게이트가 추가된 RNN
5장에서 본 RNN은 순환 경로를 포함하여 과거의 정보를 기억할 수 있으며 구조가 단순하여 구현도 쉽게 할 수 있었다. 하지만 성능이 좋지 못하였는데 그 원인은 시계열 데이터에서 시간적으로 멀리 떨어진, 즉 장기 의존 관계를 잘 학습할 수 없기 때문이다.
6.1 RNN의 문제점
RNN은 시계열 데이터의 장기 의존 관계를 학습하기 어렵다. 그 이유는 BPTT에서 기울기 소실 혹은 기울기 폭발이 일어나기 때문이다.
6.1.1 RNN 복습
RNN 계층은 순환 경로를 갖고 있다. 이 순환 경로를 펼치면 밑의 그림과 같다.
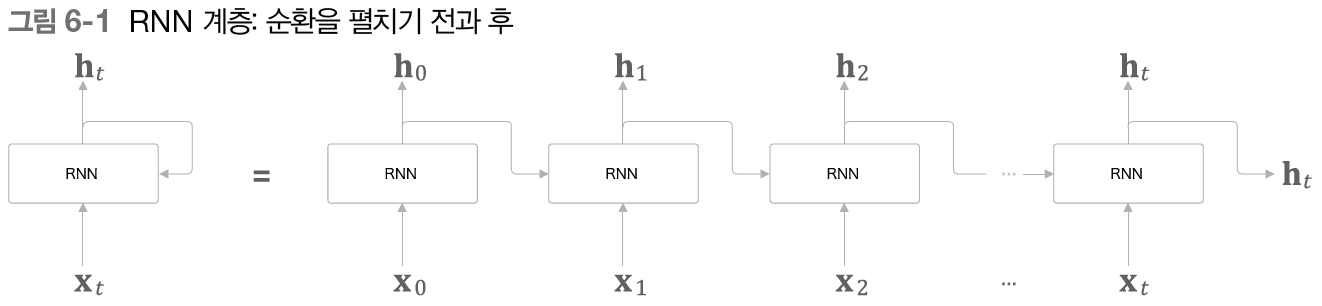
[그림 6-1]에서 보듯, RNN 계층은 시계열 데이터인 xi를 입력하면 hi를 출력한다. hi는 RNN 계층의 은닉 상태라 하여 과거 정보를 저장한다.
RNN의 특징은 바로 이전 시각의 은닉 상태를 이용한다. 이렇게 해서 과거 정보를 계승할 수 있게 된다. RNN 계층이 수행하는 처리를 계산 그래프로 나타내면 밑의 그림처럼 나타난다.
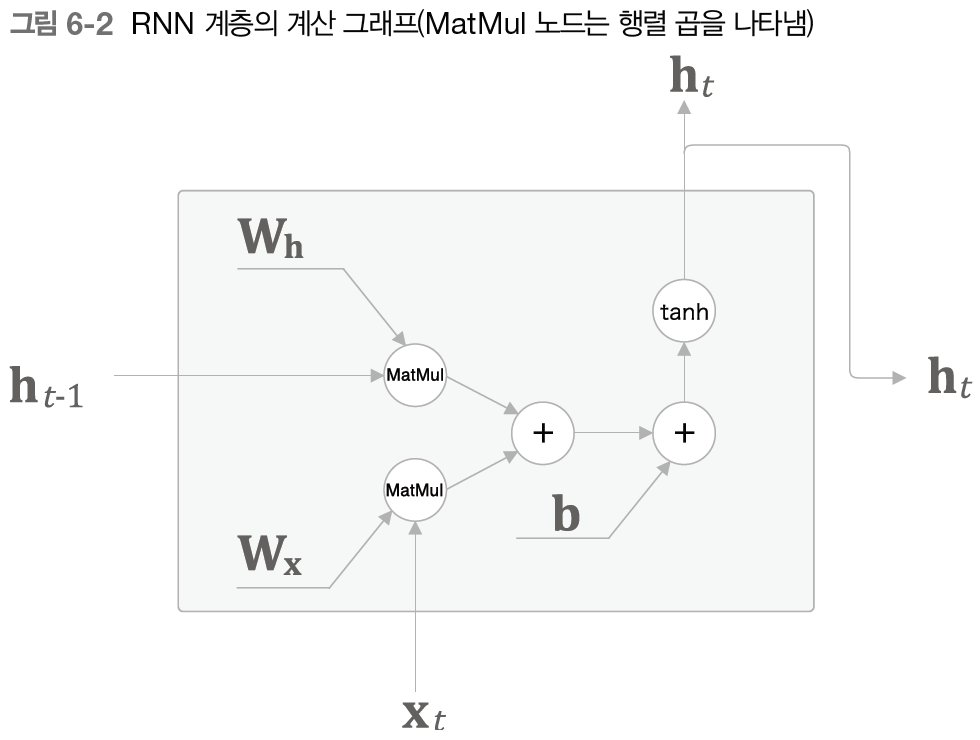
RNN 계층의 순전파에서 수행하는 계산은 행렬의 곱과 합, 그리고 활성화 함수인 tanh 함수에 의한 변환으로 구성된다.
그 다음으로 RNN 계층이 안고 있는 문제, 즉 장기 기억에 취약하다는 문제를 보겠다.
6.1.2 기울기 소실 또는 기울기 폭발
언어 모델은 주어진 단어들을 기초로 다음에 출현할 단어를 예측하는 일을 한다. 이번 절에서는 RNNLM의 단점을 확인하는 차원에서다음의 문제를 다시 생각해보았다.
Tom was watching TV in his room. Mary came into the room. Mary said hi to ?
여기서 ?에 들어갈 단어는 Tom이다. RNNLM이 이 문제에 올바르게 답하라면, 현재 맥락에서 'Tom이 방에서 TV를 보고 있음'과 '그 방에 Mary가 들어옴'이란 정보를 기억해야 한다.
즉, 이런 정보를 RNN 계층의 은닉 상태에 인코딩해 보관해야 한다.
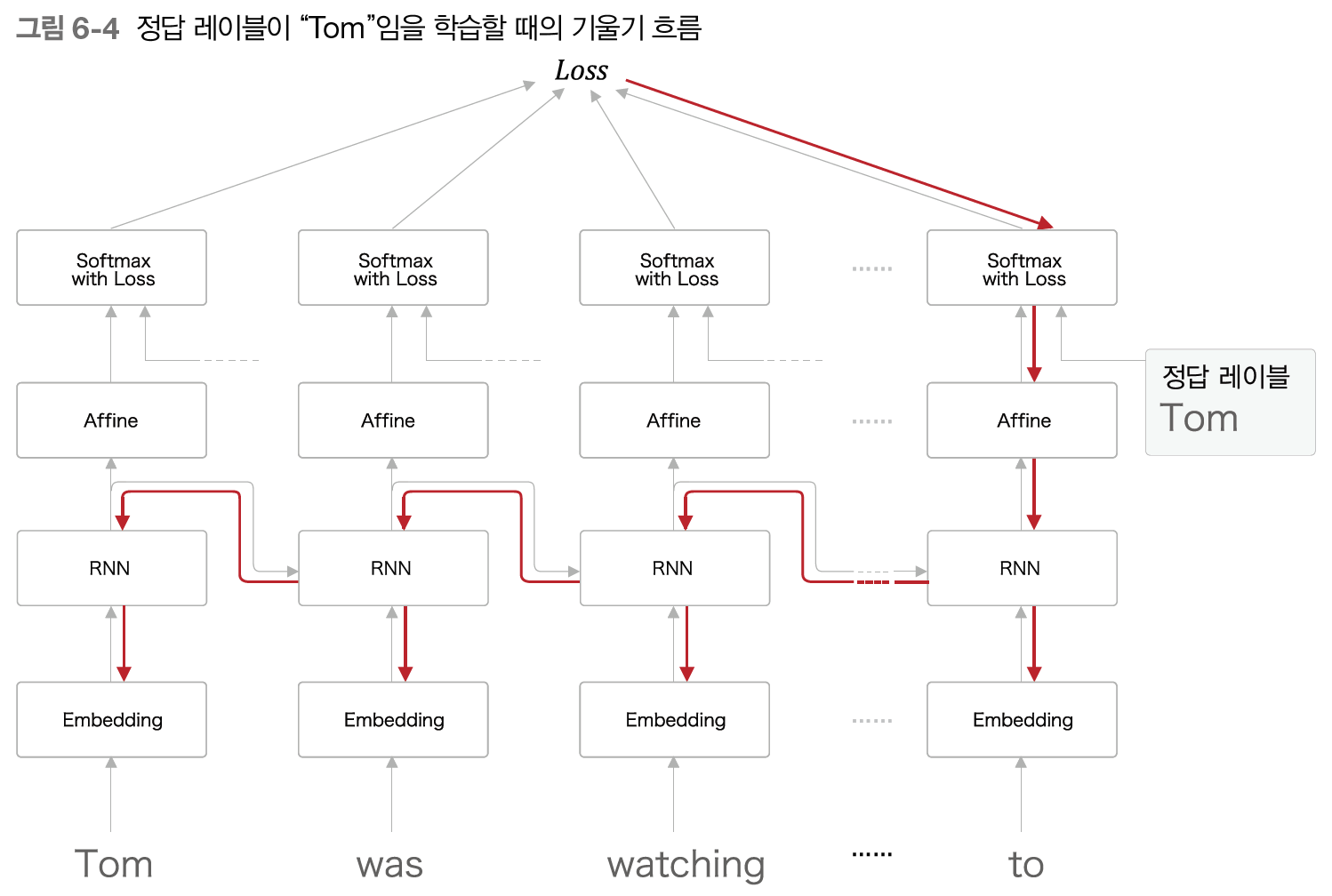
RNNLM의 관점에서 보면 정답 레이블이 'Tom'임을 학습할 때 중요한 것이 바로 RNN 계층의 존재이다. RNN 계층이 과거 방향으로 '의미 있는 기울기'를 전달함으로 시간 방향의 의존 관계를 학습할 수 있다.
여기서 기울기는 학습해야 할 의미가 있는 정보가 들어 있고, 그것을 과거로 전달함으로써 장기 의존 관계를 학습한다. 하지만 중간에 기울기가 사그라들면 가중치 매개변수는 전혀 갱신되지 않게 되어 장기 의존 관계를 학습할 수 없게 된다. 현재는 RNN 계층에서 시간을 거슬러 올라가 기울기가 작아지거나 커져 소실 혹은 폭발되는 상황이다.
6.1.3 기울기 소실과 기울기 폭발의 원인
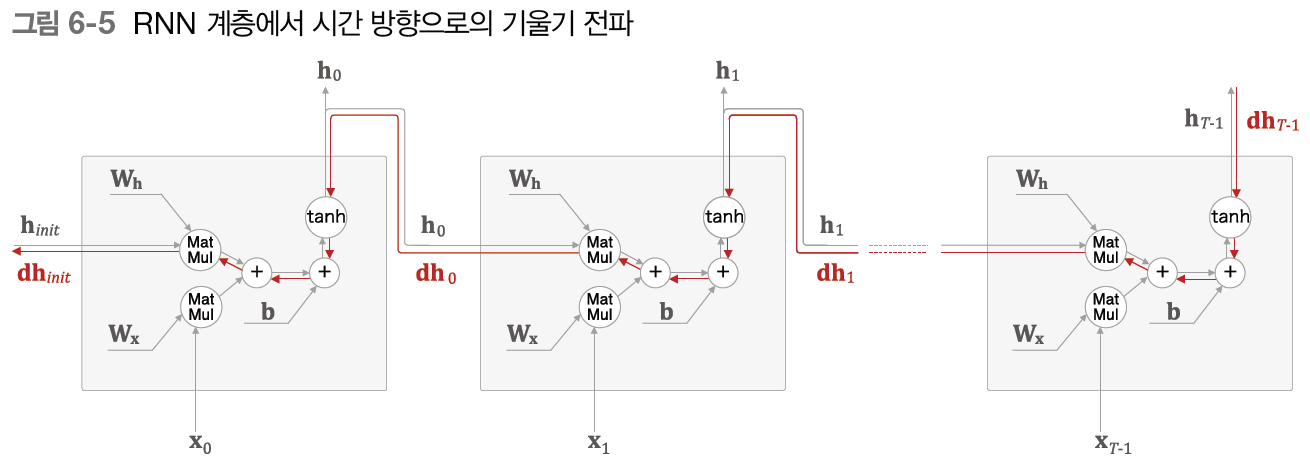
위의 RNN 계층의 그림에서 시간 방향 기울기 전파에만 주목해보자.
