
Spring Batch 실습
Spring batch를 이용하여 주문내역을 관리해보자
🍖실습 프로젝트 경로
- Part4~6 내용
회원 등급 프로젝트
- User 등급을 4개로 구분
- 일반(NORMAL), 실버(SILVER), 골드(GOLD), VIP
Level Enum생성
- 일반(NORMAL), 실버(SILVER), 골드(GOLD), VIP
- User 등급 상향 조건은 총 주문 금액 기준으로 등급 상향
- 200,000원 이상인 경우 실버로 상향
- 300,000원 이상인 경우 골드로 상향
- 500,000원 이상인 경우 VIP로 상향
- 등급 하향은 없음
- 총 2개의 Step으로 회원 등급 Job 생성
- saveUserStep : User 데이터 저장
@RequiredArgsConstructor public class SaveUsersTasklet implements Tasklet { private final int SIZE = 10_000; private final UsersRepository usersRepository; @Override public RepeatStatus execute(StepContribution contribution, ChunkContext chunkContext) throws Exception { List<Users> users = createUsers(); Collections.shuffle(users); usersRepository.saveAll(users); return RepeatStatus.FINISHED; } private List<Users> createUsers(){ List<Users> users = new ArrayList<>(); for (int i = 0; i < SIZE; i++) { users.add(Users.builder() .orders(Collections.singletonList(Orders.builder() .price(1_000) .createdDate(LocalDate.of(2023, 1, 1)) .itemName("item " + i) .build())) .name("test username " + i) .build()); } for (int i = 0; i < SIZE; i++) { users.add(Users.builder() .orders(Collections.singletonList(Orders.builder() .price(200_000) .createdDate(LocalDate.of(2023, 1, 2)) .itemName("item " + i) .build())) .name("test username " + i) .build()); } for (int i = 0; i < SIZE; i++) { users.add(Users.builder() .orders(Collections.singletonList(Orders.builder() .price(300_000) .createdDate(LocalDate.of(2023, 1, 3)) .itemName("item " + i) .build())) .name("test username " + i) .build()); } for (int i = 0; i < SIZE; i++) { users.add(Users.builder() .orders(Collections.singletonList(Orders.builder() .price(500_000) .createdDate(LocalDate.of(2023, 1, 4)) .itemName("item " + i) .build())) .name("test username " + i) .build()); } return users; } }SaveUsersTasklet를 통해 40,000개의 User data 생성@Bean(JOB_NAME + "_saveUserStep") public Step saveUserStep() { return this.stepBuilderFactory.get(JOB_NAME + "_saveUserStep") .tasklet(new SaveUsersTasklet(usersRepository)) .build(); }saveUserStep생성 - userLevelUpStep : User 등급 상향
@Bean(JOB_NAME + "_userLevelUpStep") public Step userLevelUpStep() throws Exception { return this.stepBuilderFactory.get(JOB_NAME + "_userLevelUpStep") .