프로세스의 문제점
-
프로세스 생성의 오버헤드가 크다. (메모리 할당 -> fork() -> PCB -> Page(segment) mapping table -> ...)
-
Process context switching의 오버헤드가 크다.
-
프로세스간의 통신이 어렵다.
- 프로세스들은 완전히 독립적인 주소공간을 가져 서로 다른 프로세스끼리 개입이 불가하다.
- 프로세스간의 통신을 위해서는 별도의 방법(Shared memory, socket, message queue 등)이 필요하다.
이러한 프로세스의 문제점들을 보완하기 위해서 쓰레드가 등장했다.
쓰레드
- 프로세스보다 더 작은 실행단위
- 현대 운영체제가 작업을 스케줄링하는 단위
프로세스는 운영체제 작업단위, 쓰레드는 CPU 작업단위라고 생각할 수 있다. 쓰레드를 lighweight process라고 부르기도 한다.
쓰레드의 장점은 프로세스의 단점을 보완한 것으로 프로세스의 생성 및 소멸에 따른 오버헤드 감소, 빠른 Context swtiching, 손쉬운 통신이다.
특징
-
프로세스는 반드시 1개 이상의 쓰레드로 구성되어야 한다.
- 프로세스가 생성될 때 운영체제에 의해 자동으로 1개의 쓰레드가 생성된다. - 메인 쓰레드(main)
- 하나의 컨테이너가 여러개의 쓰레드를 가질 수 있다. - 멀티쓰레드
다른 쓰레드들은 함수를 쓰레드로 만들어줄 것을 요청하여 생성되고 각 쓰레드 별로 TCB(Thread control block)이 생성된다. 그리고 이 TCP는 PCB에 등록된다. 커널은 CPU 스케줄링 시 전체 TCB 중 하나를 선택하여 스레드를 실행시킨다.
-
프로세스는 쓰레드들의 공유 공간(환경)을 제공한다.
- 모든 쓰레드는 프로세스의 코드, 데이터, 힙을 공유한다. -> 쓰레드 사이 통신이 용이
- 단, '스택'은 쓰레드별로 별도의 공간을 사용한다.
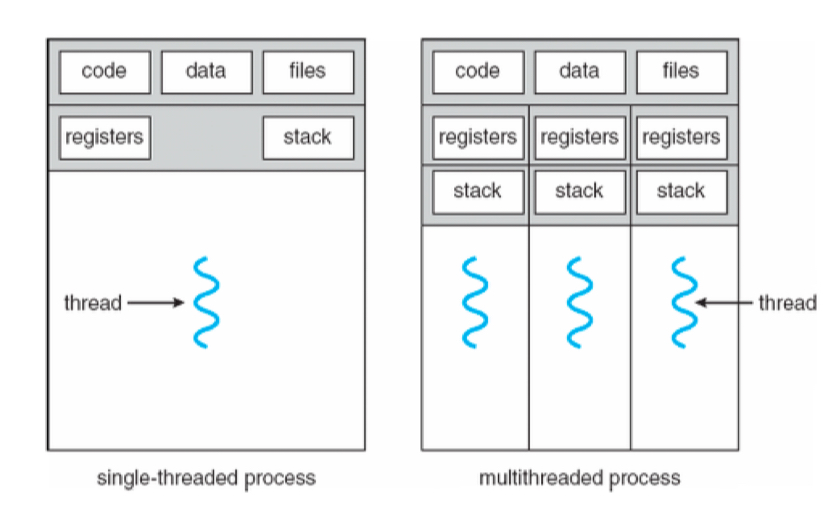
쓰레드의 생명과 프로세스의 생명
- 쓰레드로 만든 함수가 종료되면 쓰레드가 종료된다. (쓰레드가 종료되면 TCB 제거)
- 프로세스에 속한 모든 쓰레드가 종료될 때, 프로세스는 종료된다.
- 프로세스가 강제로 종료되면 쓰레드도 종료된다.
쓰레드 예제
다음 코드는 두 쓰레드가 있는데, 하나의 쓰레드는 공유 변수의 값을 1씩 증가시키고 다른 쓰레드는 공유 변수의 값을 1씩 감소시킨다. 하지만 쓰레드의 실행 순서가 보장되지 않아 공유자원(전역변수)의 합이 0이 되지 않는다. 이러한 쓰레드의 공유 자원 문제는 동기화가 필요하다.