길이가 T인 시계열 데이터를 가정하여 T번째 정답 레이블로부터 전해지는 기울기가 어떻게 변하는지 보자. 앞의 문제에 대입하면 T번째 정답 레이블이 'Tom'인 경우에 해당한다. 이때 시간 방향 기울기에 주목하면 역전파로 전해지는 기울기는 차례로 'tanh','+','MatMul(행렬 곱)' 연산을 통과한다는 것을 알 수 있다.
'+'의 역전파는 상류에서 전해지는 기울기를 그대로 하류로 흘러보내 기울기는 변하지 않는다.
'tanh'의 경우와 미분된 경우를 그래프로 그리면 아래와 같다.
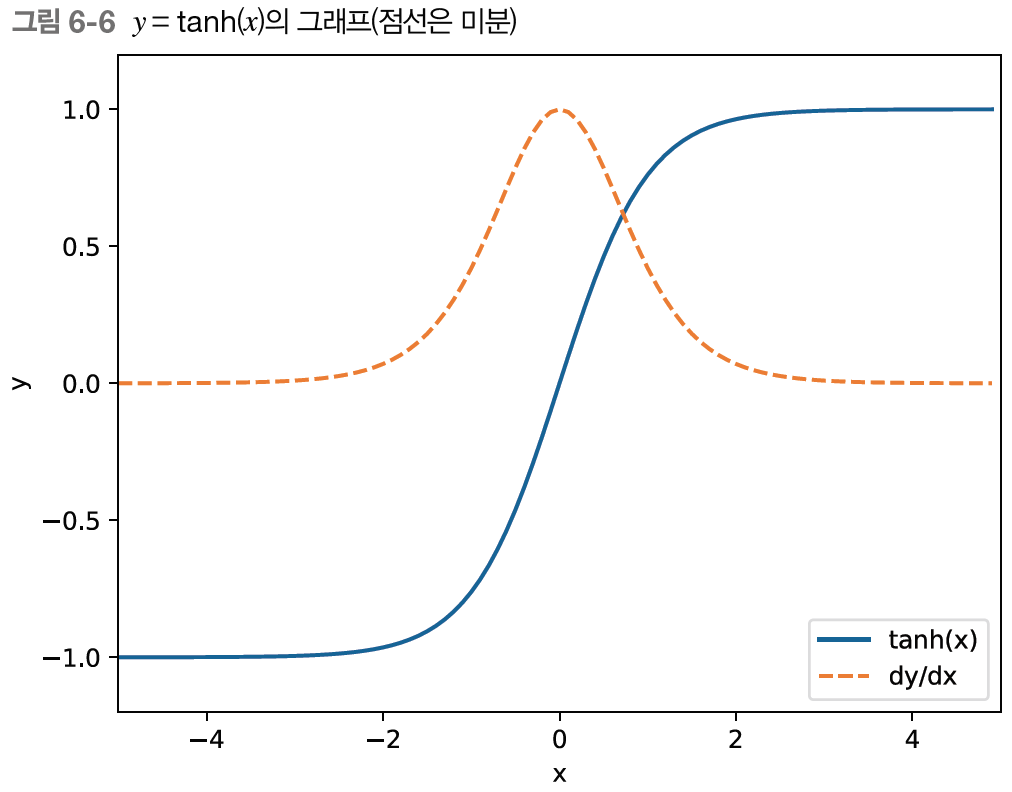
그림에서 점선이 y=tanh(x)의 미분이고 값은 1.0 이하이며, x가 0으로부터 멀어질수록 작아진다. 즉, 역전파에서 기울기가 tanh 노드를 지날 때마다 값은 계속 작아진다는 의미이다. 그리고 tanh 함수를 T번 통과하면 기울기도 T번 반복해서 작아진다.
'MatMul(행렬 곱)' 노드의 경우 tanh 노드를 무시하기로 한다. 그러면 RNN 계층의 역전파 시 기울기는 아래 그림과 같이 'MatMul' 연산에 의해서만 변화하게 된다.
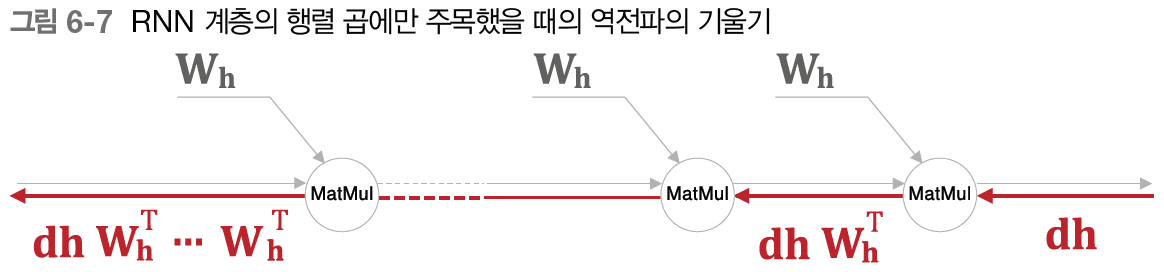
상류로부터 dh라는 기울기가 흘러온다고 가정하고 이때 MatMul 노드에서의 역전파는 dh(W_h^T)라는 행렬 곱으로 기울기를 계산한다. 그리고 같은 계산을 시계열 데이터의 시간 크기만큼 반복한다. 주의할 점은 행렬 곱셈에서 매번 똑같은 Wh 가중치를 쓴다는 것이다.
즉, 행렬 곱의 기울기는 시간에 비례해 지수적으로 증가/감소함을 알 수 있으며 증가할 경우 기울기 폭발이라고 한다. 기울기 폭발이 일어나면 오버플로를 일으켜 NaN 같은 값을 발생시킨다. 반대로 기울기가 감소하면 기울기 소실이 일어나고 이는 일정 수준 이하로 작아지면 가중치 매개변수가 더 이상 갱신되지 않으므로 장기 의존 관계를 학습할 수 없게 된다.
6.1.4 기울기 폭발 대책
기울기 폭발 대책으로는 전통적인 기법인 기울기 클리핑이라는 기법이 있다. 기울기 클리핑은 단순하며 여기서 신경망에서 사용되는 모든 매개변수에 대한 기울기를 하나로 처리한다고 가정한다.
기울기의 L2노름이 문턱값을 초과하면 두 번째 줄의 수식과 같이 기울기를 수정하며 이를 기울기 클리핑이라 한다.
6.2 기울기 소실과 LSTM
RNN 학습에서 기울기 소실도 큰 문제이다. 이 문제를 해결하려면 RNN 계층의 아키텍처를 근본부터 뜯어고쳐야 한다.
6.2.1 LSTM의 인터페이스
계산을 단순화하는 도법을 하나 도입하는데 아래와 같이 행렬 계산 등을 하나의 직사각형 노드로 정리해 그리는 방식이다.
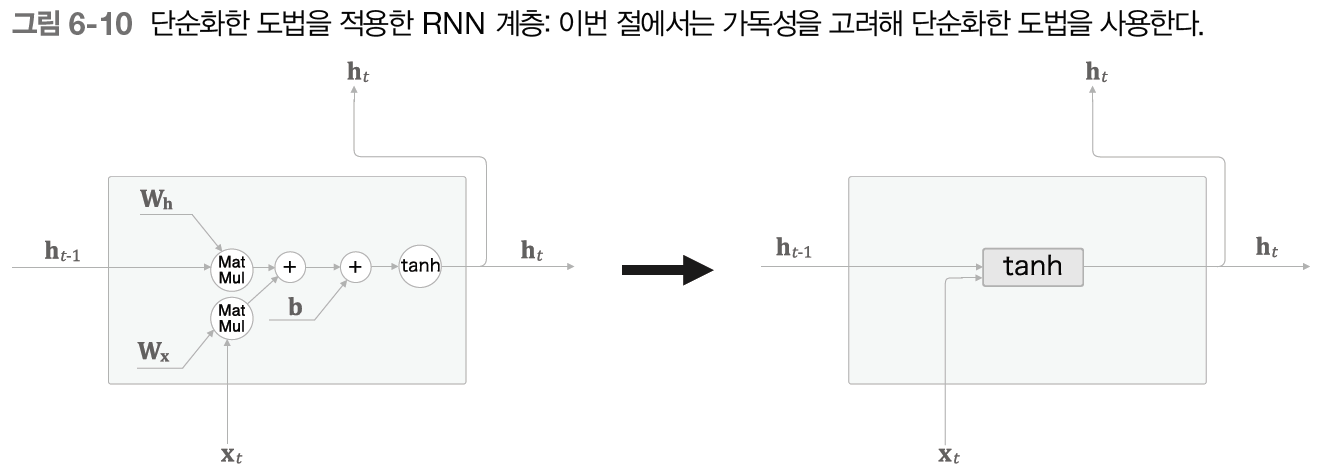
여기서는 tanh(h_(t-1)W_h+x_tW_x+b) 계산을 tanh라는 직사각형 노드 하나로 그리고 직사각형 노드 안에 행렬 곱과 편향의 합, 그리고 tanh 함수에 의한 변환이 모두 포함된 것이다.
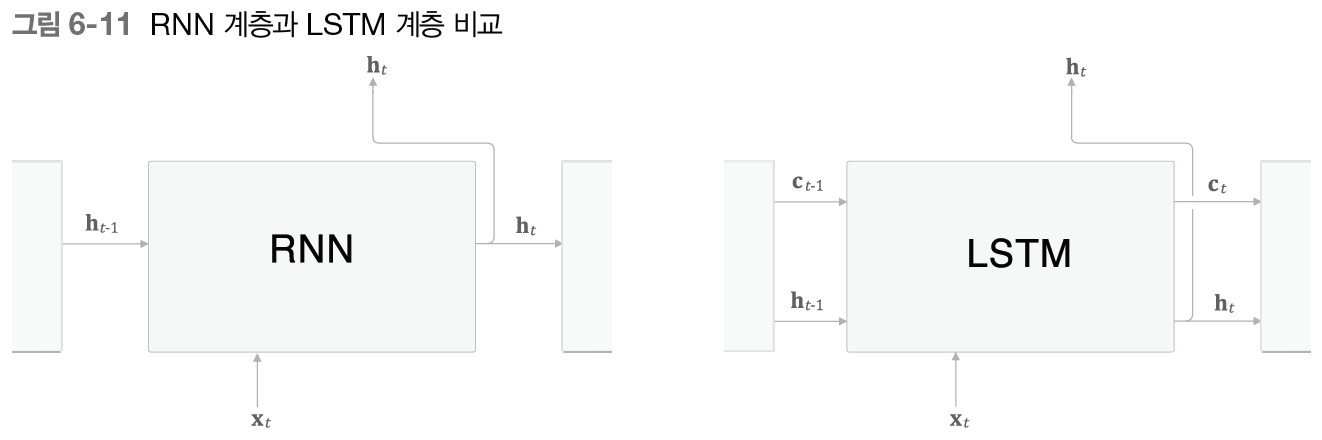
이 그림에서는 LSTM 계층의 인터페이스에는 c라는 경로가 있다는 차이가 있다. 여기서 c를 기억 셀이라 하며 LSTM 전용의 기억 메커니즘이다.
기억 셀의 특징은 데이터를 LSTM 계층 내에서만 주고받는다는 것이다. 다른 계층으로는 출력하지 않는다는 것이다. 반면, LSTM의 은닉 상태 h는 RNN 계층과 마찬가지로 다른 계층, 위쪽으로 출력된다.
6.2.2 LSTM 계층 조립하기
LSTM에는 기억 셀 ct가 있다. c_t에서 시각 t에서의 LSTM의 기억이 저장돼 있는데, 과거로부터 시각 t까지의 필요한 모든 정보가 저장돼 있다고 가정한다. 그리고 필요한 정보를 모두 간직한 이 기억을 바탕으로, 외부 계층에 은닉 상태 h_t를 출력한다. 이때 출력하는 h_t는 아래 그림과 같이 기억 셀의 값을 tanh함수로 변환하 값이다.
