1. Array vs LinkedList
A. 특징
1) Array
- 특정 자료형들이 메모리공간상에서 연속적으로 이루어진다.
- Random Access가 가능하여 O(1)의 시간복잡도로 원소에 접근이 가능하다.
- 삭제나 삽입과정에서 작업을 완료한 뒤, shift 작업을 추가적으로 해야하므로 O(n)의 시간복잡도가 발생한다.
2) LinkedList
- 각 자료형의 노드들이 메모리공간 상에서 흩어져 있어서 노드에 접근 시, O(n)의 시간복잡도가 발생한다.
- 각 노드들은 자신의 전후 노드들의 위치만 알고있고, 사용자는 list의 처음 노드의 위치만 알고있는 형태이다.
- 삭제나 삽입과정 진행 시, 작업위치를 찾아서 진행해야하므로 O(n)의 시간복잡도가 발생한다.
B. 속도
1) 데이터 접근 속도
- Array >> LinkedList
2) 데이터 삽입 속도
- LinkedList > Array
- Array는 데이터가 많을수록 비효율적
- Array는 연속적으로 할당받아야할 메모리 공간이 부족하다면, 새로운 메모리 공간을 할당받아 이동해야 한다.
3) 데이터 삭제 속도
- LinkedList > Array
C. 기타
1) 메모리 할당
- Array는 Compiletime에 메모리할당이 이루어진다.
- LinkedList는 Runtime에 메모리할당이 이루어진다.
2. Stack and Queue
A. 특징
1) Stack
- LIFO(Last In First Out) 구조
- 시간복잡도 : O(n), 공간복잡도 : O(n)
- 함수의 콜 스택, 문자열 역순 출력, 후위표기법 등
2) Queue
- FIFO(First In First Out) 구조
- 시간복잡도 : O(n), 공간복잡도 : O(n)
- 버퍼, BFS탐색 등
3. Tree
A. 정의
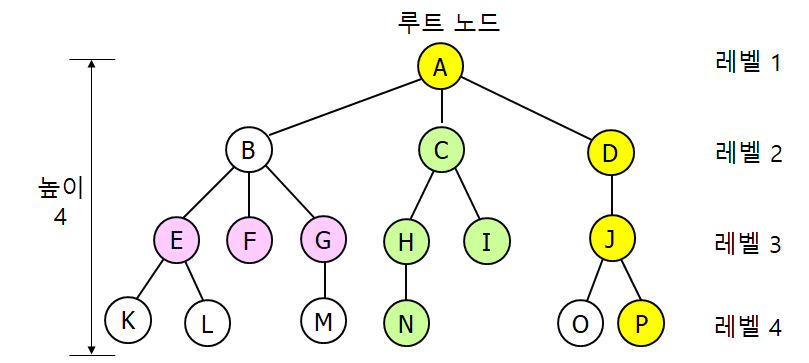
출처 : https://github.com/WooVictory/Ready-For-Tech-Interview/blob/master/Data%20Structure/%5BData%20Structure%5D%20Tree.md
- 노드(Node) : 트리를 구성하는 각각의 요소
- 엣지(Edge) : 노드와 노드를 연결하는 선
- 루트노드(Root Node) : 최상위의 노드
- 터미널노드(Terminal Node) : 자식노드가 없는 노드
- 인터널노드(Internal Node) : 터미널노드를 제외한 모든 노드
B. 특징
- 데이터 삽입이나 삭제 시, O(logN)의 시간복잡도가 발생한다. (Stack이나 Queue보다 빠름)
- 계층구조를 표현하는 데 적합하다.
- 루트 노드를 제외한 모든 노드는 단 하나의 부모 노드만을 가진다.
C. 이진탐색트리(BST, Binary Search Tree)
1) 정의
: 탐색이 빠른 장점을 가진 이진 탐색과 빠른 삽입과 삭제가 가능한 장점을 가진 연결리스트를 합쳐서 만든 자료구조
2) 시간복잡도
탐색 : O(logN), 삽입 및 삭제 : O(1)
3) 데이터 저장 규칙
- 왼쪽 서브트리 노드의 값들은 루트 노드의 값보다 항상 작다.