<Users, Users>chunk(CHUNK_SIZE) .reader(this.loadUsersData()) .processor(this.checkUsersData()) .writer(this.fixUsersGradeData()) .build(); } // ItemReader private ItemReader<? extends Users> loadUsersData() throws Exception { JpaPagingItemReader<Users> jpaPagingItemReader = new JpaPagingItemReaderBuilder<Users>() .name(JOB_NAME + "_loadUsersData") .entityManagerFactory(entityManagerFactory) .pageSize(CHUNK_SIZE) .queryString("select u from Users u") .build(); jpaPagingItemReader.afterPropertiesSet(); return jpaPagingItemReader; } // ItemProcessor private ItemProcessor<? super Users, ? extends Users> checkUsersData() { return user -> { if (user.availableLevelUp()) return user; return null; }; } // ItemWriter private ItemWriter<? super Users> fixUsersGradeData() throws Exception { return users -> users.forEach(user -> { user.levelUp(); usersRepository.save(user); }); }
- saveUserStep : User 데이터 저장
- JobExecutionListener.afterJob 메소드에서 “총 데이터 처리 {}건, 처리 시간 : {}millis” 와 같은 로그 출력
@Slf4j @RequiredArgsConstructor public class UsersItemListener { private final UsersRepository usersRepository; @AfterJob public void showJobResult(JobExecution jobExecution){ Collection<Object> users = usersRepository.findAllByUpdatedDate(LocalDate.now()); Date startTime = jobExecution.getStartTime(); Date endTime = jobExecution.getEndTime(); long totalTime = endTime.getTime() - startTime.getTime(); log.info("총 데이터 처리 {}건, 처리 시간 : {}millis", users.size(), totalTime); } } - User의 totalAmount를 Orders Entity로 변경
- 하나의 User는 N개의 Orders를 포함
- 주문 총 금액은 Orders Entity를 기준으로 합산
// Users Class의 Orders 연관관계 설정 @OneToMany(cascade = CascadeType.PERSIST, fetch = FetchType.EAGER) @JoinColumn(name = "users_id") private List<Orders> orders = new ArrayList<>(); // Users의 주문 총 금액 합산 Method private int getTotalAmount(){ return this.orders.stream().mapToInt(Orders::getPrice).sum(); } date=2023-02JobParameters 사용- 주문 금액 집계는 orderStatisticsStep으로 생성
2023년_2월_주문_금액.csv파일은 2023년 2월 1일 ~ 말일 주문 통계 내역
- orderStatisticsStep Class
@Getter @Builder public class OrderStatistics { private String amount; private LocalDate date; }
- 주문 금액 집계는 orderStatisticsStep으로 생성
date파라미터가 없는 경우, orderStatisticsStep은 실행하지 않는다.
OrderStatisticsStep의 생성
// orderStatisticsStep 생성
@Bean(JOB_NAME + "_orderStatisticsStep")
@JobScope
public Step orderStatisticsStep(@Value("#{jobParameters[date]}") String date,
@Value("#{jobParameters[path]}") String path) throws Exception {
return this.stepBuilderFactory.get(JOB_NAME + "_orderStatisticsStep")
.<OrderStatistics, OrderStatistics>chunk(CHUNK_SIZE)
.reader(orderStatisticsReader(date))
.writer(orderStatisticsWriter(date, path))
.build();
}
// orderStatisticsStep ItemReader
private ItemReader<? extends OrderStatistics> orderStatisticsReader(String date) throws Exception {
YearMonth yearMonth = YearMonth.parse(date);
Map<String, Object> parameters = new HashMap<>();
parameters.put("startDate", yearMonth.atDay(1));