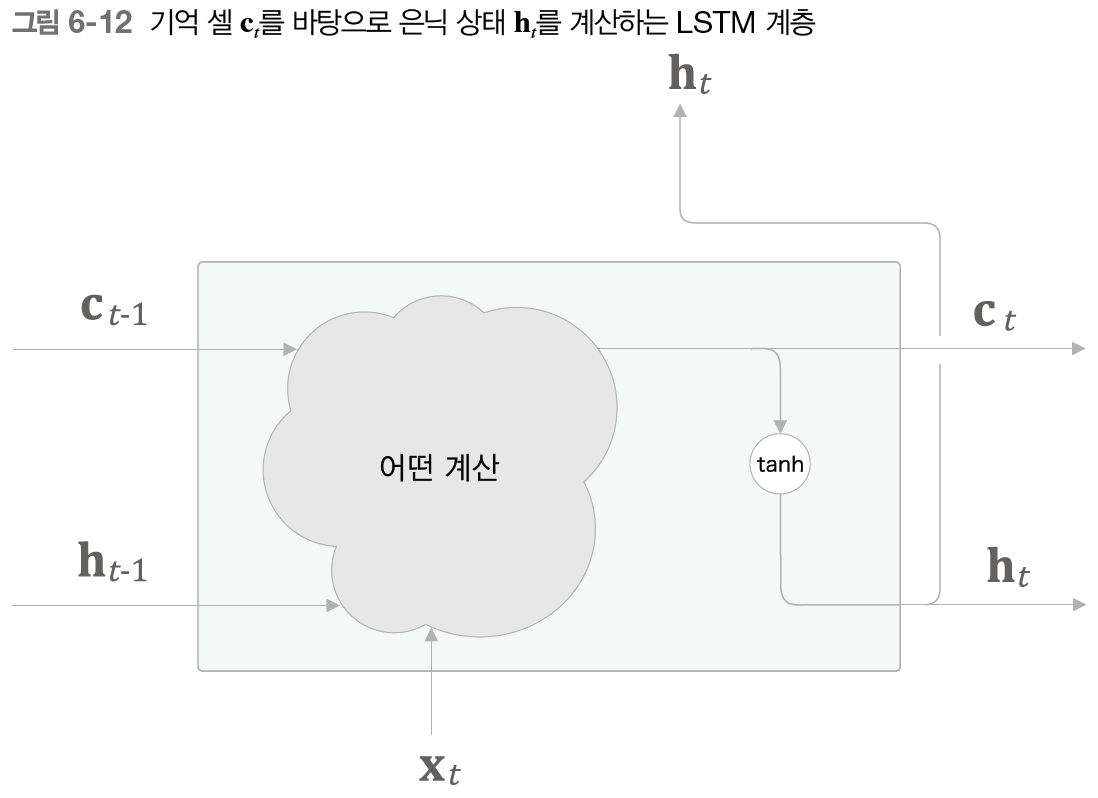
그림에서 현재의 기억 셀 c_t는 3개의 입력 (c(t-1),h_(t-1),x_t)으로부터 '어떤 계산'을 수행하여 구할 수 있다. 여기서 핵심은 갱신된 c_t를 사용해 은닉 상태 h_t를 계산한다는 것이다. 또한 이 계산은 h_t=tanh(c_t)인데, 이는 c_t의 각 요소에 tanh 함수를 적용한다는 뜻이다.
'게이트'란 우리나라로 '문'을 의미하는 단어이다. 문은 열거나 닫을 수 있듯이, 게이트는 데이터의 흐름을 제어한다.
LSTM에서 사용하는 게이트는 '열기/닫기'뿐 아니라, 어느 정도 열지를 조절할 수 있다. '어느 정도'를 '열림 상태'라 부르며 0.7(70%)이나 0.2(20%)처럼 제어할 수 있다.
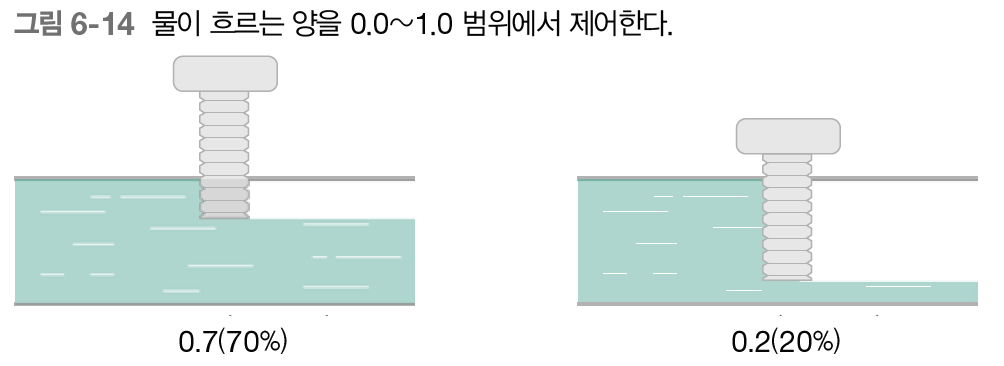
그리고 게이트의 열림 사애는 그림에서처럼 0.0~1.0 사이의 실수로 나타나며 1.0은 완전한 개방을 의미한다. 그리고 그 값이 다음으로 흐르는 물의 양을 결정한다. 여기서 중요한 것은 '게이트를 얼마나 열까'라는 것도 데이터로부터 자동으로 학습한다는 점이다.
6.2.3 output 게이트
tanh(c_t)의 각 원소에 대해 '그것이 다음 시각의 은닉 상태에 얼마나 중요한가'를 조정한다. 한편, 이 게이트는 다음 은닉 상태 h_t의 출력을 담당하는 게이트이므로 output 게이트라고 한다.
output 게이트의 열림 상태는 입력 xt와 이전 상태 h(t-1)로부터 구한다. 이때의 식은 밑에 식과 같다.
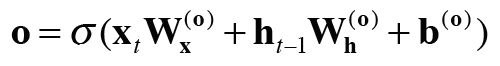
밑에 그림에서 output 게이트에서 수행하는 식의 계산을 sigma로 표기했다. sigma의 출력을 o라고 하면 h_t는 o와 tanh(c_t)의 곱으로 계산된다.
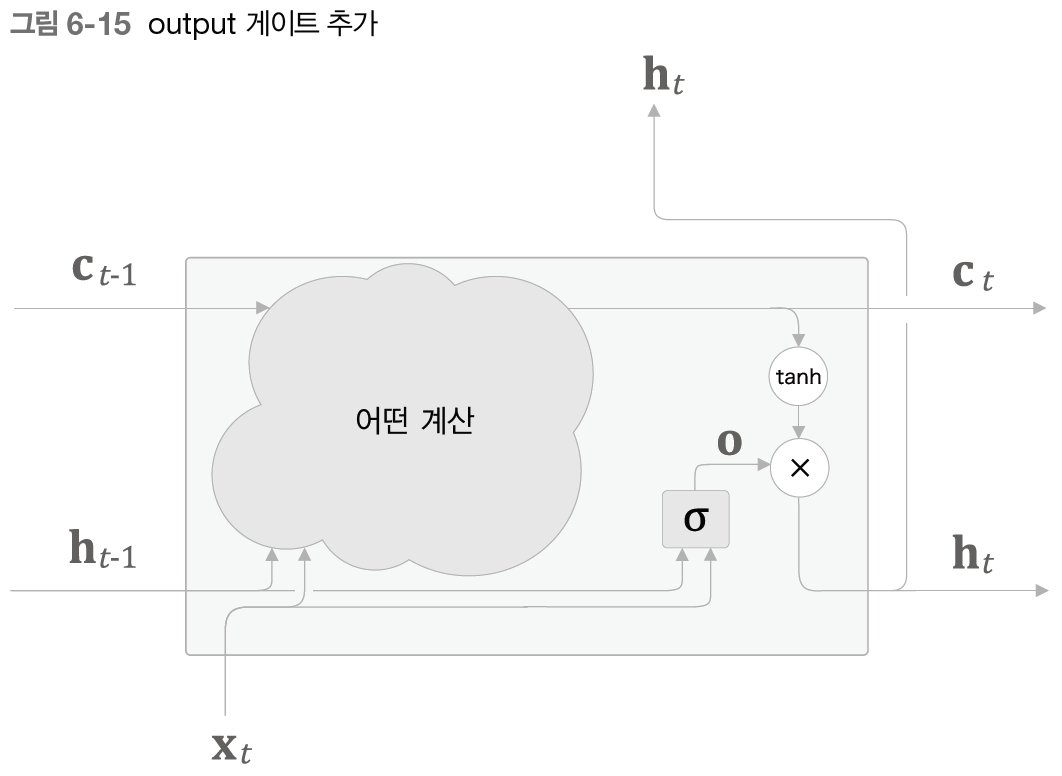
여기서 말하는 '곱'이란 원소별 곱이며, 이것을 아다마르 곱이라고 한다.
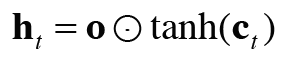 \
\
여기까지 LSTM 의 output 게이트이고 출력 부분은 완성되었다.
6.2.4 forget 게이트
다음에 해야 할 일은 기억 셀에 '무엇을 잊을까'를 명확하게 지시하는 것이다.
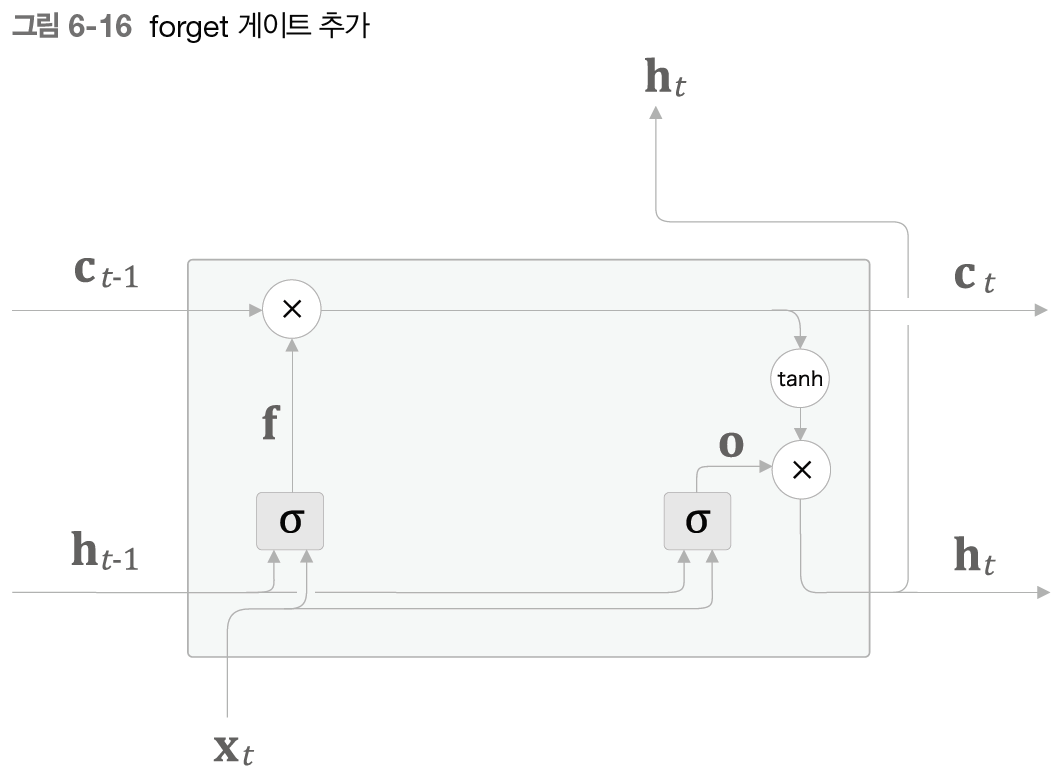
그림에서 보이는 거서럼 forget게이트가 수행하는 일련의 계산을 sigma 노드로 표기했고 이 안에는 forget 게이트 전용의 가중치 매개변수가 있고 다음 식의 계산을 수행한다.
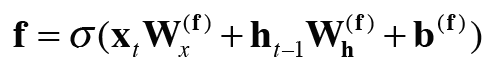
6.2.5 새로운 기억 셀
forget 게이트를 거치며넛 이전 시각의 기억 셀로부터 잊어야 할 기억이 삭제되었다.
