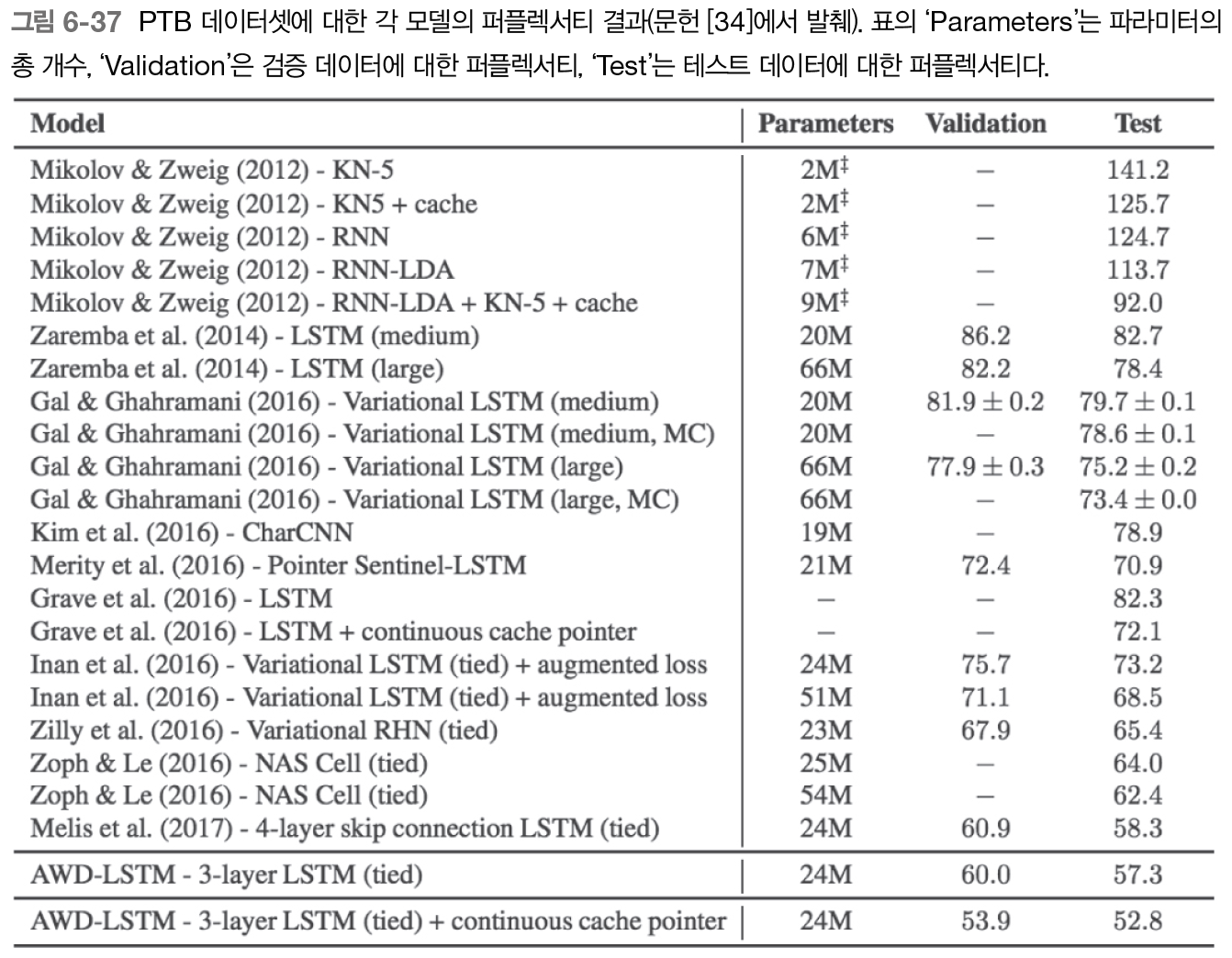
이번 4장에서는 word2vec의 속도 개선하는 법을 알아보겠다. 앞서 3장에서 보았던 CBOW(Continuous Bag of Words) 모델은 처리 효율이 떨어져 말뭉치에 포함된 어휘 수가 많아지면 계산량도 커진다. 따라서, 단순한 word2vec에 두가지 개선을 추가한다. Embedding 이라는 새로운 계층을 만든다. 네거티브 샘플링 이라는 ...
4.[밑바닥부터 시작하는 딥러닝2] 7장. RNN을 사용한 문장 생성
7.1 언어 모델을 사용한 문장 생성 5장,6장에서는 RNN 과 LSTM 을 자세하게 살펴봤다. 이번 장에서는 LSTM을 이용할 것이다. 이번 장에서는 언어 모델을 사용해 문장 생성을 수행한다. 구처젝으로는 우선 말뭉치를 사용해 학습한 언어 모델을 이용하여 새로운 만장을 만들어낸다. 그런 다음 개선된 언어 모델을 이용하여 더 자연스러운 문장을 생성해보겠...
5.밑바닥부터 시작하는 딥러닝2 - 5장
CHAPTER5 순환신경망(RNN) 피드포워드(feed forword) 신경망 흐름이 단방향 시계열 데이터의 성질(패턴)을 충분히 학습할 수 없음 순환 신경망(Recurrent Neural Network, RNN)의 등장 5.1 확률과 언어 모델 5.1.1 wor
6.밑바닥부터 시작하는 딥러닝2 - 8장
seq2seq 란, 2개의 RNN 을 연결하여 하나의 시계열 데이터를 다른 시계열 데이터로 변환하는 것이다.이번 장에서는, seq2seq 와 RNN 의 가능성을 높여주는, 어탠션 이라는 기술에 대해 학습해보자.어탠션 매커니즘은 seq2seq 를 더 강력하게 해준다. s
7.밑바닥부터 시작하는 딥러닝2 - 6장
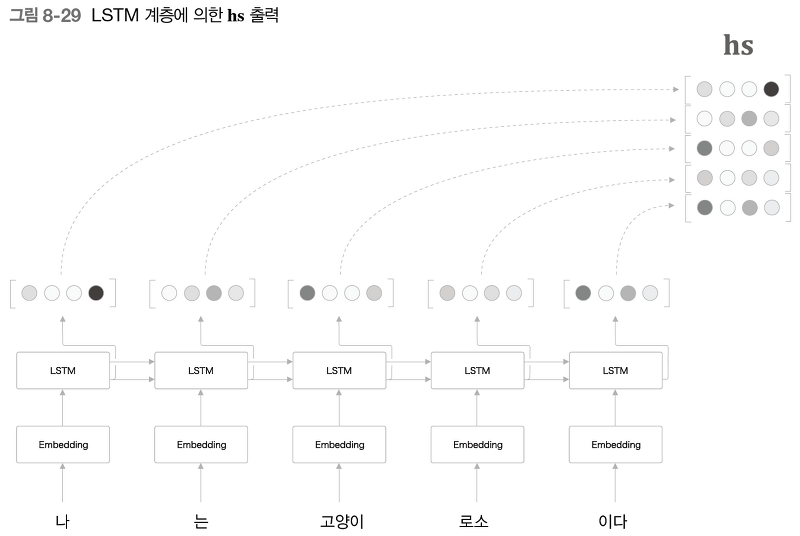
게이트가 추가된 RNN 5장에서 본 RNN은 순환 경로를 포함하여 과거의 정보를 기억할 수 있으며 구조가 단순하여 구현도 쉽게 할 수 있었다. 하지만 성능이 좋지 못하였는데 그 원인은 시계열 데이터에서 시간적으로 멀리 떨어진, 즉 장기 의존 관계를 잘 학습할 수 없기