parameters.put("endDate", yearMonth.atEndOfMonth());
Map<String, Order> sortKey = new HashMap<>();
sortKey.put("created_date", Order.ASCENDING);
JdbcPagingItemReader<OrderStatistics> itemReader = new JdbcPagingItemReaderBuilder<OrderStatistics>()
.name(JOB_NAME + "_orderStatisticsReader")
.dataSource(dataSource)
.rowMapper((rs, rowNum) -> OrderStatistics.builder()
.amount(rs.getString(1))
.date(LocalDate.parse(rs.getString(2), DateTimeFormatter.ISO_DATE))
.build())
.pageSize(CHUNK_SIZE)
.selectClause("sum(price) as amount, created_date")
.fromClause("orders")
.whereClause("created_date >= :startDate and created_date <= :endDate")
.groupClause("created_date")
.parameterValues(parameters)
.sortKeys(sortKey)
.build();
itemReader.afterPropertiesSet();
return itemReader;
}
// orderStatisticsStep ItemWriter
private ItemWriter<? super OrderStatistics> orderStatisticsWriter(String date, String path) throws Exception {
YearMonth yearMonth = YearMonth.parse(date);
String fileName = yearMonth.getYear() + "년_" + yearMonth.getMonthValue() + "월_일별_주문_금액.csv";
BeanWrapperFieldExtractor<OrderStatistics> fieldExtractor = new BeanWrapperFieldExtractor<>();
fieldExtractor.setNames(new String[]{"amount", "date"});
DelimitedLineAggregator<OrderStatistics> lineAggregator = new DelimitedLineAggregator<>();
lineAggregator.setDelimiter(", ");
lineAggregator.setFieldExtractor(fieldExtractor);
FlatFileItemWriter<OrderStatistics> fileItemWriter = new FlatFileItemWriterBuilder<OrderStatistics>()
.name(JOB_NAME + "_orderStatisticsWriter")
.encoding("UTF-8")
.resource(new FileSystemResource(path + fileName))
.lineAggregator(lineAggregator)
.headerCallback(writer -> writer.write("총액, 날짜"))
.append(false)
.build();
fileItemWriter.afterPropertiesSet();
return fileItemWriter;
}JobParameterDecide 생성
JobParameter에 date 변수가 들어왔는지 확인하기 위한 JobExecutionDecider class 생성
public class JobParametersDecide implements JobExecutionDecider {
public static final FlowExecutionStatus CONTINUE = new FlowExecutionStatus("CONTINUE");
public final String key;
public JobParametersDecide(String key) {
this.key = key;
}
@Override
public FlowExecutionStatus decide(JobExecution jobExecution, StepExecution stepExecution) {
String value = jobExecution.getJobParameters().getString(key);
if (StringUtils.isEmpty(value))
return FlowExecutionStatus.COMPLETED;
return CONTINUE;
}
}최종 Job 등록 형태
@Bean(JOB_NAME)
public Job usersGradeJob() throws Exception {
return this.jobBuilderFactory.get(JOB_NAME)
.incrementer(new RunIdIncrementer())
.start(this.saveUserStep())
.next(this.userLevelUpStep())