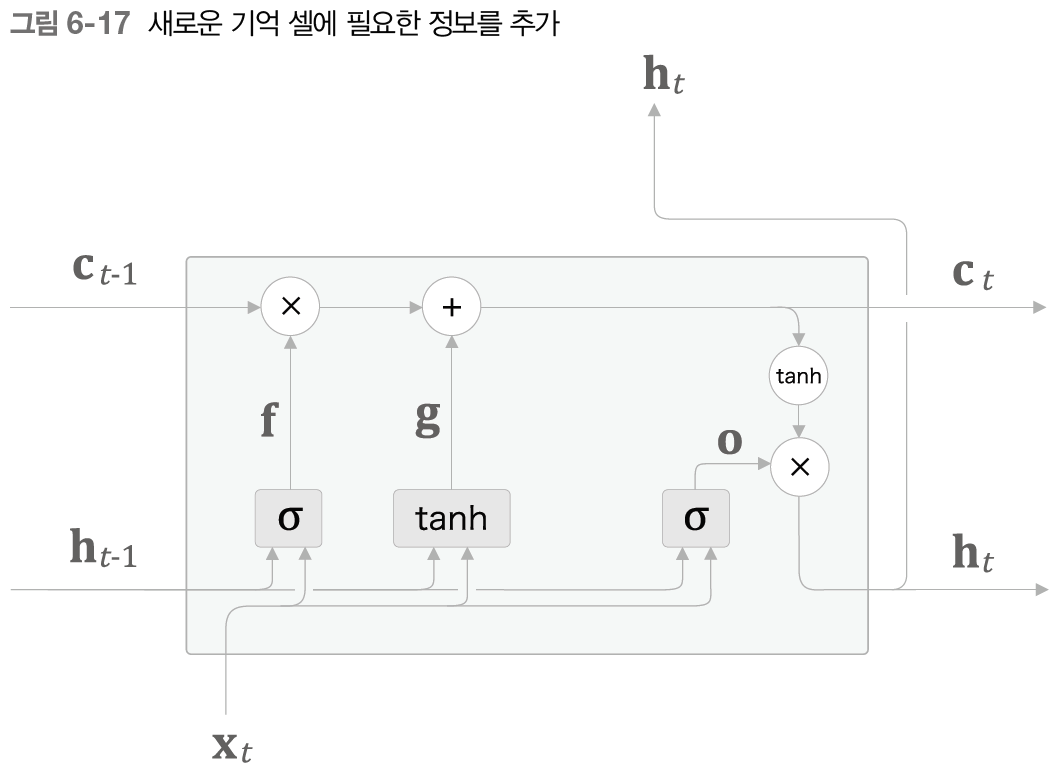
그림에서 보듯 tanh 노드가 계산한 결과가 이전 시각의 기억 셀 c_(t-1)에 더해진다. 기억 셀에 새로운 '정보'가 추가 된 것이다. 이 tanh노드에서 수행하는 계산은 다음과 같다.
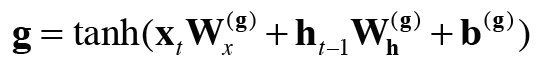
6.2.6 input 게이트
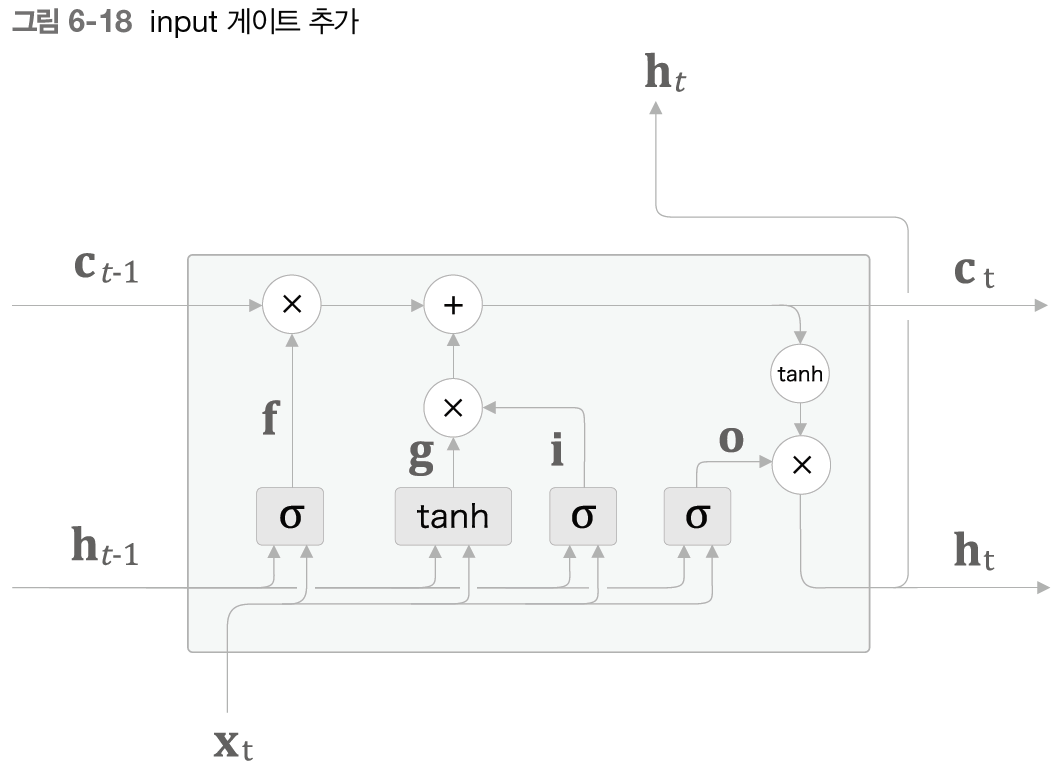
마지막으로 g에 게이트를 하나 추가하여 이를 input 게이트라고 하겠다. input 게이트는 g의 원소가 새로 추가되는 정보로써의 가치가 얼마나 큰지를 판단한다. 새 정보를 무비판적으로 수용하는 게 아니라, 적절히 취사선택하는 것이 이 게이트의 역할이다. 즉, input 게이트에 의해 가중된 정보가 새로 추가되는 셈이다.
밑의 식은 이때 수행하는 계산식이다.
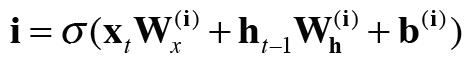
6.2.7 LSTM의 기울기 흐름
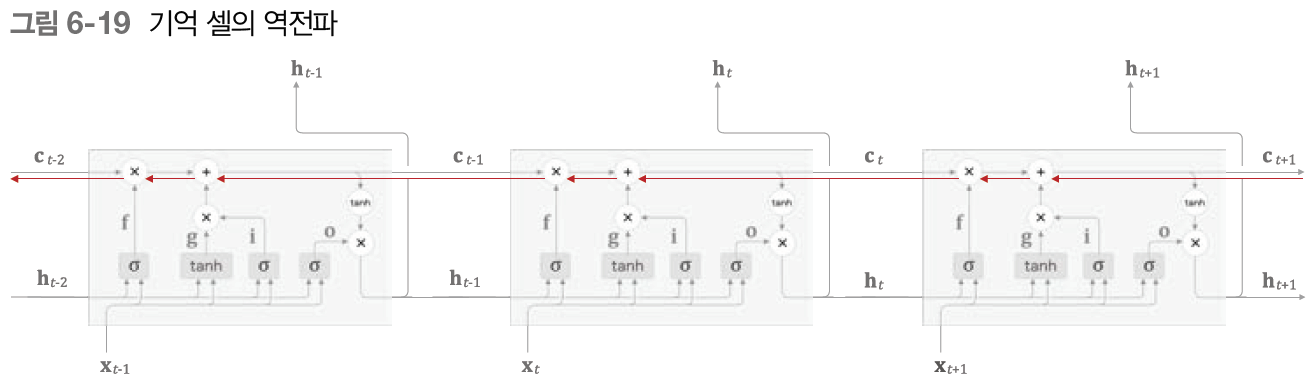
이 구조를 보면 기억 셀에 집중하여, 그 역전파의 흐름을 그린 것이다. 이때 기억 셀의 역전파에서는 '더하기'와 '곱하기' 노드만 가지에 되고 '더하기'노드는 상류에서 전해지는 기울기를 그대로 흘려 기울기 변화(감소)는 일어나지 않는다.
'곱하기'노드에서는 행렬 곱이 아닌 원소별 곱(아마다르 곱)을 계산한다. 앞에서 RNN의 역전파에서는 똑같은 가중치 행렬을 사용하여 행렬 곱을 반복하여 기울기 소실(혹은 폭발)이 일어났다. 원소별 곱은 매 시각 다른 게이트 값을 이용해 원소별 곱을 계산하는데 매번 새로운 게이트 값을 이용하므로 곱셈의 효과가 누적되지 않아 기울기 소실이 일어나지 않는다.
'곱하기'노드의 계산은 forget 게이트가 제어하며 이 게이트가 '잊어야 한다'고 판단한 기억 셀의 원소에 대해서는 그 기울기가 작아진다. 한편, forget게이트가 '잊어서는 안 된다'고 판단한 원소에 대해서는 그 기울기가 약화되지 않은 채로 과거 방향으로 전해진다. 따라서 기억 셀의 기울기가 소실 없이 전파되리라 기대할 수 있다.
6.3 LSTM 구현
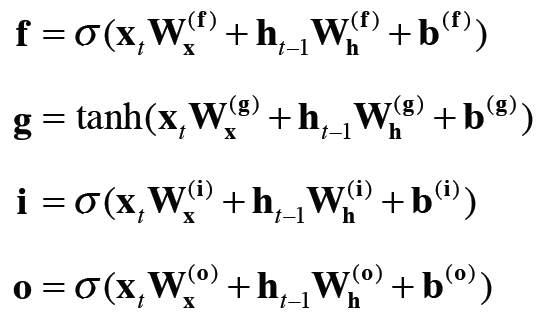
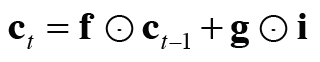
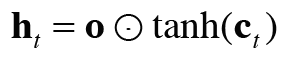
위 식들이 LSTM에서 수행하는 계산이고 주목할 부분은 [식 6.6]의 네 수식에 포함된 아핀 변환이다. 아핀 변환을 하나도 묶은 그림이 밑에서 나타난다.