- 오른쪽 서브트리 노드의 값들은 루트 노드의 값보다 항상 크다.
- 서브트리는 모두 이진탐색트리이다.
4) 특징
- 중위순회 방식으로 순회한다. (왼쪽-루트-오른쪽)
=> 정렬된 순서를 읽을 수 있음 - 중복 노드가 있으면 안된다. (비효율적)
D. B Tree
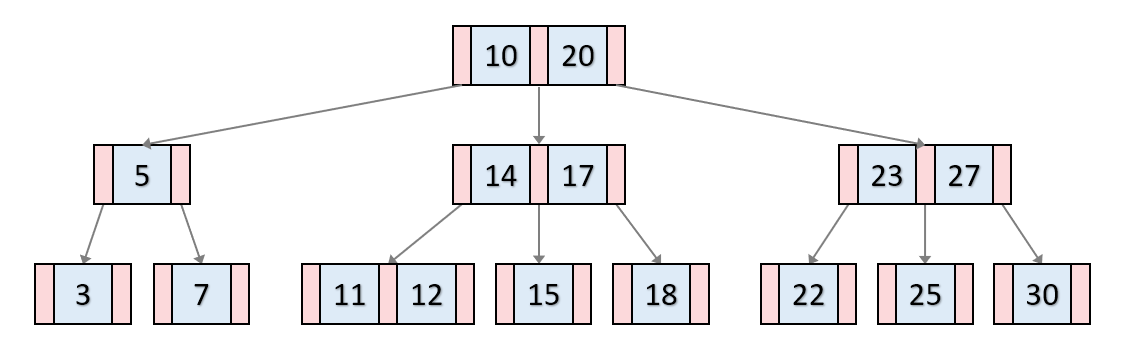
1) 정의
: 이진 트리를 확장해서 더 많은 자식노드를 가질 수 있게한 Tree
2) 특징
- 데이터베이스나 파일시스템에서 널리 사용되는 트리 자료구조이다. (블럭단위로 입출력하는 하드디스크 or SSD에 저장해야하기 때문(한 블럭당 2byte == 한 블럭당 1024byte, 똑같은 입출력 비용))
- 트리의 균형을 자동적으로 맞춰주는 로직이 포함되어 있다.
3) 규칙
- 노드의 키 갯수가 N이면, 자식 노드의 수는 N+1
- 각 노드의 키들은 정렬된 상태
- 루트 노드는 적어도 2개 이상의 자식을 가져야 한다.
- 외부 경로로 가는 경로의 길이는 모두 같다.
- 입력 자료는 중복될 수 없다.
- 모든 노드는 적어도 M/2개의 키를 가지고 있다.(M : 자식 노드의 수)
4) 참고
https://velog.io/@emplam27/자료구조-그림으로-알아보는-B-Tree
E. B+ Tree
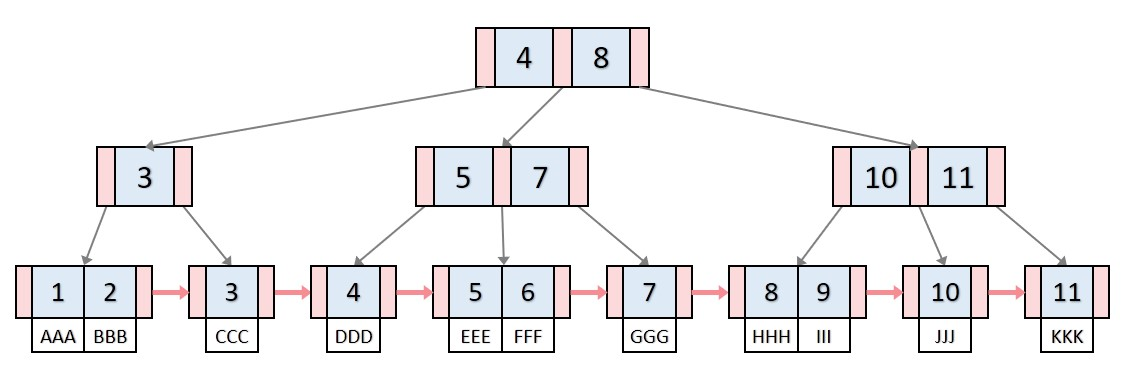
1) 정의
: 데이터에 빠른 접근을 위한 인덱스 노드를 B Tree에 추가한 Tree
2) 특징
- 모든 데이터는 leaf노드에 모여있다.