.listener(new UsersItemListener(usersRepository))
.next(new JobParametersDecide("date"))
.on(JobParametersDecide.CONTINUE.getName())
.to(this.orderStatisticsStep(null))
.build()
.build();
}start: saveUserStep()을 이용하여 Users 더미데이터 저장next: userLevelUpStep()을 이용하여 Users의 Level 업데이트- 결과 보고를 위한
listener등록 next: dateJobParameter이 들어왔는지 확인on: 변수가 입력되어CONTINUE가 리턴되면 계속하여 진행to:CONTINUE된 경우 주문내역 생성
성능 개선 및 성능 비교
SaveUserTasklet에서 User 40,000건 저장, Chunk Size는 1,000- 성능 개선 대상 Step은
userLevelUpStep
| 1회 | 2회 | 3회 | |
|---|---|---|---|
| Simple Step | 11519 | 11157 | 12822 |
| Async Step | 11015 | 13581 | 11091 |
| Multi-Thread Step | 10303 | 8769 | 10127 |
| Partition Step | 8359 | 9034 | 7898 |
| Async+Partition Step | 9518 | 10127 | 8094 |
| Parallel Step | 10550 | 10933 | 10346 |
| Partition+Parallel Step | 8303 | 10156 | 8792 |
Async+Partiton, Partition+Parallel은 Git에서 확인 가능
TaskExecutor bean 수정
앞으로 성능 개선에 사용되는 TaskExecutor bean 수정을 위하여 main을 아래와 같이 수정
@EnableBatchProcessing
@SpringBootApplication
public class SpringBatchApplication {
public static void main(String[] args) {
System.exit(SpringApplication.exit(
SpringApplication.run(SpringBatchApplication.class, args)
));
}
@Bean
@Primary
TaskExecutor taskExecutor(){
ThreadPoolTaskExecutor taskExecutor = new ThreadPoolTaskExecutor();
taskExecutor.setCorePoolSize(10);
taskExecutor.setMaxPoolSize(20);
taskExecutor.setThreadNamePrefix("batch-thread-");
taskExecutor.initialize();
return taskExecutor;
}
}Async Step 적용하기
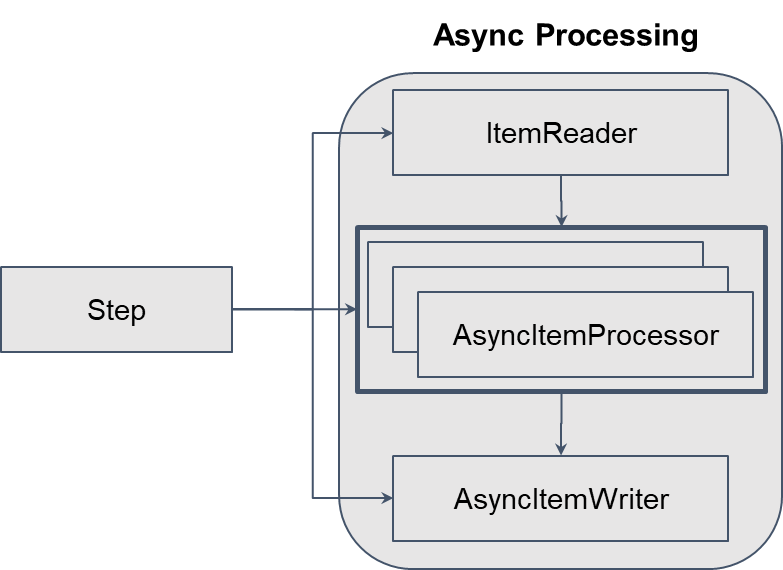
- ItemProcessor와 ItemWriter를 Async로 실행
java.util.concurrent에서 제공되는Future기반 asynchronous- Async를 사용하기 위해 spring-batch-integration dependency 필요
implementation 'org.springframework.batch:spring-batch-integration' // AsyncuserLevelUpStep의ItemProcessor와ItemWriter을AsyncItemProcessor와AsyncItemWriter로 수정
private AsyncItemProcessor<Users, Users> itemProcessor() {
ItemProcessor<Users, Users> itemProcessor = user -> {
if (user.availableLevelUp())
return user;
return null;
};
AsyncItemProcessor<Users, Users> asyncItemProcessor = new AsyncItemProcessor<>();
asyncItemProcessor.setDelegate(itemProcessor);
asyncItemProcessor.setTaskExecutor(this.taskExecutor);
return asyncItemProcessor;
}
private AsyncItemWriter<Users> itemWriter() throws Exception {
ItemWriter<Users> itemWriter = users -> users.forEach(user -> {
user.levelUp();
usersRepository.save(user);
});
AsyncItemWriter<Users> asyncItemWriter = new AsyncItemWriter<>();
asyncItemWriter.setDelegate(itemWriter);
return asyncItemWriter;
}userLevelUpStep()의<Users, Users>chunk를<Users, Future<Users>>chunk로 수정해준다.