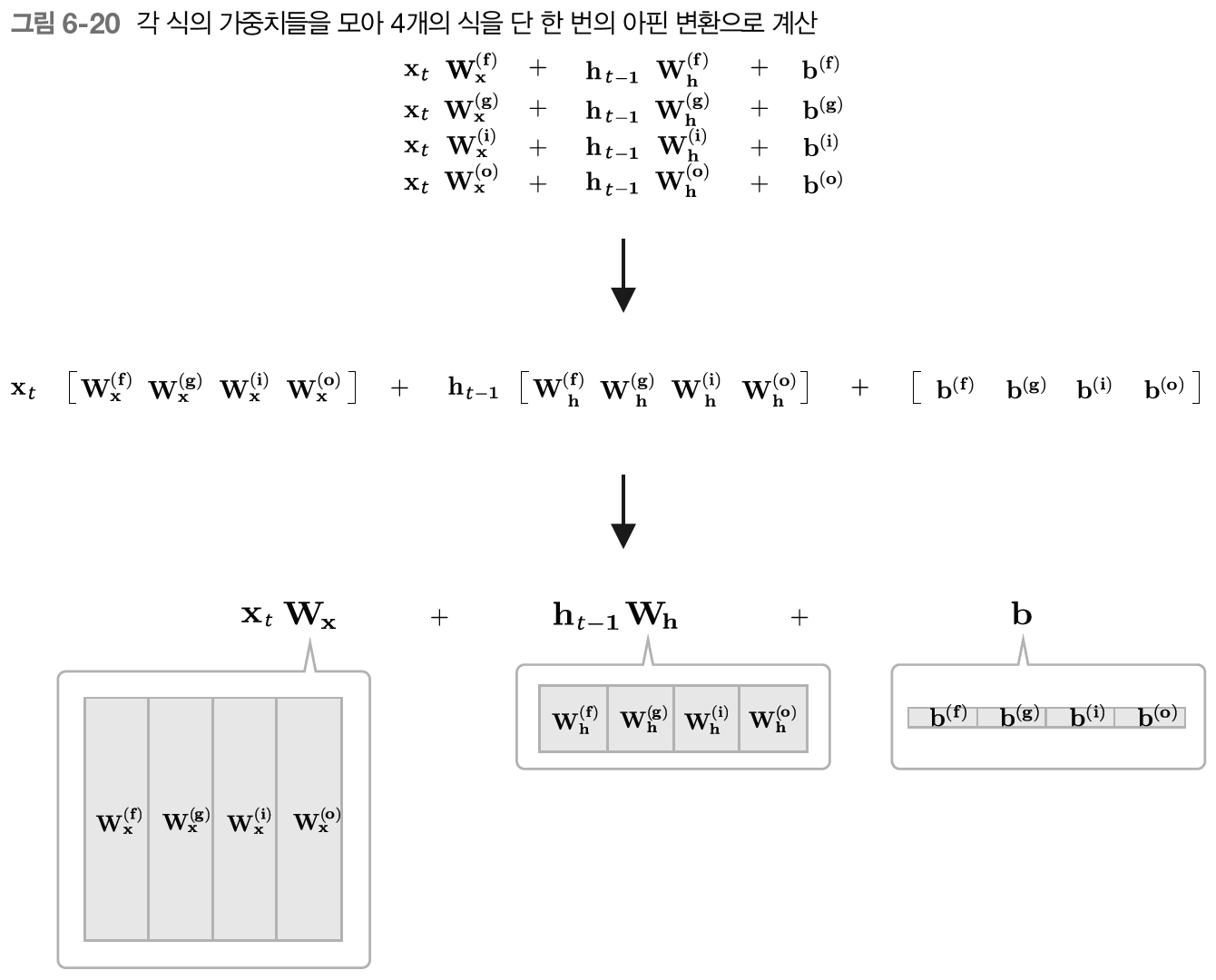
4개의 가중치를 하나로 모을 수 있고, 그렇게 하면 원래 개별적으로 총 4번 수행하던 아핀 변환을 단 1회의 게산으로 끝마칠 수 있다.
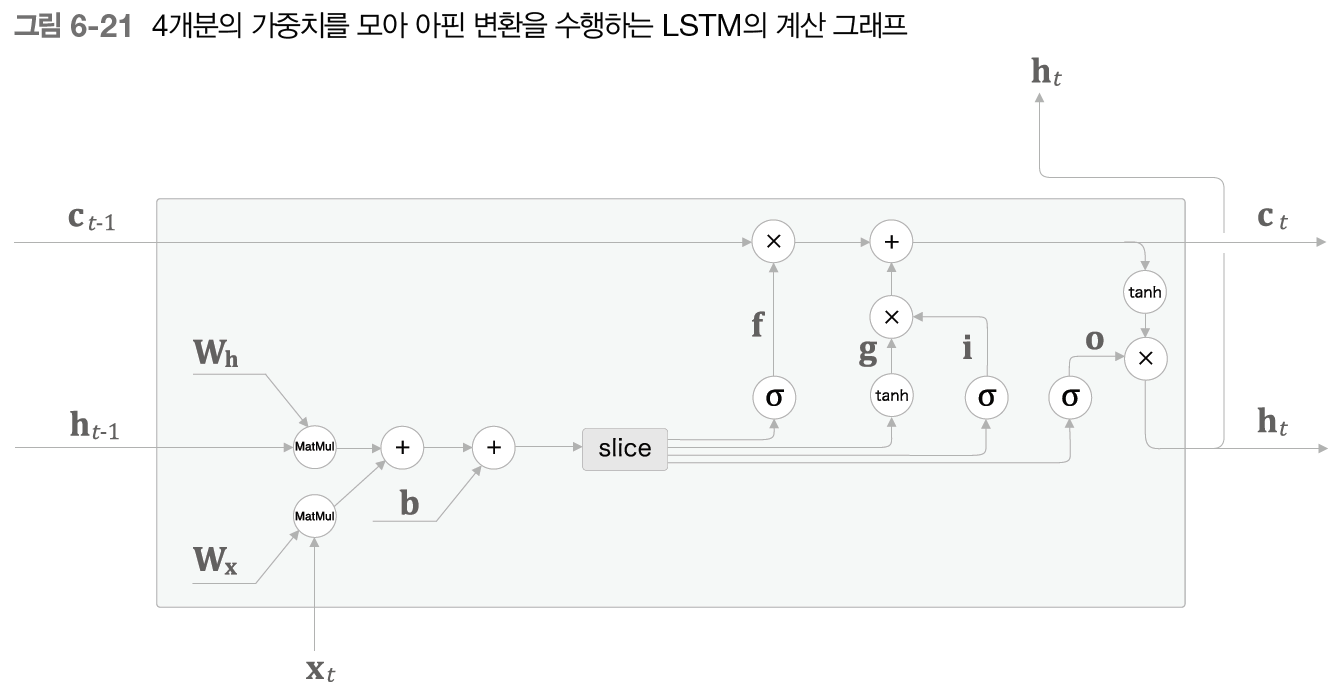
만약 W_x, W_h, b 각각에 4개분의 가중치가 포함되어 있다고 가정하면 위의 그림처럼 그래프가 그려진다.
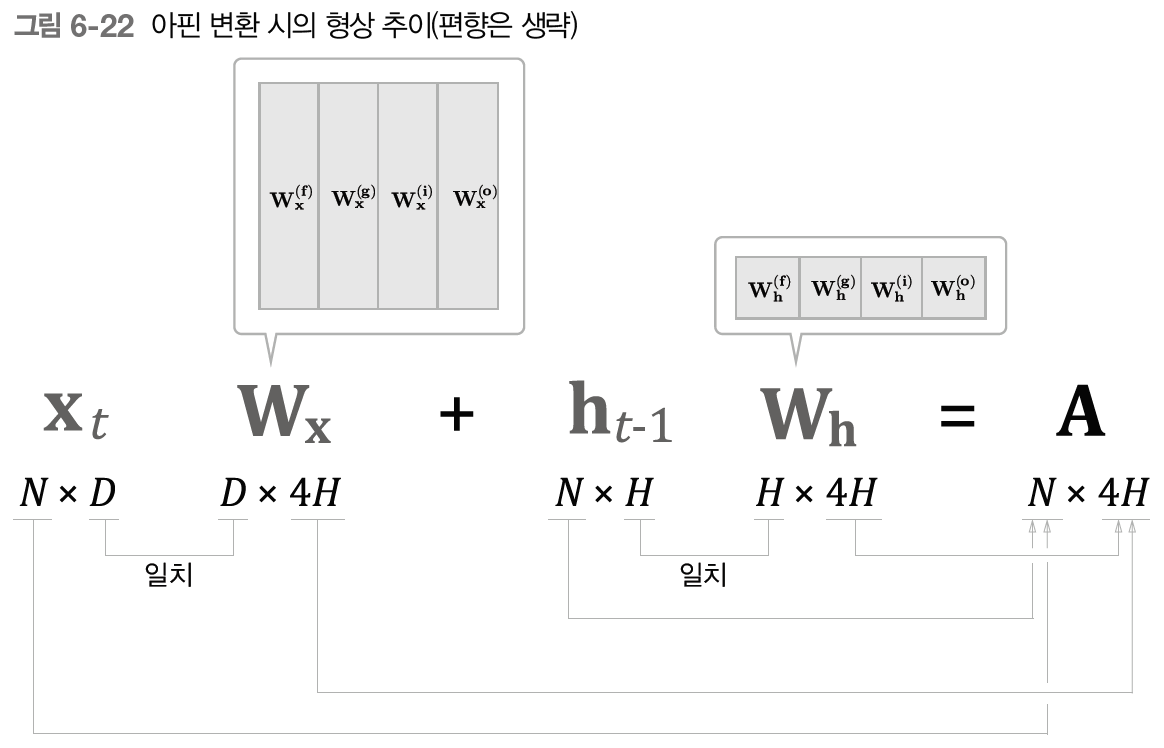
[그림 6-22]에서는 미니배치 수를 N, 입력 데이터의 차원 수를 D, 기억 셀과 은닉 상태의 차원 수를 모두 H로 표시했습니다. 그리고 계산 결과인 A에는 네 개분의 아핀 변환 결과가 저장된다. 따라서 결과로 데이터를 꺼낼 때는 슬라이스 해서 꺼내고 꺼낸 데이터를 다음 연산 노드에 분배한다.
slice 노드는 행렬을 네 조각으로 나눠서 분배했다. 따라서 그 역전파에서는 반대로 4개의 기울기를 결합해야 한다.
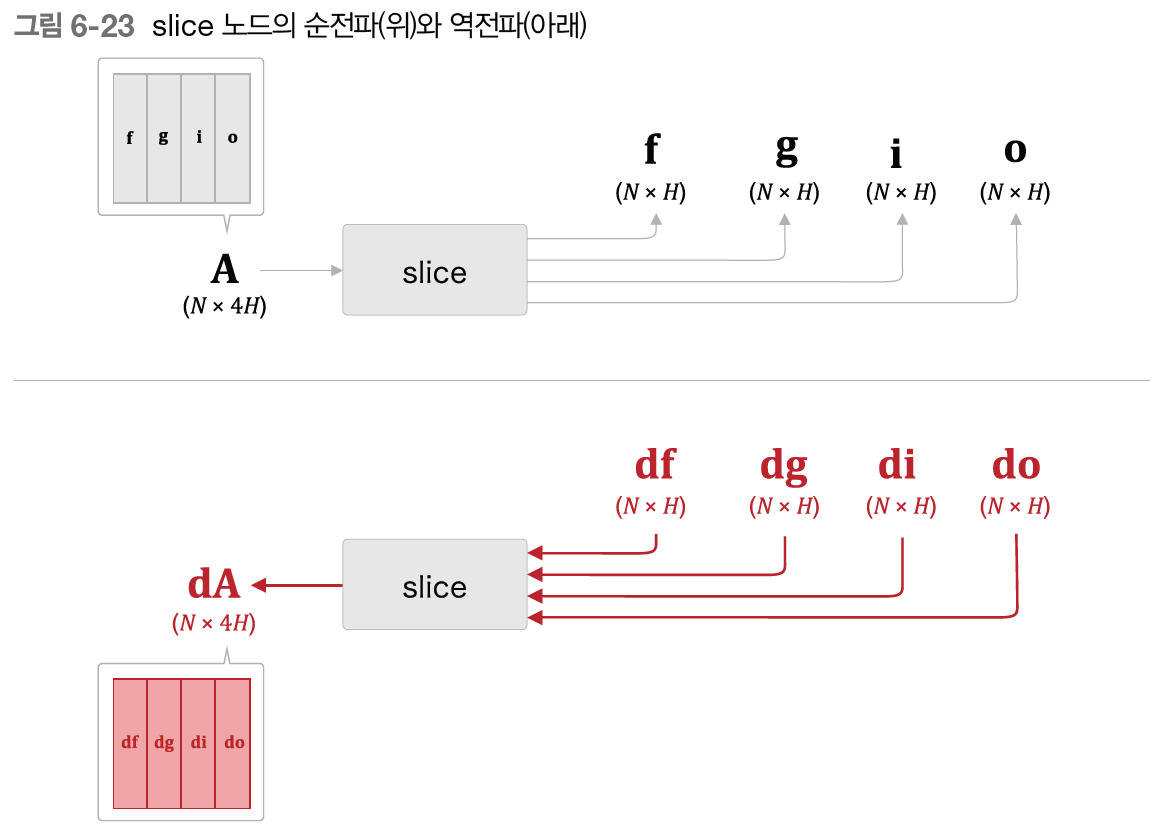
위의 그림에서 보이듯 slice 노드의 역전파에서는 4개의 행렬을 연결한다. 그림에서는 4개의 기울기 df, dg, di, do를 연결해서 dA를 만들었다.