#include <pthread.h>
#include <stdio.h>
#include <stdlib.h>
int sum = 0;
void* myThread1(void *p) {
printf("\t myThread 1 starts\n");
int *i = (int*)malloc(sizeof(int));
for (i = 0; i < (*(int*)p); i++) sum += 1;
return (void*)i;
}
void* myThread2(void *p) {
printf("\t myThread 2 starts \n");
int *i = (int*)malloc(sizeof(int));
for (i = 0; i < (*(int*)p); i++) sum -= 1;
return (void*)i;
}
int main() {
pthread_t tid1, tid2;
int count = 200000;
int *ret1, *ret2;
pthread_create(&tid1, NULL, myThread1, &count);
printf("myThread1's tid: %0X \n", (int)tid1);
pthread_create(&tid2, NULL, myThread2, &count);
printf("myThread2's tid: %0X \n", (int)tid2);
pthread_join(tid1, (void**)&ret1);
pthread_join(tid2, (void**)&ret2);
printf("myThreads have been finished \n");
printf("sum = %d\n", sum);
printf("ret1 = %d\n", (int)ret1);
printf("ret2 = %d\n", (int)ret2);
return 0;
}실행결과
myThread1's tid: 6B4BB000
myThread 2 starts
myThread 2 starts
myThread2's tid: 6B547000
myThreads have been finished
sum = -69786
ret1 = 200000
ret2 = 200000쓰레드 장단점
장점
- CPU 응답성 향상, 자원 공유, 효율성 향상, 다중 CPU 운용 용이
단점
- 모든 자원을 공유 -> 하나의 쓰레드가 잘못되면 프로세스 전체가 다 죽을 수 있다.
- 너무 많은 쓰레드 -> 너무 많은 Context swtiching이 발생한다.
쓰레드 주소공간
: 쓰레드가 생성되고 실행되는 동안 접근 가능한 메모리 영역
- 쓰레드 주소 공간은 프로세스 주소 공간 내에 형성된다.
- 일반 함수가 수직적인 관계라면, 쓰레드는 side-by-side 형태이다.
쓰레드 사적 공간
- 쓰레드 코드
- 쓰레드 로컬 스토리지(TLS, Thread local storage)
- 쓰레드 스택
쓰레드 사이의 공유 공간
- 프로세스의 코드
- 프로세스의 데이터 공간(로컬 스토리지 제외)
- 프로세스의 힙 영역
다음 코드에서 gsum은 전역변수로 공유되기 때문에 실행시마다 동일한 값을 보장하지 못하는 반변, tsum은 쓰레드 로컬 스토리지로 쓰레드마다 고유하기 때문에 동기화를 하지 않아도 안전하게 사용할 수 있다.
#include <pthread.h>
#include <stdio.h>
#include <stdlib.h>
int gsum = 0;
int __thread tsum = 1;
void func(int a) {
printf("5_%d. gsum= %d \ tsum= %d \n", a, gsum, tsum);
int b = a + 10;
gsum += b;
tsum += b;
printf("6_%d. gsum=%d \ tsum= %d \n", a, gsum, tsum);
}
void* myThread(void *p) {
int a = (*(int*)p);
printf("2_%d. gsum= %d / tsum= %d \n", a, gsum, tsum);
for (int i = 0; i < 30000000/a; i++)
gsum += a;
tsum += a;
printf("3_%d. gsum= %d / tsum= %d \n", a, gsum, tsum);
func(a);
printf("7_%d. gsum= %d \ tsum= %d \n", a, gsum, tsum);