Multi-Thread Step 적용하기
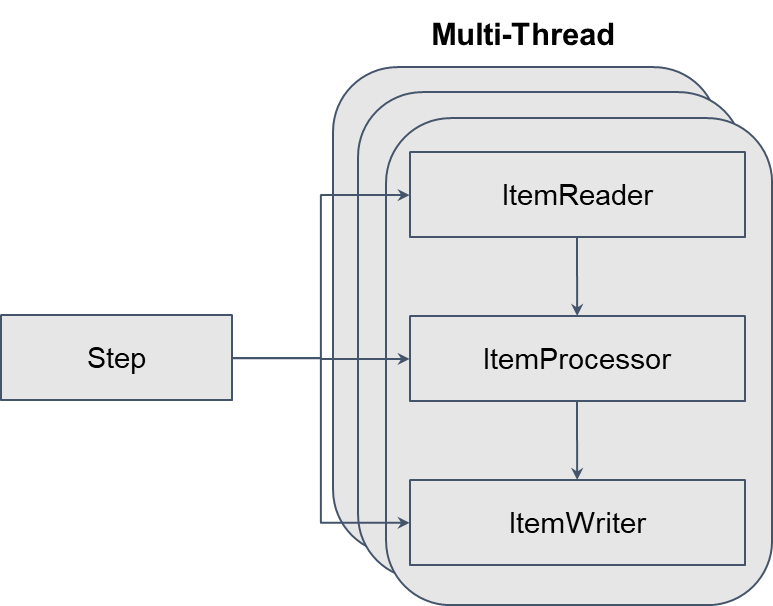
Multi-Thread는 비교적 간단하게 적용 가능하다.
- Async Step은 ItemProcessor와 ItemWriter 기준으로 비동기 처리
- Multi-Thread는 Step의 Chunk 단위로 멀티 스레딩 처리
- Thread-Safe한 ItemReader 필수
@Bean(JOB_NAME + "_userLevelUpStep")
public Step userLevelUpStep() throws Exception {
return this.stepBuilderFactory.get(JOB_NAME + "_userLevelUpStep")
.<Users, Users>chunk(CHUNK_SIZE)
.reader(this.loadUsersData())
.processor(this.checkUsersData())
.writer(this.fixUsersGradeData())
.taskExecutor(this.taskExecutor) // multi thread 를 위해 추가
.throttleLimit(8) // 8개의 thread로 chunk를 동시 처리 (default는 4개)
.build();
}- Step에서
taskExecutor와throtteleLimit만 설정해주면 사용할 수 있다.throttleLimit은 동시에 사용할 thread의 개수이다. (default: 4개)
Partition Step 적용하기

- 하나의
Master기준으로 여러SlaveStep을 생성해 Step 기준으로 Multi-Thread 처리 - 예를 들어
- item이 40,000개, Slave Step이 8개면
- 40,000/8=5,000 이므로 Slave Step 당 5,000건 씩 나눠서 처리
- Slave Step은 각각 하나의 Step으로 동작
Partitioner Class 생성
Partition Step을 적용하기 위해서는 각 Slave Step당 몇 건 씩을 처리해야하는지 지정해주는 클래스가 필요하다.
유저의 min id와 max id를 불러와 동일한 개수의 item을 할당해주는 클래스 생성
public class UserLevelUpPartitioner implements Partitioner {
private final UsersRepository usersRepository;
public UserLevelUpPartitioner(UsersRepository usersRepository) {
this.usersRepository = usersRepository;
}
@Override
public Map<String, ExecutionContext> partition(int gridSize) {
int minId = usersRepository.findMinId(); // 1
int maxId = usersRepository.findMaxId(); // 40_000
int targetSize = (maxId - minId) / gridSize + 1; // 5000
/**
* ExecutionContext 생성
* partition0 : 1, 5_000
* partition1 : 5_001, 10_000
* ~~~
*/
Map<String, ExecutionContext> result = new HashMap<>();
int number = 0;
int start = minId;
int end = start + targetSize -1;
while (start <= maxId){
ExecutionContext value = new ExecutionContext();
result.put("partition"+number, value);
if (end > maxId)
end = maxId;
value.putLong("minId", start);
value.putLong("maxId", end);
start += targetSize;
end += targetSize;
number += 1;
}
return result;
}
}- Master Step 생성
@Bean(JOB_NAME + "_userLevelUpStep.manager")
public Step userLevelUpManagerStep() throws Exception {
return this.stepBuilderFactory.get(JOB_NAME + "_userLevelUpStep.manager")
.partitioner(JOB_NAME + "_userLevelUpStep", new UserLevelUpPartitioner(usersRepository))
.step(this.userLevelUpStep())
.partitionHandler(this.taskExecutorPartitionHandler())
.build();
}- PartitionHandler Method 생성
- taskExecutor와 Slave Step의 개수 지정
@Bean(JOB_NAME + "_taskExecutorPartitionHandler")
public PartitionHandler taskExecutorPartitionHandler() throws Exception {
TaskExecutorPartitionHandler handler = new TaskExecutorPartitionHandler();
handler.setStep(this.userLevelUpStep());
handler.setTaskExecutor(this.taskExecutor);
handler.setGridSize(8);
return handler;
}- ItemReader Method 수정
- minId ~ maxId 사이의 유저를 불러오기 위하여 수정
- ItemReader Interface 대신
JpaPagingItemReader와 같은 보다 직접적인 클래스 사용 필요 stepExecutionContext를 통하여 minId, maxId를 불러오기 때문에@StepScope의 등록이 필요하다.