6.3.1 Time LSTM 구현
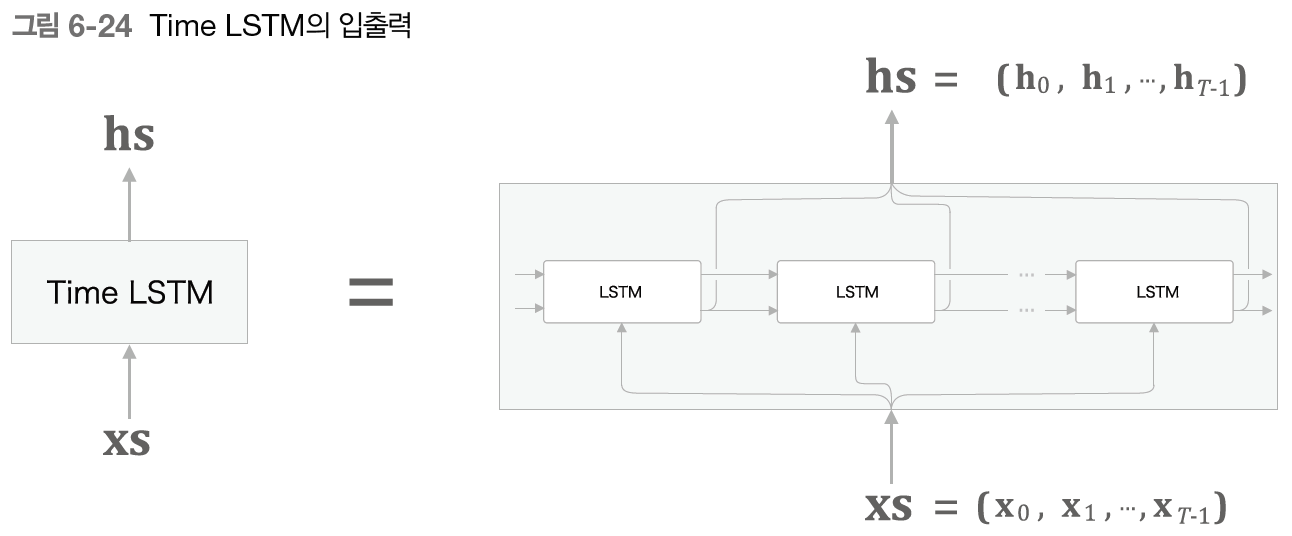
Time LSTM은 T개분의 시계열 데이터를 한꺼번에 처리하는 계층이다.
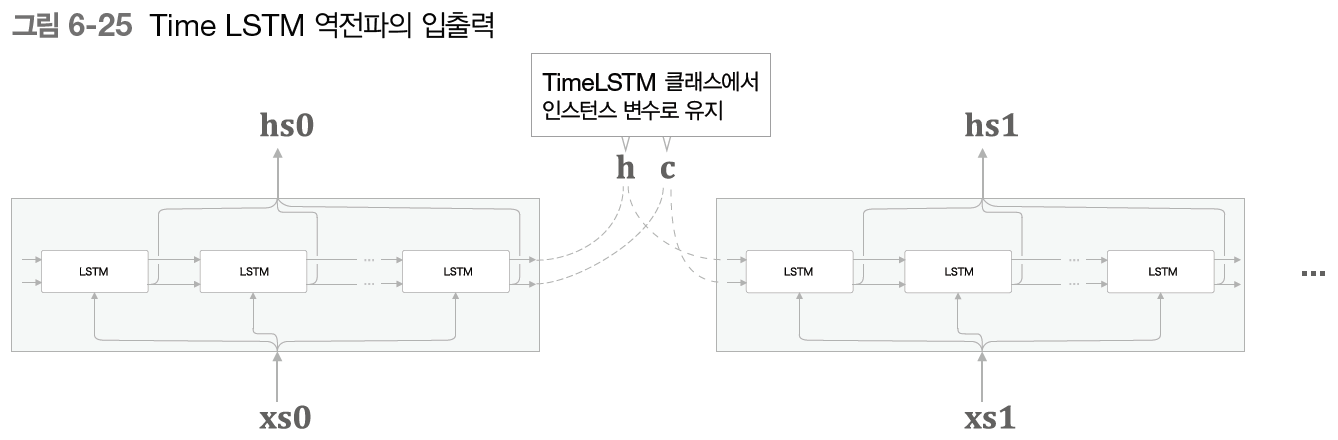
Truncated BPTT는 역전파의 연결은 적당한 길이로 끊으며, 순전파의 흐름은 그래도 유지한다.
6.4 LSTM을 사용한 언어 모델
코드
6.5 RNNLM 추가 개선
이 절에서는 현재의 RNNLM의 개선 포인트 3가지를 설명하고 구현하고 얼마나 좋아졌는지 평하하겠다.
6.5.1 LSTM 계층 다층화
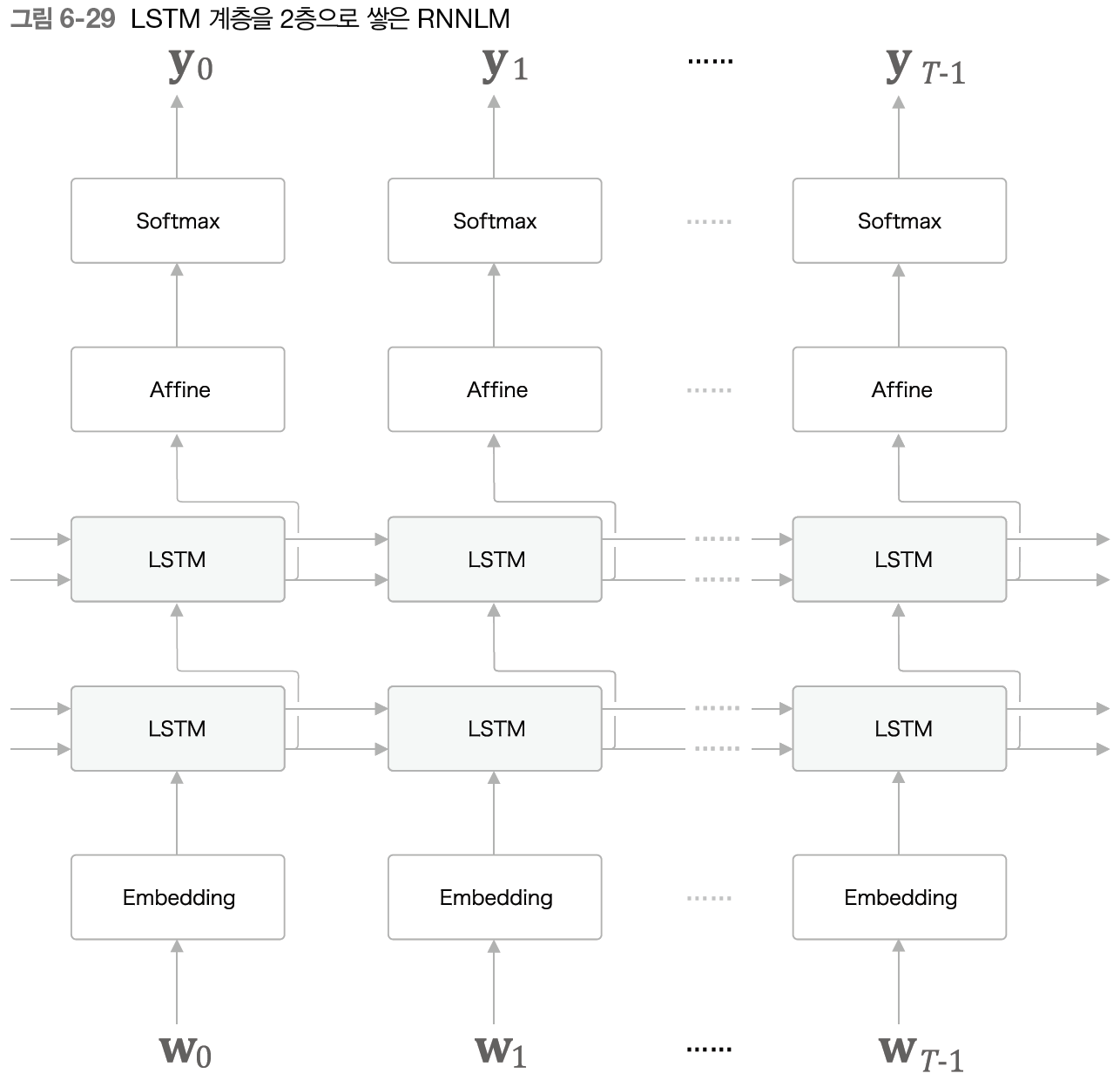
RNNLM으로 정확한 모델을 만들고자 한다면 많은 경우 LSTM 계층을 깊게 쌍하 효과를 볼 수 있다. 지금까지는 1층만 사용했지만 2층, 3층 식으로 여러 겹 쌓으면 언어 모델의 정확도가 향상되리라 기대할 수 있다. LSTM을 2층으로 쌓아 RNNLM 만든다고 하면 위에 그림처럼 된다.
6.5.2 드롭아웃에 의한 과적합 억제
LSTM 계층을 다층화하면 시계열 데이터의 복잡한 의존 관계를 학습할 수 있을 것이라 기대할 수 있다. 다르게 표현하면, 층을 깊게 쌓음으로써 표현력이 풍부한 모델을 만들 수 있으나 종종 과적합을 일으킨다. 불행하게도 RNN은 일반적인 피드포워드 신경망보다 쉽게 과적합을 일으킨다는 소식이다. 따라서 RNN의 과적합 대책은 중요하고 , 현재도 활발하게 연구되는 주제이다.
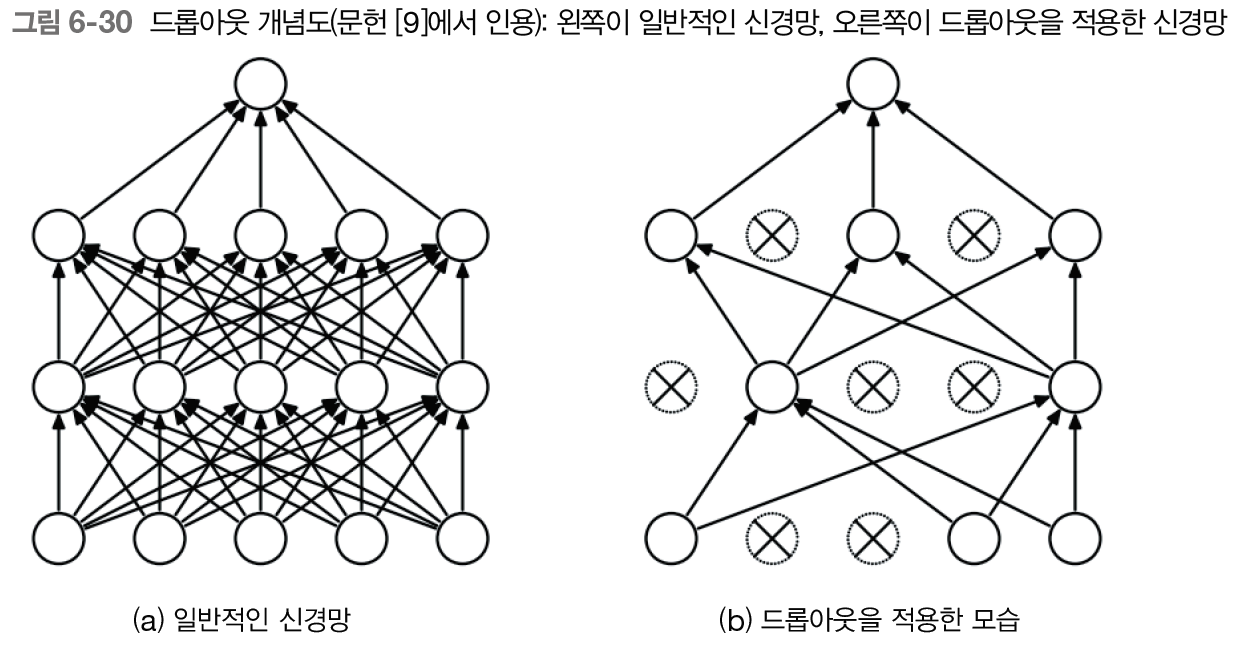
드롭아웃은 무작위로 뉴런을 선택하여 선택한 뉴런을 무시한다. 무시한다는 말은 그 앞 계층으로부터의 신호 전달을 막는다는 뜻이다. 이 '무작위한 무시'가 제약이 되어 신경망의 일반화 성능을 개선하는 것이다.