- 모든 leaf노드는 연결리스트 형태이다.
3) 참고
https://velog.io/@emplam27/자료구조-그림으로-알아보는-B-Plus-Tree
4. Hash
A. 정의
: 다양한 길이의 데이터를 고정된 길이의 데이터로 매핑한 값
- 해시함수 : 수학적 연산을 통해 고정된 길이의 데이터로 매핑하는 함수
- 해시코드(해시) : 해시함수에 의해 얻어지는 값
- 해시테이블 : 키와 값을 매핑해둔 데이터 구조. 해시로 얻은 키를 index로 활용하여 데이터(값)을 저장한다.
B. 문제
: 데이터가 많아지면 서로 다른 데이터라 할지라도 같은 해시 값을 가질 수 있다.
이를 충돌(Collision)이라고 한다.
- 그럼에도 해시를 쓰는 이유는 적은 자원으로 많은 데이터를 효율적으로 관리할 수 있기 때문이다.
C. 충돌 해결 방법
1) Separate Chaining
: key에 대한 index를 가리키는 자료구조로 linked-list를 활용하는 방법
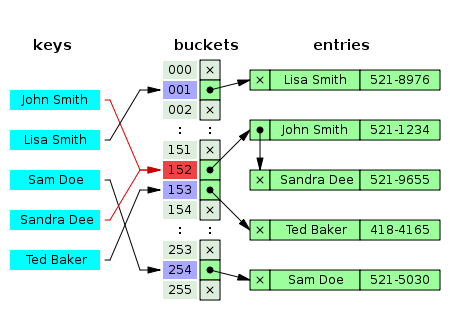
A) 특징
- 데이터를 검색할 때 선형으로 탐색하기 때문에 느리다는 단점이 있다.
(시간복잡도O(N)) => linked-list대신 트리를 이용하면 개선 가능
2) Open Addressing
: 충돌이 발생하면 해시 함수로 얻은 주소가 아닌 다른 주소 공간에 데이터를 저장하는 방식 (해당 키 값에 데이터가 저장되어 있다면, 다음 주소에 저장)
- 데이터 이동 방식
- 선형 탐사
: 현재 주소에서 고정 크기만큼 다음 주소로 이동하여 데이터를 저장한다. - 제곱 탐사
: 고정 크기만큼 이동하지 않고 이동 크기를 제곱수로 늘려나가는 방식이다. - 이중 해싱
: 다른 해시함수를 한번 더 적용한다. - 재해싱
: 해시 테이블의 크기를 늘리고, 늘어난 크기에 맞춰 다시 해시테이블을 구성하는 방식이다.
- Open Addressing 방식의 문제점
: 충돌이 일어난 기존 key값을 삭제하게 되면, 충돌이 일어난 다른 key값에 접근하지 못하게 됨 => 삭제 시에 더미노드를 추가하여 key값에 연결시켜주는 역할을 해줌
5. Heap
A. 정의
: Tree 형식으로 Tree 중에서 배열을 기반으로 한 완전이진트리이다.
B. 특징
- 최솟값 및 최댓값을 빠르게 찾아준다.
- 중복된 값을 허용한다.
- 배열을 이용하므로 Random Access가 가능하다.
- 구현의 용이함을 위해 배열의 0번째 index는 활용되지 않는다.
- 노드의 갯수가 n개일 때, i번째 노드에 대하여 왼쪽 자식은 ix2, 오른쪽 자식은 ix2+1이 된다.