@Bean(JOB_NAME + "_jpaItemReader")
@StepScope
public JpaPagingItemReader<? extends Users> itemReader(@Value("#{stepExecutionContext[minId]}") Integer minId,
@Value("#{stepExecutionContext[maxId]}") Integer maxId) throws Exception {
Map<String, Object> parameters = new HashMap<>();
parameters.put("minId", minId);
parameters.put("maxId", maxId);
JpaPagingItemReader<Users> jpaPagingItemReader = new JpaPagingItemReaderBuilder<Users>()
.name(JOB_NAME + "_loadUsersData")
.entityManagerFactory(entityManagerFactory)
.pageSize(CHUNK_SIZE)
.queryString("select u from Users u where u.id between :minId and :maxId")
.parameterValues(parameters)
.build();
jpaPagingItemReader.afterPropertiesSet();
return jpaPagingItemReader;
}Parallel Step 적용하기
- n개의 Thread가 Step 단위로 동시에 실행
- Multi-Thread Step은 chunk 단위로 동시에 실행되었다면, Parallel Step은 Step 단위로 동시에 실행
- 아래 그림을 예로 들면
- Job은 FlowStep1과 FlowStep2를 순차 실행
- FlowStep2는 Step2와 Step3를 동시 실행
- 설정에 따라 FlowStep1과 FlowStep2를 동시 실행도 가능하다.
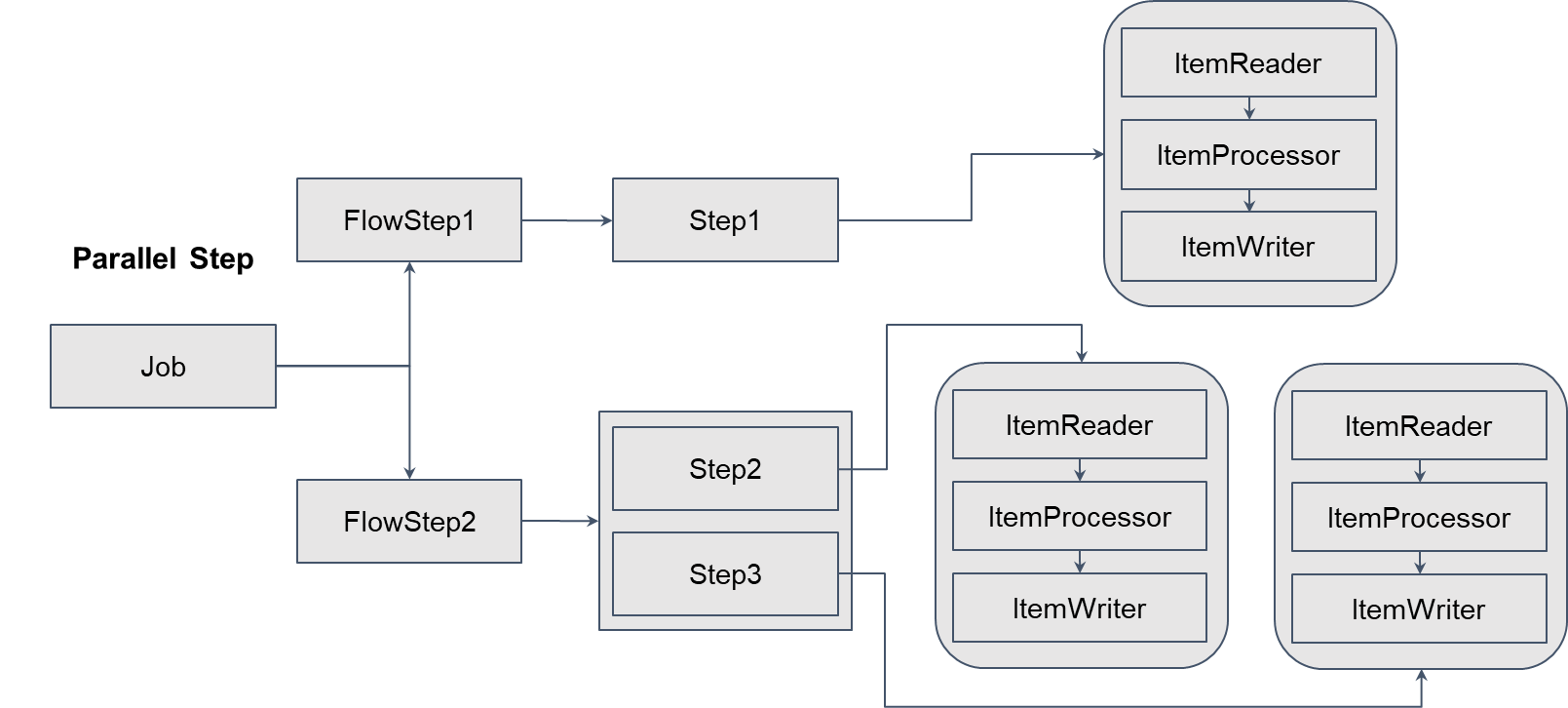
saveUserStep을 실행하는saveUserFlow생성 및userLevelUpStep및orderStatisticsStep을 동시에 실행하는splitFlow생성
@Bean(JOB_NAME + "_saveUserFlow")
public Flow saveUserFlow() {