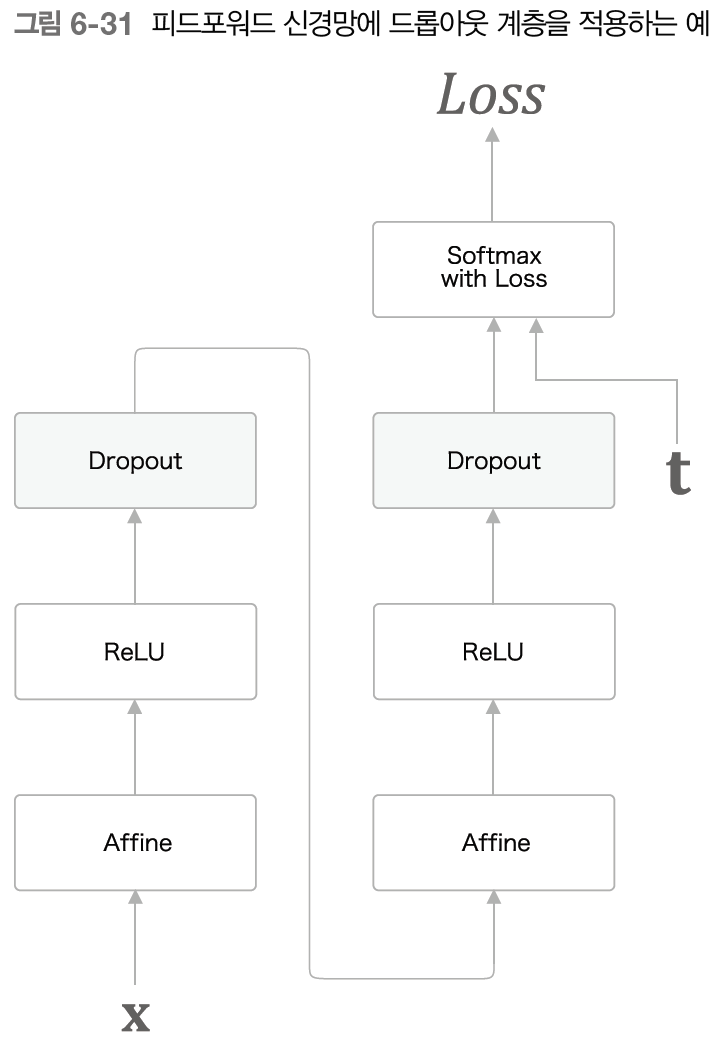
이 그림은 드롭아웃 계층을 활성화 함수 뒤에 삽입하는 방법으로 과적합 억제에 기여하는 모습이다.
RNN을 사용한 모델에서 드롭아웃 계층을 LSTM 계층의 시계열 방향으로 삽이면 좋은 방법이 아니다.
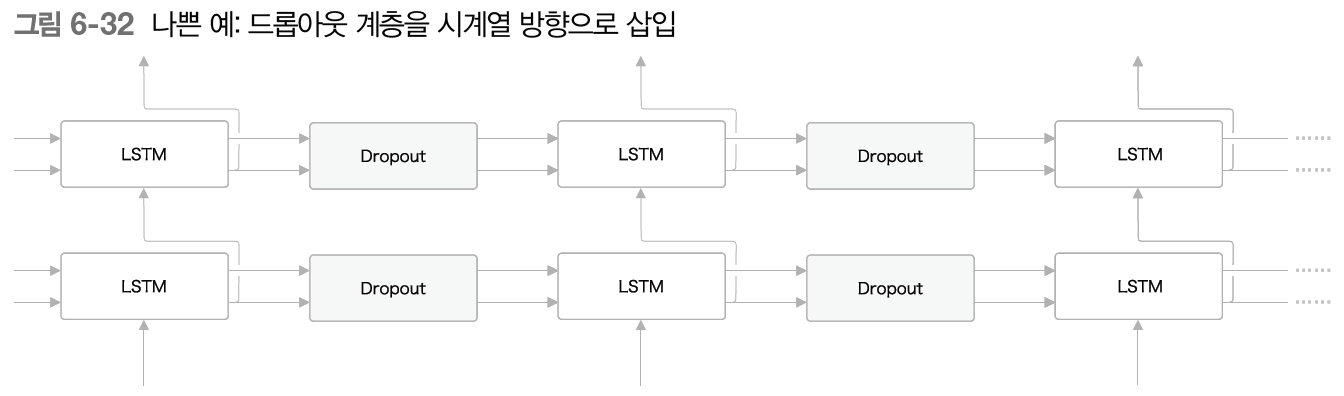
RNN에서 시계열 방향으로 드롭아웃을 학습 시 넣어버리면 시간이 흐름에 따라 정보가 사라질 수 있다. 즉, 흐르는 시간에 비례해 드롭아웃에 의한 노이즈가 축적된다.
드롭아웃 계층을 깊이 방향(상하 방향)으로 삽입하는 방안을 생각해보자
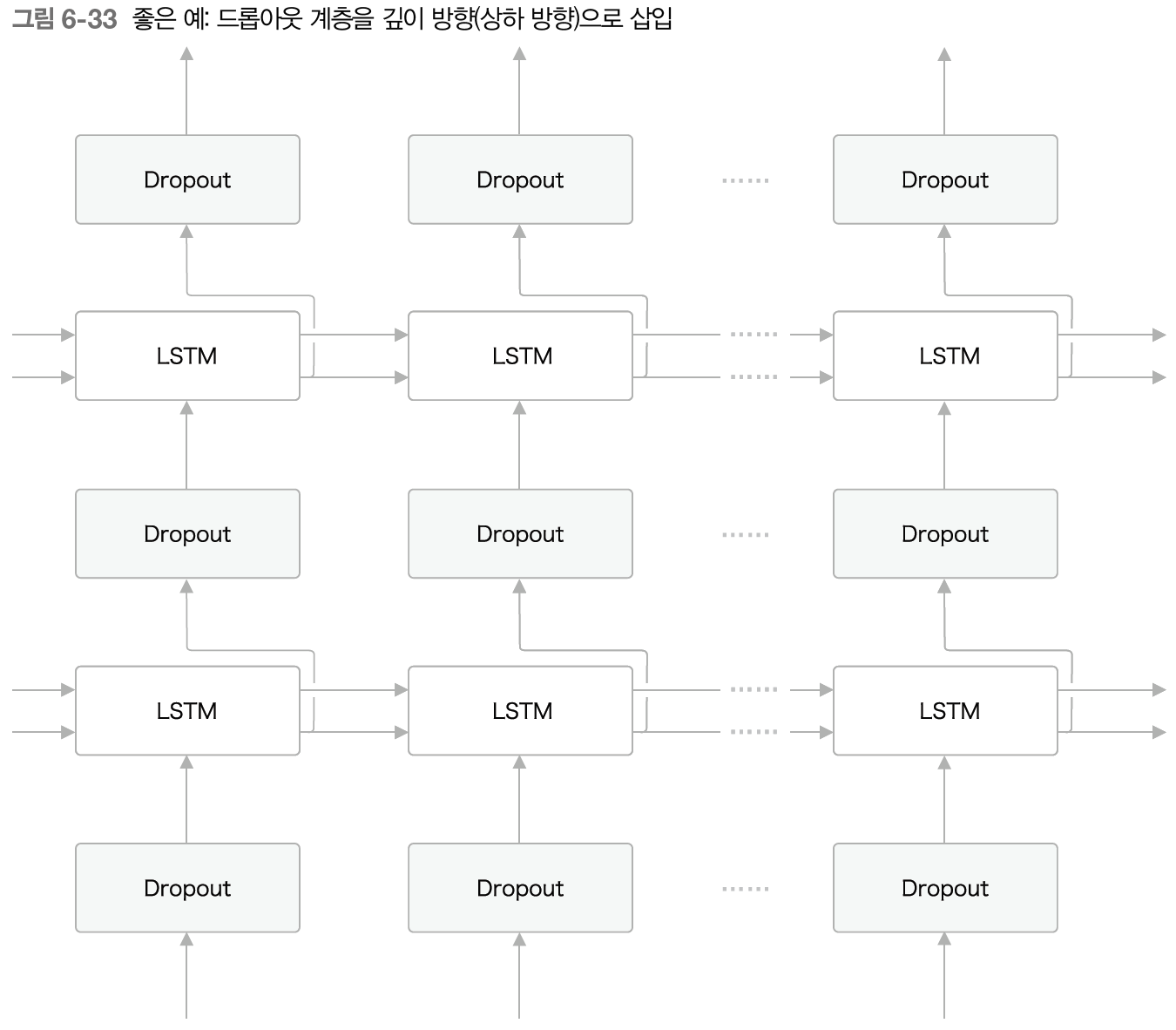
이렇게 구성하면 시간 방향으로 아무리 진행해도 정보를 잃지 않는다. 드롭아웃이 시간축과는 독립적으로 깊이 방향에만 영향을 주는 것이다.
'일반적인 드롭아웃'은 시간 방향에는 적합하지 않다. RNN의 시간 방향 정규화를 목표로 하는 방법이 다양하게 제안되다가 변형 드롭아웃이 제안되어 시간 방향으로 적용하는 데 성공했다.
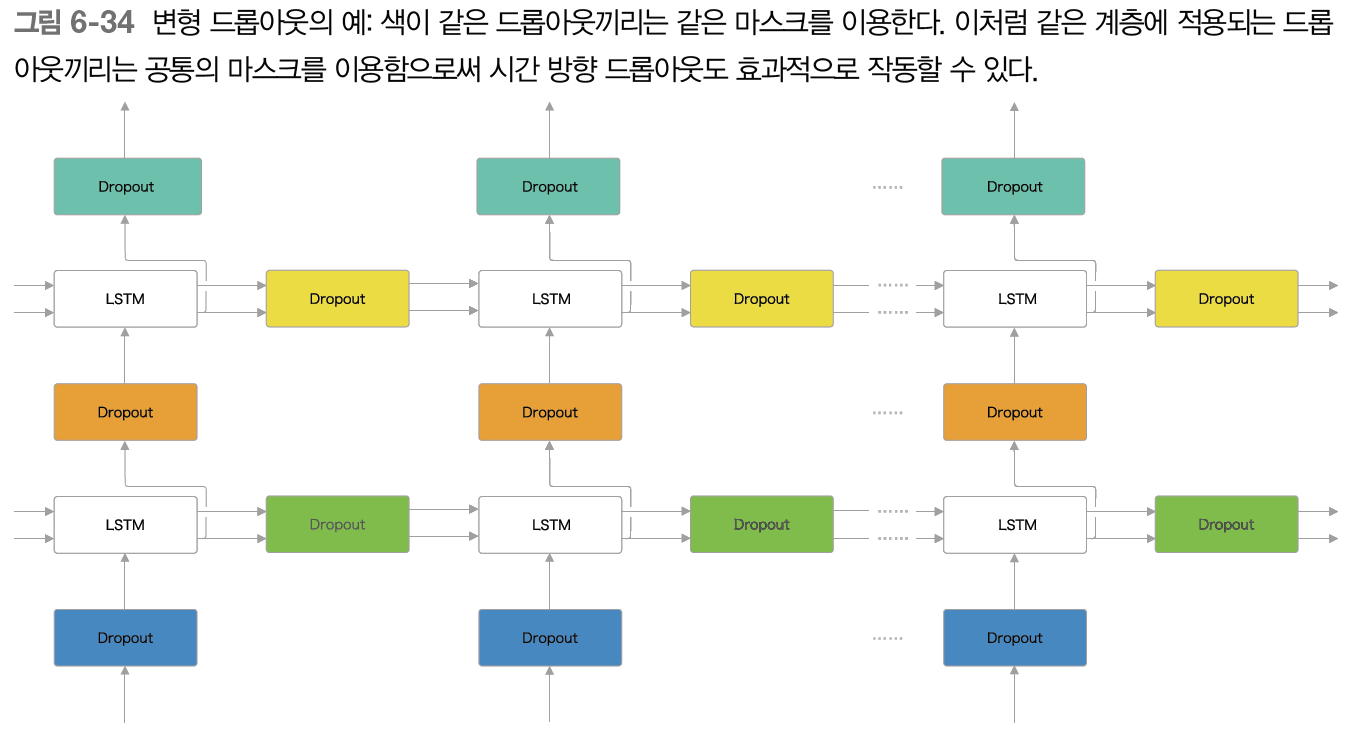
계층의 드롭아웃끼리 마스크를 공유함으로써 마스크가 '고정'된다. 그 겨로가 정보를 잃게 되는 방법도 '고정'되므로, 일반적인 드롭아웃 때와 달리 정보가 지수적으로 손실되는 사태를 피할 수 있다.