}
int main() {
pthread_t tid[2];
int arg[2] = {1000, 3000};
printf("1_main. gsum= %d / tsum= %d \n", gsum, tsum);
pthread_create(&tid[0], NULL, myThread, &arg[0]);
pthread_create(&tid[1], NULL, myThread, &arg[1]);
pthread_join(tid[0], NULL);
pthread_join(tid[1], NULL);
printf("8_main. gsum= %d / tsum= %d \n", gsum, tsum);
return 0;
}실행 결과
1_main. gsum= 0 / tsum= 1
2_3000. gsum= 0 / tsum= 1
2_1000. gsum= 0 / tsum= 1
3_3000. gsum= 30000000 / tsum= 3001
5_3000. gsum= 22514000 tsum= 3001
6_3000. gsum=23101010 tsum= 6011
7_3000. gsum= 23624000 tsum= 6011
3_1000. gsum= 46698000 / tsum= 1001
5_1000. gsum= 46698000 tsum= 1001
6_1000. gsum=46699010 tsum= 2011
7_1000. gsum= 46699010 tsum= 2011
8_main. gsum= 46699010 / tsum= 1 쓰레드 라이프 사이클
- 준비 상태(Ready) - 쓰레드가 스케줄되기를 기다리는 상태
- 실행 상태(Running) - 쓰레드가 CPU에 의해 실행중인 상태
- 대기 상태(Blocking) - 쓰레드가 입출력을 요청하거나 sleep()과 같은 시스템 호출로 인해 커널에 의해 중단된 상태
- 종료 상태(Terminated) - 쓰레드가 종료한 상태
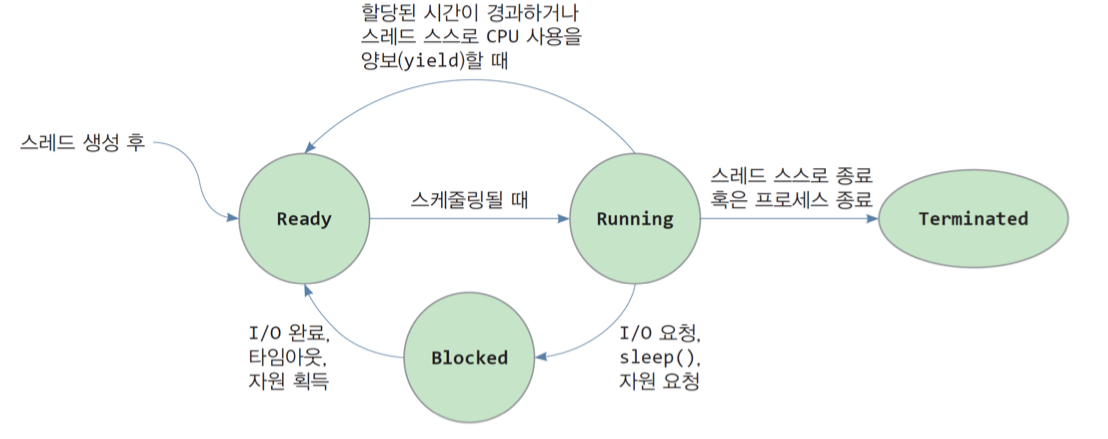
Thread operation
쓰레드 생성
- 쓰레드는 쓰레드를 생성하는 시스템 호출이나 라이브러리 함수를 호출하여 생성할 수 있다. (
pthread_create) - 프로세스가 생성되면 자동으로 main 쓰레드가 생성된다.
쓰레드 종료 (vs 프로세스 종료)
pthread_exit()과 같이 쓰레드만 종료하는 함수 호출 시 해당 쓰레드만 종료- main() 함수에서
pthread_exit()을 부르면 역시 main 쓰레드만 종료
<-> 프로세스 종료
- 프로세스에 속한 어떤 쓰레드라도 exit() 시스템 호출을 부르면 프로세스 종료 (모든 쓰레드 종료)
- 메인 쓰레드의 종료 (C 프로그램에서 main() 함수 종료) -> 모든 쓰레드도 함께 종료
- 모든 쓰레드가 종료하면 프로세스 종료
쓰레드 조인(join)
- 쓰레드가 다른 쓰레드 종료할 때까지 대기 (주로 부모 쓰레드가 자식 쓰레드의 종료 대기)
쓰레드 양보 (yield)
- 쓰레드가 자발적으로
yield()와 같은 함수 호출을 통해 자신의 실행을 중단하고 다른 쓰레드를 스케줄하도록 지시
Thread context - TCB
TCB(Thread control block)
- 쓰레드가 생성될 때 커널에 의해 만들어지고 쓰레드의 실행 중인 상태 정보들은 TCB에 저장된다. 쓰레드가 소멸되면 함께 사라진다.
- 각종 CPU 레지스터들의 값을 관리한다.
- PC - 실행 중인 코드 주소
- SP/BP - 실행 중인 함수의 스택 주소
- Flag - 현재 CPU의 상태 정보
- etc ...
- 나머지 메모리들은 공유하기 때문에 레지스터들만 저장해두었다가 필요할 때 CPU에 복귀하면 이전에 실행하던 상태로 돌아갈 수 있다.
Thread context switching
현재 실행 중인 쓰레드를 중단시키고, 다른 쓰레드들에게 CPU를 할당한다. 현재 CPU 컨텍스트를 TCB에 저장하고 다른 TCB에 저장된 컨텍스트를 CPU에 적재한다.
-
CPU 레지스터 저장 및 복귀
- 현재 실행 중인 쓰레드 A의 컨텍스트를 TCB-A에 저장
- TCB-B에 저장된 쓰레드 B의 컨텍스트를 CPU에 적재
- CPU는 쓰레드 B가 이전에 중단된 위치에서 실행 재개 가능
- SP 레지스터를 복귀함으로써 자신의 이전 스택을 되찾게 된다.