TaskletStep saveUserStep = this.stepBuilderFactory.get(JOB_NAME + "_saveUserStep")
.tasklet(new SaveUsersTasklet(usersRepository))
.build();
return new FlowBuilder<SimpleFlow>(JOB_NAME + "_saveUserFlow")
.start(saveUserStep)
.build();
}
@Bean(JOB_NAME+"_splitFlow")
@JobScope
public Flow splitFlow(@Value("#{jobParameters[date]}") String date) throws Exception {
Flow userLevelUpFlow = new FlowBuilder<SimpleFlow>(JOB_NAME + "_userLevelUpFlow")
.start(userLevelUpStep())
.build();
return new FlowBuilder<SimpleFlow>(JOB_NAME + "_splitFlow")
.split(this.taskExecutor)
.add(userLevelUpFlow, orderStatisticsFlow(date))
.build();
}
private Flow orderStatisticsFlow(String date) throws Exception {
return new FlowBuilder<SimpleFlow>(JOB_NAME+"_orderStatisticsFlow")
.start(new JobParametersDecide("date"))
.on(JobParametersDecide.CONTINUE.getName())
.to(this.orderStatisticsStep(date))
.build();
}- Job에 Flow 등록
@Bean(JOB_NAME)
public Job usersGradeJob() throws Exception {
return this.jobBuilderFactory.get(JOB_NAME)
.incrementer(new RunIdIncrementer())
.listener(new UsersItemListener(usersRepository))
.start(this.saveUserFlow())
.next(this.splitFlow(null))
.build()
.build();
}
같이 공부합시다~