6.5.3 가중치 공유
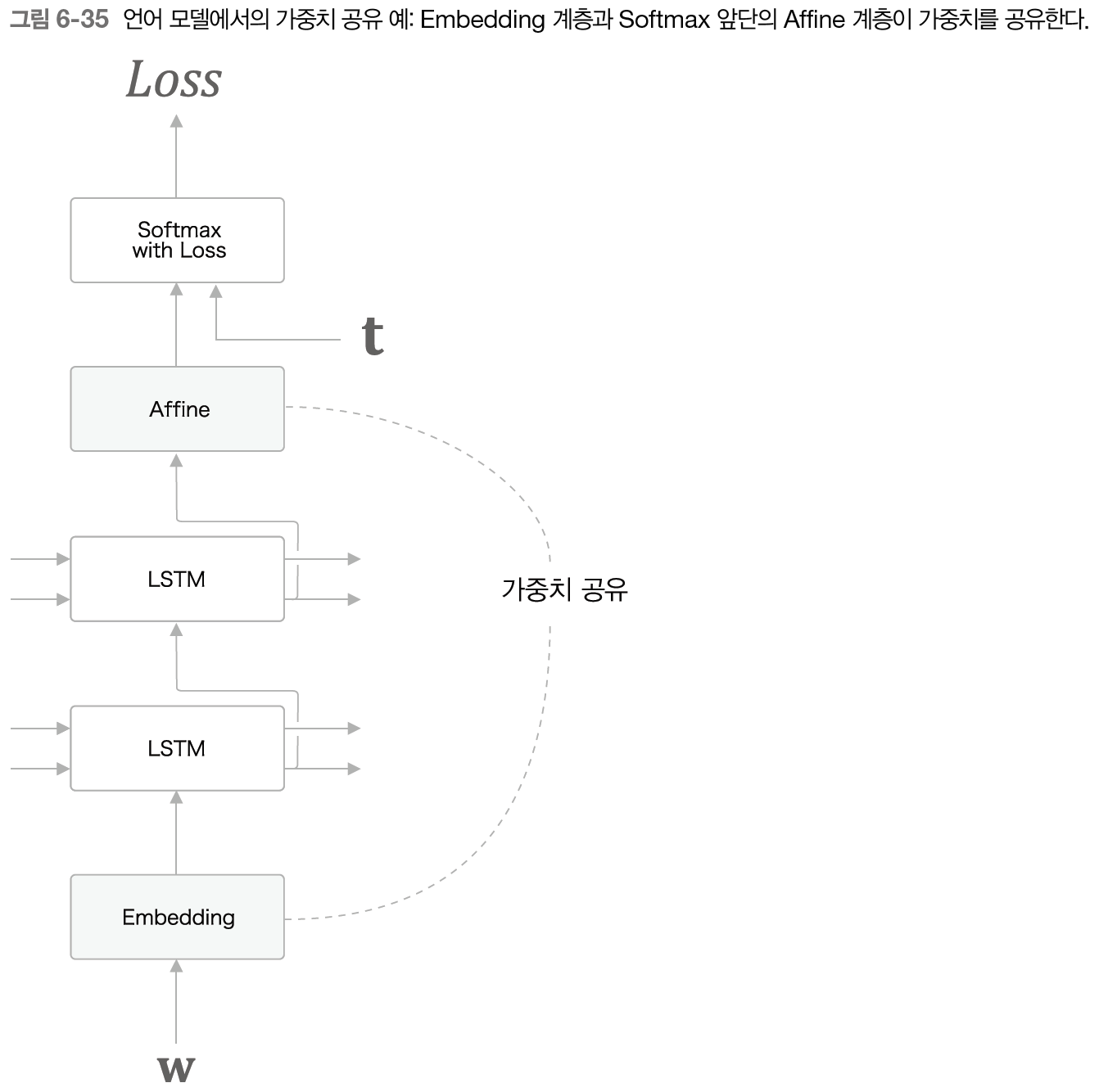
가중치 공유는 Embedding 계층의 가중치와 Affine 계층의 가중치를 연결하는 기법이다. 두 계층이 가중치를 공유함으로써 학습하는 매개변수 수가 크게 줄어드는 동시에 정확도도 향상되는 일석이조의 기술이다.
6.5.4 개선된 RNNLM 구현
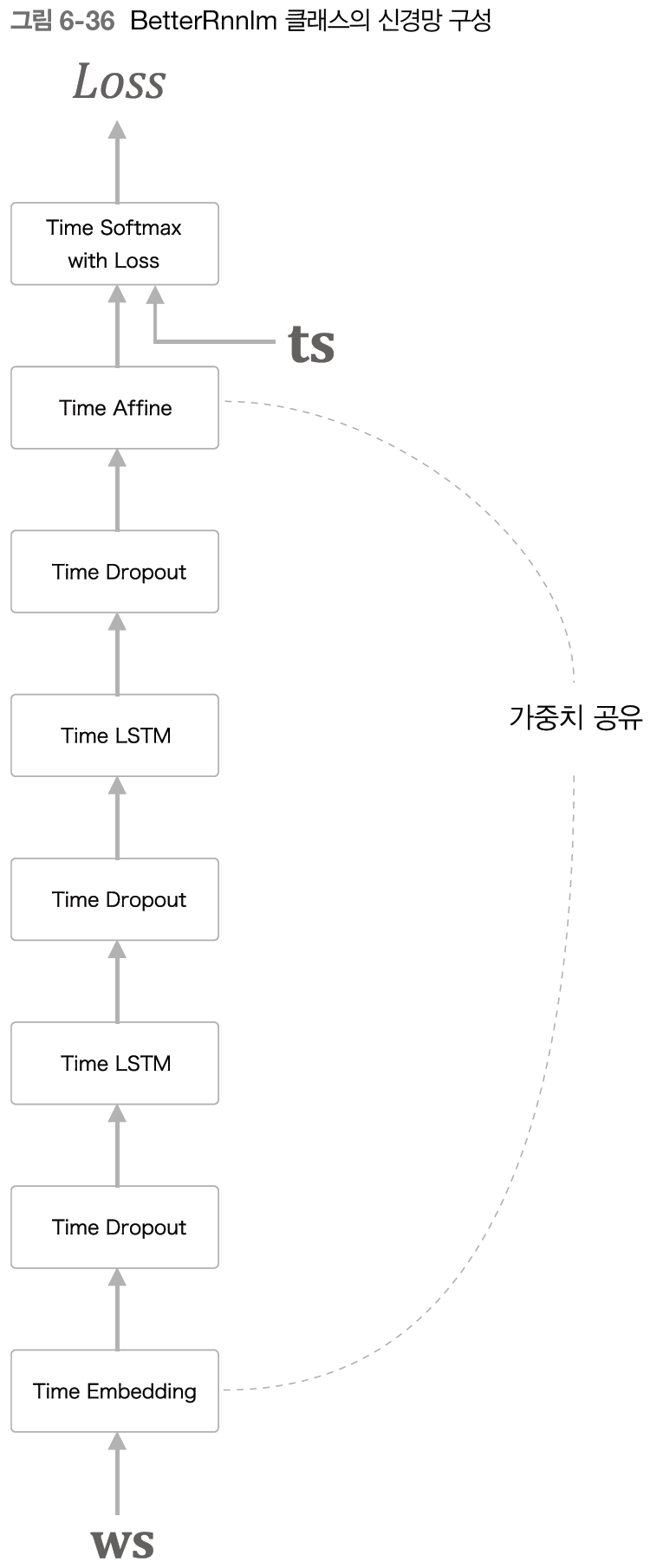
여기서 개선점은 다음 세 가지이다.
- LSTM 계층의 다층화(여기에서는 2층)
- 드롭아웃 사용(깊이 방향으로만 적용)
- 가중치 공유(Embedding 계층과 Affine 계층에서 가중치 공유)
<코드 따라하기>
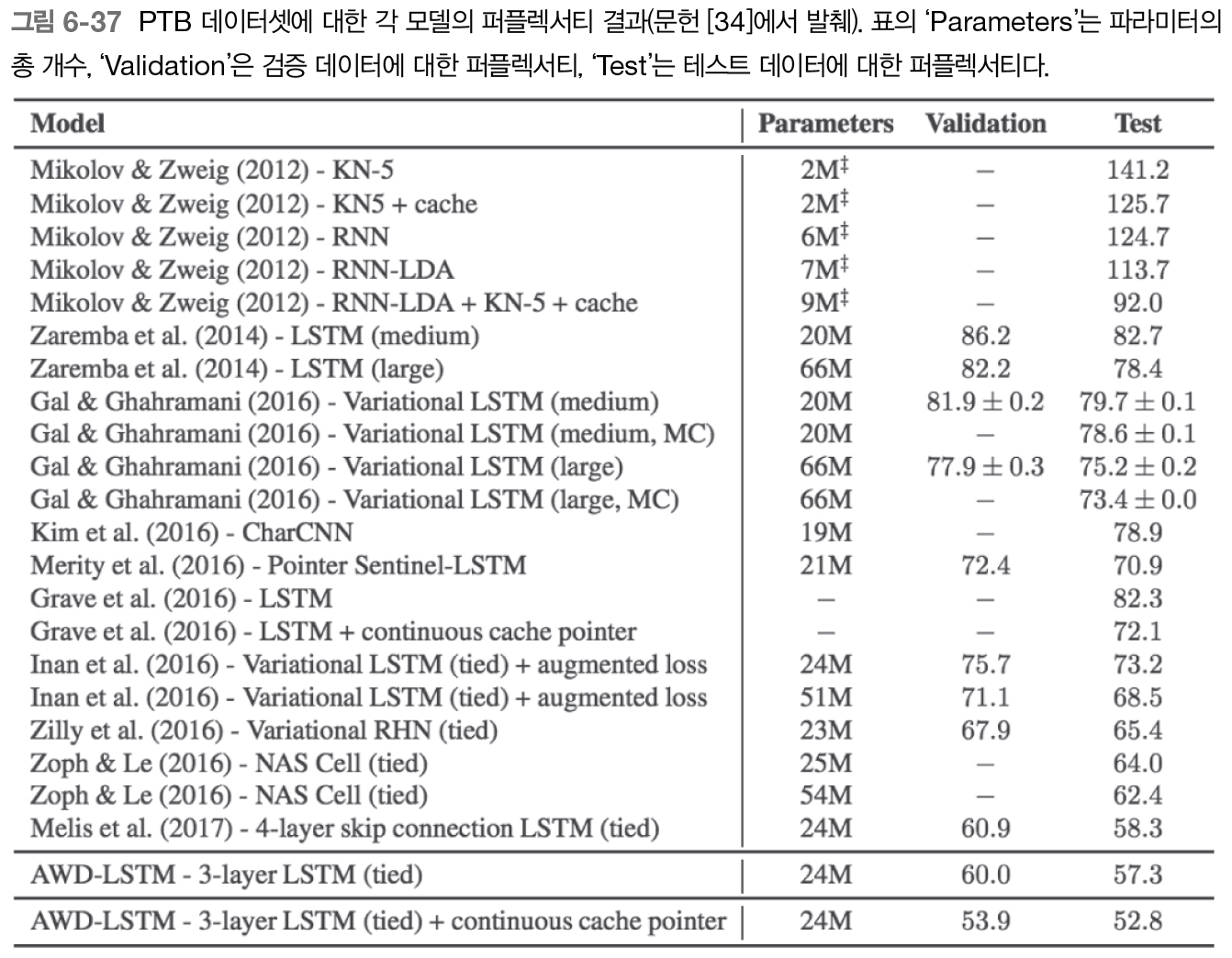
6.5.5 첨단 연구로

안녕하세요 ~ 게시글 잘 보았습니다! 6.1.3에서 질문이 있는데용~
"주의할 점은 행렬 곱셈에서 매번 똑같은 Wh 가중치를 쓴다는 것이다.
즉, 행렬 곱의 기울기는 시간에 비례해 지수적으로 증가/감소함을 알 수 있으며" 라고 되어 있는데 그러면 상류에서 흘러오는 기울기 dh가 시간에 비례하는 기울기인가요 ?