- 스택에는 이전 중단될 때 실행하던 함수의 매개변수나 지역변수들이 그대로 저장되어 있다.
-
커널 정보 수정
- TCB-A와 TCB-B에 쓰레드 상태 정보와 CPU 사용 시간 등 수정
- TCB-A를 준비 리스트나 블록 리스트로 옮김
- TCB-B를 준비 리스트에서 분리
Overhead in context switching
Context switching은 상당히 비싼 연산 중 하나이다. Context switching의 시간이 길거나 잦은 경우 컴퓨터 처리율이 심각하게 저하될 수 있다.
동일한 프로세스의 다른 쓰레드로 스위칭되는 경우
- 컨텍스트 저장 및 복귀 (현재 CPU의 컨텍스트(PC, PSP, 레지스터) TCB에 저장, TCB로부터 쓰레드 컨텍스트를 CPU에 복귀)
- TCB 리스트 조작
- 캐시 Flush와 채우기 시간
다른 프로세스의 쓰레드로 스위칭하는 경우
(다른 프로세스로 교체되면, CPU가 실행하는 주소 공간이 바뀌는 큰 변화로 인한 추가적인 오버헤드가 발생한다.)
- 추가적인 메모리 오버헤드 - 시스템 내에 현재 실행 중인 프로세스의 매핑 테이블을 새로운 프로세스의 매핑 테이블로 교체
- 추가적인 캐시 오버헤드
- 프로세스가 바뀌기 때문에, CPU 캐시에 담긴 코드와 데이터 무력화
- 새 프로세스의 쓰레드가 실행을 시작하면 CPU 캐시 미스 발생, 캐시가 채워지는데 상당한 시간 소요
쓰레드 모델
쓰레드 종류
- Kernel-level thread - 운영체제가 커널에서 관리하는 쓰레드
- User-level thread - User-space에서 관리하는 쓰레드
Kernel-level thread
커널 쓰레드: 커널이 직접 생성하고 관리하는 쓰레드
- 응용 프로그램이 시스템 호출을 통해 커널 레벨 쓰레드 생성
- 커널이 쓰레드에 대한 정보(TCB)를 커널 공간에 생성하고 소유 -> 커널에 의해 스케줄
- 쓰레드 주소 공간(쓰레드 코드와 데이터)은 사용자 공간에 존재
- main 쓰레드는 커널 쓰레드 (응용 프로그램이 적재되어 프로세스가 생성될 때 자동으로 커널은 main 쓰레드 생성)
순수 커널 레벨 쓰레드(pure kernel-level thread)
- 부팅 때부터 커널의 기능을 돕기 위해 만들어진 쓰레드
- 커널 코드를 실행하는 커널 쓰레드
- 쓰레드의 주소 공간은 모두 커널 공간에 형성
- 커널 모드에서 작동, 사용자 모드에서 실행되는 일은 없음
User-level thread
사용자 쓰레드: 라이브러리에 의해 구현된 일반적인 쓰레드
- 응용 프로그램이 라이브러리 함수를 호출하여 사용자 레벨 쓰레드 생성
- 쓰레드 라이브러리가 쓰레드 정보(U-TCB)를 사용자 공간에 생성하고 소유 (쓰레드 라이브러리는 사용자 공간에 존재하고 사용자 쓰레드는 쓰레드 라이브러리에 의해 스케줄된다.)
- 커널은 사용자 레벨 쓰레드의 존재에 대해 알 수 없다. -> 하나의 프로세스로만 인식
- 쓰레드 주소 공간(쓰레드 코드와 데이터)는 사용자 공간에 존재한다.
Mutlithreading models
멀티쓰레드의 구현 - 응용 프로그램에서 작성한 쓰레드가 시스템에서 실행되도록 구현하는 방법
- 사용자가 만든 쓰레드가 시스템에서 스케줄되고 실행되도록 구현하는 방법
- 쓰레드 라이브러리와 커널의 시스템 호출의 상호 협력 필요
Many-to-One 'N:1' model - N개의 사용자 레벨 쓰레드를 1개의 커널 쓰레드로 매핑
One-to-One '1:1" model - 1개의 사용자 레벨 쓰레드를 1개의 커널 레벨 쓰레드로 매핑
Many-to-Many 'N:M' model - N개의 사용자 레벨 쓰레드를 M개의 커널 레벨 쓰레드로 매핑
